
哈希表在 MySQL 里有如下应用:
各种存储引擎的哈希索引存储。MySQL 的 Memory,NDB 都有哈希索引的具体实现; MySQL 内部生成的哈希表。比如: 数据在 innodb buffer pool 里的快速查找; 子查询的物化自动加哈希索引; JOIN KEY 无 INDEX 下的 HASH JOIN 等。
一、哈希数据分布
哈希索引显式应用主要存在于内存表,也就是 Memory 引擎,或者是 MySQL 8.0 的 Temptable 引擎。本篇的内容上都是基于内存表,MySQL 内存表的大小由参数 max_heap_table_size 来控制,其中包含了表数据,索引数据等。
举个例子,表 t1 有六行记录,主键哈希索引。
# MySQL 内存表主键默认哈希索引
mysql> create table t1(id int , name varchar(64), gender char(1), status char(2),primary key (id)) engine memory;
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t1 values(101,'张三','男','未婚');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t1 values(102,'小明','男','已婚');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t1 values(103,'李四','男','未婚');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t1 values(104,'李庆','女','已婚');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t1 values(105,'杨阳','女','未婚');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t1 values(106,'余欢水','男','二婚');
Query OK, 1 row affected (0.01 sec)我简单画了张主键哈希索引的分布图,见图 1:
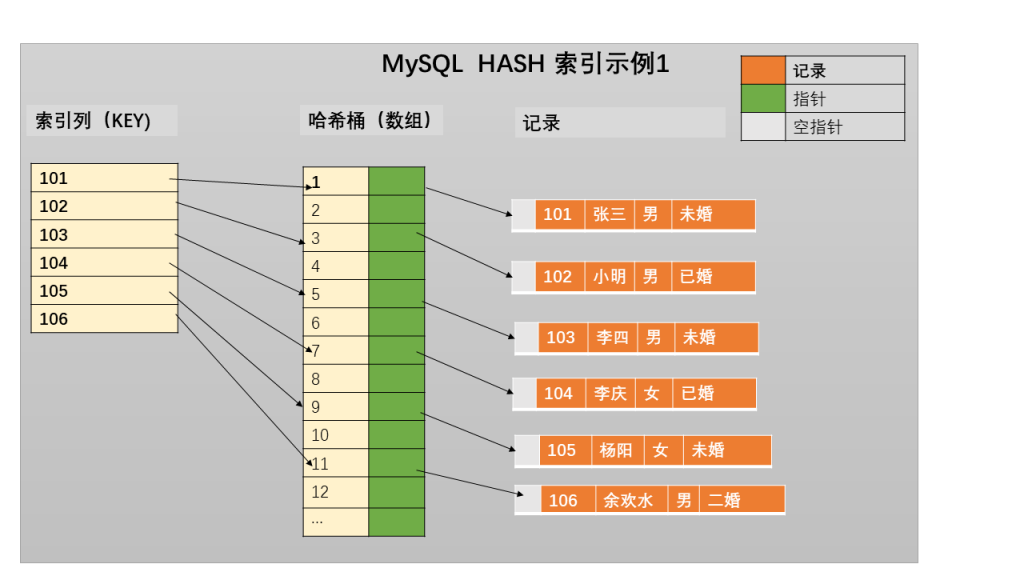
图 1 展示了 MySQL 内存表的哈希主键分布。MySQL 内存表允许非主键哈希索引存在。假设给列 name 加一个哈希索引,
mysql> alter table t1 add key idx_name(name) using hash;
Query OK, 6 rows affected (0.04 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> insert into t1 values(107,'杨阳','男','二婚');
Query OK, 1 row affected (0.00 sec)此时基于 name 列的哈希索引如图 2:
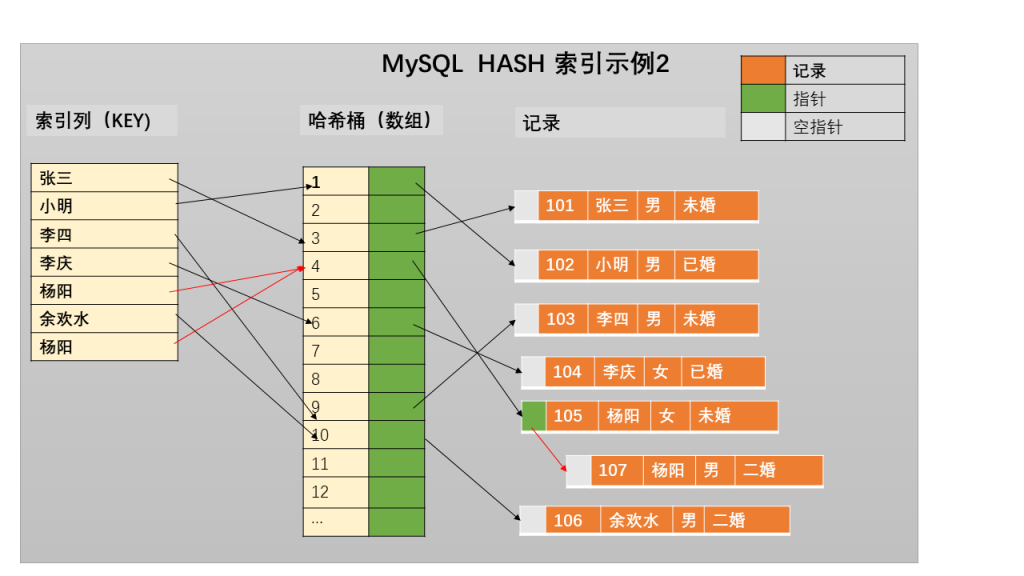
由图 2 发现,name 列做索引存在一定几率的哈希值碰撞,这类碰撞越多,哈希索引的性能下降越快,所以这种场景反而发挥不到哈希索引的优势。
二、使用场景
接下来我们来看看在 MySQL 哈希索引的使用场景。为了对比 B 树索引,建一张表 t1 的克隆表 t2。
# 省略表 t1 造数据过程
mysql> create table t2 like t1;
Query OK, 0 rows affected (0.02 sec)
mysql> alter table t2 drop primary key, drop key idx_name;
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> alter table t2 add primary key (id) using btree, add key idx_name (name) using btree;
Query OK, 0 rows affected (0.04 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> insert into t2 select * from t1;
Query OK, 50000 rows affected (0.18 sec)
Records: 50000 Duplicates: 0 Warnings: 02.1 哈希索引非常适合等值查找
仅限于以下操作符:”=”,”in”,”<=>”
“=” 和 “in” 大家都很熟悉,简单说下 “<=>”, “<=>” 也是等值操作符,不同的是可以比较 NULL 值,操作符左右两边都为 NULL 返回 1;任意一边非 NULL,返回 0;两边都非 NULL 也返回 1。见以下 SQL 0。
# SQL 0
mysql> select 10<=>10,null<=>null,null<=>true;
+---------+-------------+-------------+
| 10<=>10 | null<=>null | null<=>true |
+---------+-------------+-------------+
| 1 | 1 | 0 |
+---------+-------------+-------------+
1 row in set (0.00 sec)
接下来的几个 SQL 都是基于操作 “=” 和 “in”。
# SQL 1
mysql> select * from t1 where id = 2000;
+------+-----------+--------+--------+
| id | name | gender | status |
+------+-----------+--------+--------+
| 2000 | 王牡丹 | 男 | 离异 |
+------+-----------+--------+--------+
1 row in set (0.00 sec)
SQL 1 为基于主键的等值查询,非常适合用哈希索引,计算列 id=2000 的哈希值,能快速通过索引找到对应的记录。
# SQL 2
mysql> select * from t2 where id in (1000,2000);
+------+-----------+--------+--------+
| id | name | gender | status |
+------+-----------+--------+--------+
| 1000 | 余欢水 | 男 | 二婚 |
| 2000 | 王牡丹 | 男 | 离异 |
+------+-----------+--------+--------+
2 rows in set (0.00 sec)
SQL 2 虽然为 IN,但是子串的条件非常稀少(只有两个),也适合用哈希索引。
# SQL 3
mysql> select count(*) from t1 where id between 1000 and 2000;
+----------+
| count(*) |
+----------+
| 1001 |
+----------+
1 row in set (0.02 sec)
SQL 3 基于一个范围的查询,和以上两条 SQL 不一样,这种 SQL 没法走哈希索引。原因很明确:基于索引字段生成的哈希值和索引字段本身的可排序性没有任何联系,哈希索引无从下手。这样的场景,就得使用先天优势的 B 树索引。
把 SQL 3 的表改为 t2,基于 B 树索引。
# SQL 4
mysql> select count(*) from t2 where id between 1000 and 2000;
+----------+
| count(*) |
+----------+
| 1001 |
+----------+
1 row in set (0.00 sec)
对比下 SQL 3 和 SQL 4 的执行计划,SQL 3 不走索引,全表扫描 5W 行;SQL4 走主键索引只扫描 3000 行。
mysql> explain select count(*) from t1 where id between 1000 and 2000\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 50000
filtered: 11.11
Extra: Using where
1 row in set, 1 warning (0.00 sec)
mysql> explain select count(*) from t2 where id between 1000 and 2000\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t2
partitions: NULL
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 3052
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)2.2 无法通过哈希索引排序
哈希索引本身是无序的,所以基于哈希索引的排序只能走全表扫描,并且额外排序。SQL 5 和 SQL 6 分别对表 t1,t2 执行同样的倒序输出。
# SQL 5
mysql> select id from t1 where 1 order by id desc limit 1;
+--------+
| id |
+--------+
| 135107 |
+--------+
1 row in set (0.02 sec)
# SQL 6
mysql> select id from t2 where 1 order by id desc limit 1;
+--------+
| id |
+--------+
| 135107 |
+--------+
1 row in set (0.00 sec)
来看下这两条 SQL 的执行计划:
mysql> explain select id from t1 where 1 order by id desc limit 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t1
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 50000
filtered: 100.00
Extra: Using filesort
1 row in set, 1 warning (0.00 sec)
mysql> explain select id from t2 where 1 order by id desc limit 1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t2
partitions: NULL
type: index
possible_keys: NULL
key: PRIMARY
key_len: 4
ref: NULL
rows: 1
filtered: 100.00
Extra: Backward index scan
1 row in set, 1 warning (0.00 sec)
可以看到 SQL 6 走 B 树索引反向扫描拿回对应的 ID,SQL 5 就只能全表排序拿数据。
2.3 哈希索引不存在 covering index 概念
同样,由于哈希值是基于哈希函数生成,索引值并不包含数据本身,任何对哈希索引的查找都得回表。
mysql> flush status;
Query OK, 0 rows affected (0.01 sec)
# SQL 7
mysql> select id from t1 limit 1;
+-----+
| id |
+-----+
| 949 |
+-----+
1 row in set (0.00 sec)
mysql> show status like 'handler%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Handler_commit | 0 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_external_lock | 2 |
| Handler_mrr_init | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 0 |
| Handler_read_key | 0 |
| Handler_read_last | 0 |
| Handler_read_next | 0 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_next | 849 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 0 |
+----------------------------+-------+
18 rows in set (0.00 sec)
mysql> flush status;
Query OK, 0 rows affected (0.01 sec)
# SQL 8
mysql> select id from t2 limit 1;
+-----+
| id |
+-----+
| 949 |
+-----+
1 row in set (0.00 sec)
mysql> show status like 'handler%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Handler_commit | 0 |
| Handler_delete | 0 |
| Handler_discover | 0 |
| Handler_external_lock | 2 |
| Handler_mrr_init | 0 |
| Handler_prepare | 0 |
| Handler_read_first | 0 |
| Handler_read_key | 0 |
| Handler_read_last | 0 |
| Handler_read_next | 0 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_next | 1 |
| Handler_rollback | 0 |
| Handler_savepoint | 0 |
| Handler_savepoint_rollback | 0 |
| Handler_update | 0 |
| Handler_write | 0 |
+----------------------------+-------+
18 rows in set (0.00 sec)
以上分别执行 SQL 7 和 SQL 8 。两条 SQL 只拿出索引键,对比下 MySQL 的 HANDLER 状态,发现 SQL 7 回表了 849 次才找到记录;SQL 8 只回表了一次。
2.4 哈希索引不同于B+树,不能基于部分索引查询
比如对字段 (x1,x2,x3) 建立联合哈希索引,由于哈希值是针对这三个字段联合计算,只有一个,不能针对单个字段来走索引。在此基础上,在建立上两表,主键为联合索引,表 t3 主键是哈希索引,表 t4 主键是 B 树索引。
mysql> create table t3(id1 int,id2 int,r1 int, primary key(id1,id2)) engine memory;
Query OK, 0 rows affected (0.03 sec)
mysql> create table t4(id1 int,id2 int,r1 int, primary key(id1,id2) using btree) engine memory;
Query OK, 0 rows affected (0.03 sec)
#省略造数据过程。
mysql> select (select count(*) from t3) t3, (select count(*) from t4) t4;
+-------+-------+
| t3 | t4 |
+-------+-------+
| 16293 | 16293 |
+-------+-------+
1 row in set (0.00 sec)
# SQL 9
mysql> select * from t3 where id1 = 44;
+-----+-----+------+
| id1 | id2 | r1 |
+-----+-----+------+
| 44 | 98 | 29 |
| 44 | 180 | 56 |
| 44 | 130 | 32 |
| 44 | 104 | 65 |
| 44 | 208 | 4 |
| 44 | 154 | 113 |
| 44 | 69 | 84 |
| 44 | 76 | 154 |
| 44 | 132 | 33 |
| 44 | 108 | 79 |
| 44 | 173 | 6 |
+-----+-----+------+
11 rows in set (0.00 sec)
# SQL 10
mysql> select * from t4 where id1 = 44;
+-----+-----+------+
| id1 | id2 | r1 |
+-----+-----+------+
| 44 | 69 | 84 |
| 44 | 76 | 154 |
| 44 | 98 | 29 |
| 44 | 104 | 65 |
| 44 | 108 | 79 |
| 44 | 130 | 32 |
| 44 | 132 | 33 |
| 44 | 154 | 113 |
| 44 | 173 | 6 |
| 44 | 180 | 56 |
| 44 | 208 | 4 |
+-----+-----+------+
11 rows in set (0.00 sec)
SQL 9 和 SQL 10 都是基于联合主键第一个字段查询。简单看下执行计划。很明显,SQL 9 没走索引,SQL10 走主键。
mysql> explain select * from t3 where id1 = 44\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t3
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 16293
filtered: 10.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from t4 where id1 = 44\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: t4
partitions: NULL
type: ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: const
rows: 30
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)这篇关于 MySQL 哈希索引的介绍就到此为止。这篇主要讲 MySQL 哈希索引的数据分布以及使用场景,希望对大家有帮助。
关于 MySQL 的技术内容,你们还有什么想知道的吗?赶紧留言告诉小编吧!
