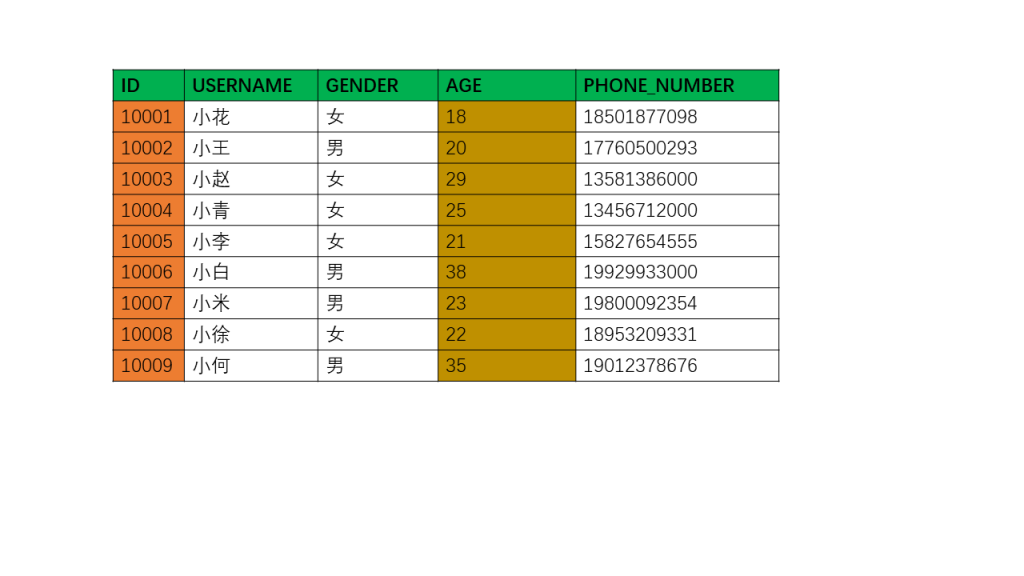
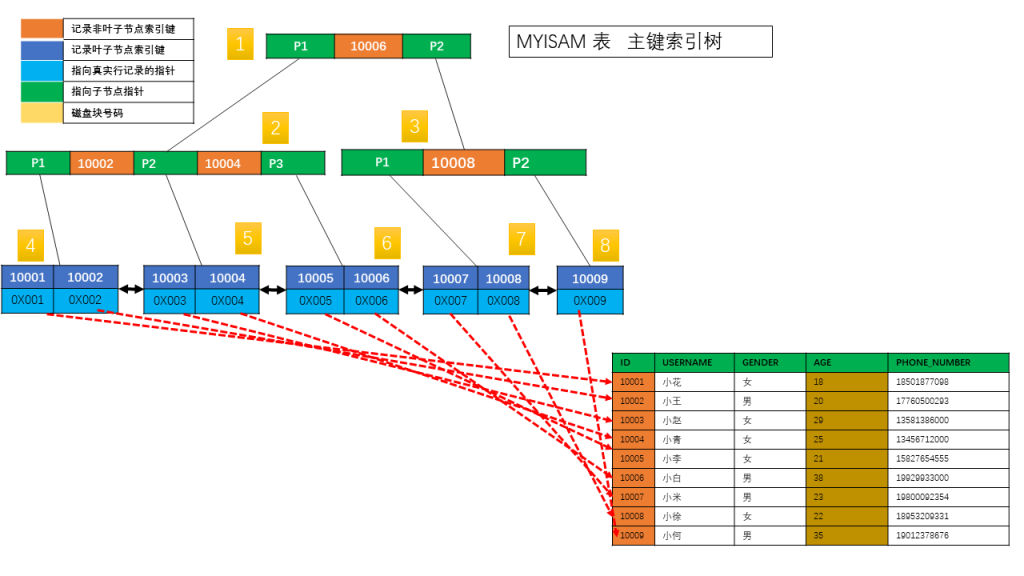
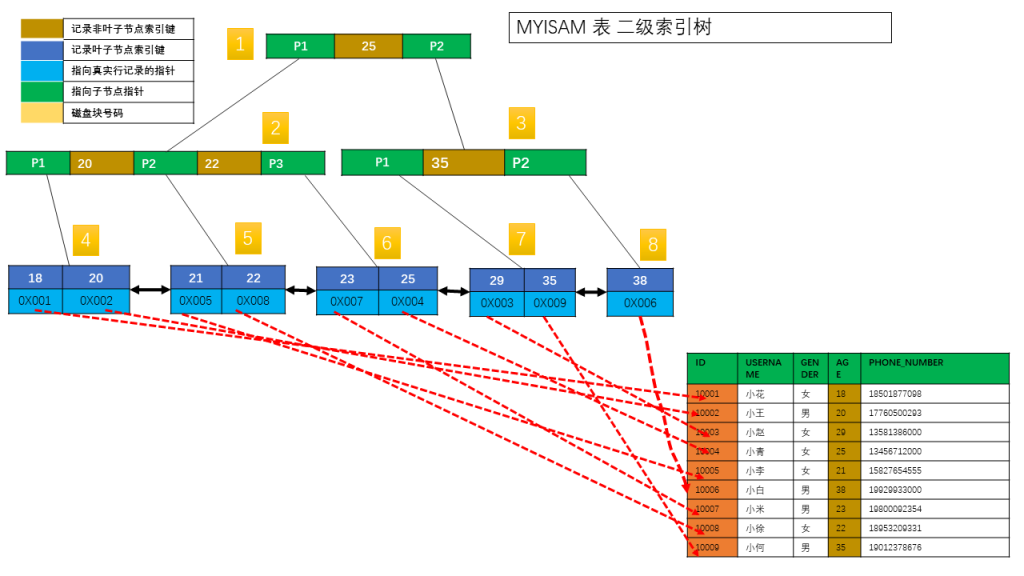
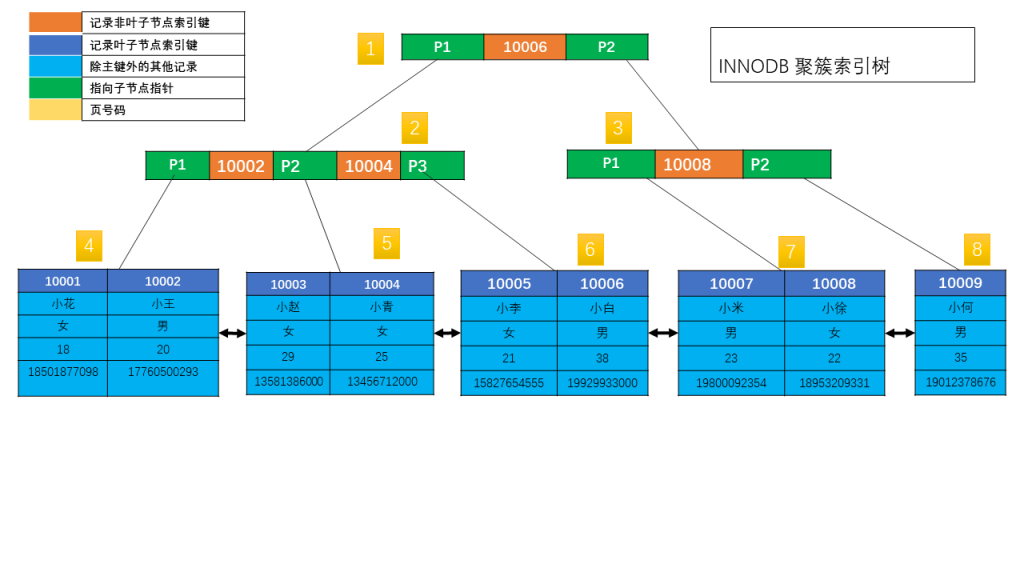
举个简单例子演示下,
以下 SQL 1 默认没有排序,乱序输出;需要按照 ID 顺序输出,就得用 SQL 2,显式加 ORDER BY 。
mysql# SQL 1mysql> select * from t1;+-------+----------+--------+------+--------------+| id | username | gender | age | phone_number |+-------+----------+--------+------+--------------+| 10001 | 小花 | 女 | 18 | 18501877098 || 10005 | 小李 | 女 | 21 | 15827654555 || 10006 | 小白 | 男 | 38 | 19929933000 || 10009 | 小何 | 男 | 35 | 19012378676 || 10002 | 小王 | 男 | 20 | 17760500293 || 10003 | 小赵 | 女 | 29 | 13581386000 || 10004 | 小青 | 女 | 25 | 13456712000 || 10007 | 小米 | 男 | 23 | 19800092354 || 10008 | 小徐 | 女 | 22 | 18953209331 |+-------+----------+--------+------+--------------+9 rows in set (0.00 sec)
# SQL 2mysql> select * from t1 order by id;+-------+----------+--------+------+--------------+| id | username | gender | age | phone_number |+-------+----------+--------+------+--------------+| 10001 | 小花 | 女 | 18 | 18501877098 || 10002 | 小王 | 男 | 20 | 17760500293 || 10003 | 小赵 | 女 | 29 | 13581386000 || 10004 | 小青 | 女 | 25 | 13456712000 || 10005 | 小李 | 女 | 21 | 15827654555 || 10006 | 小白 | 男 | 38 | 19929933000 || 10007 | 小米 | 男 | 23 | 19800092354 || 10008 | 小徐 | 女 | 22 | 18953209331 || 10009 | 小何 | 男 | 35 | 19012378676 |+-------+----------+--------+------+--------------+9 rows in set (0.00 sec)
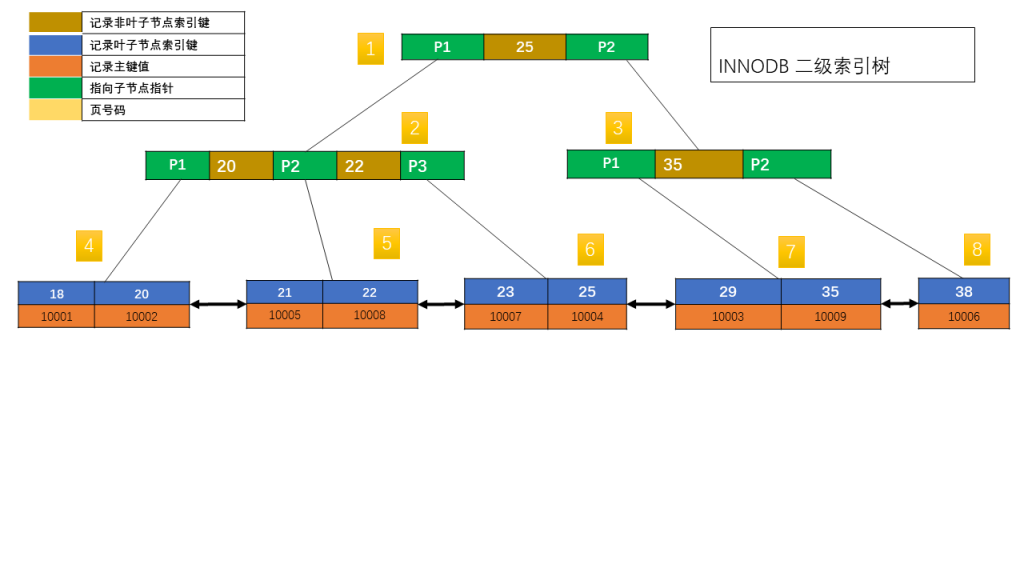
接下来看看 INNODB 的主键索引和二级索引的组成方式。