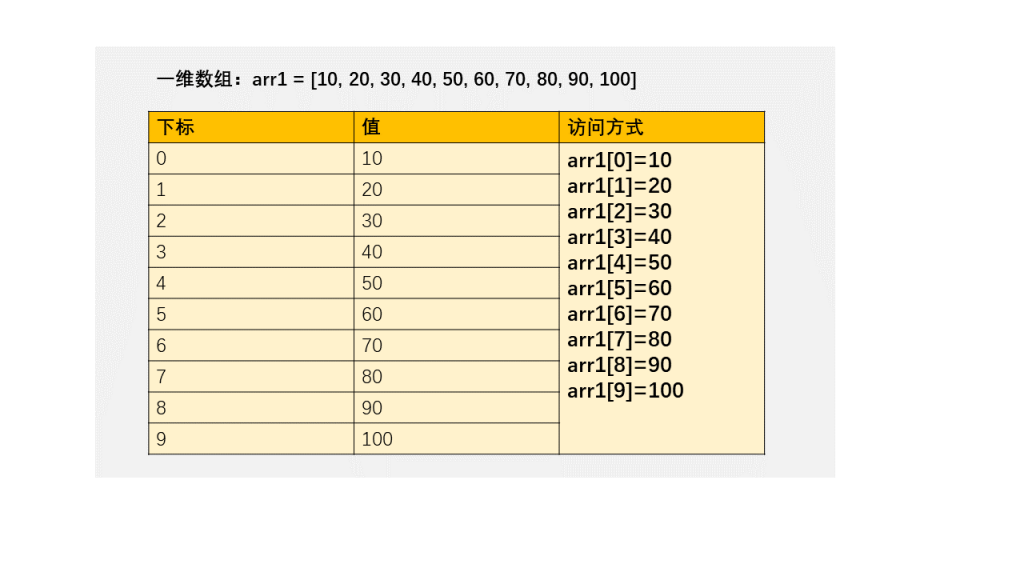
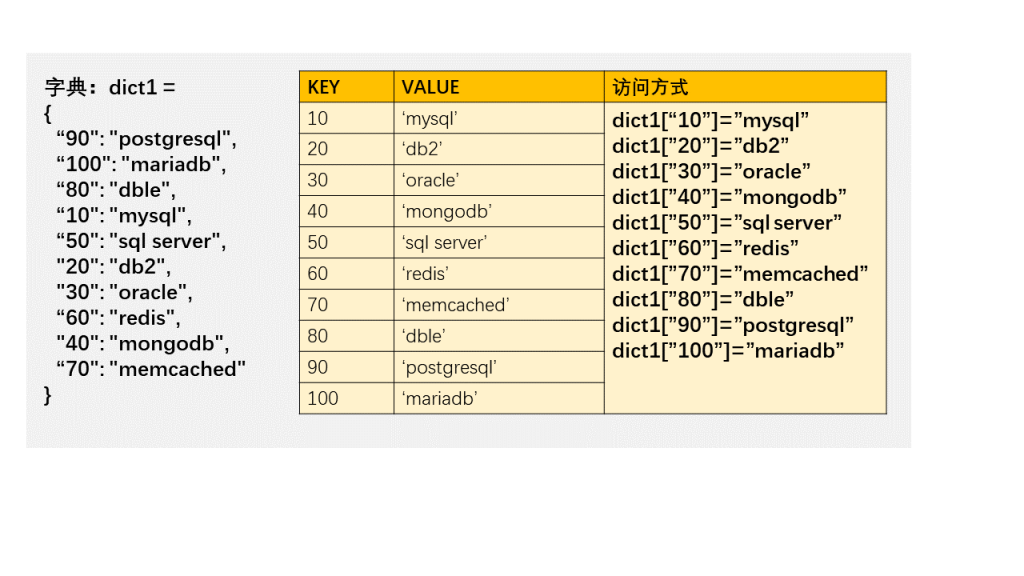
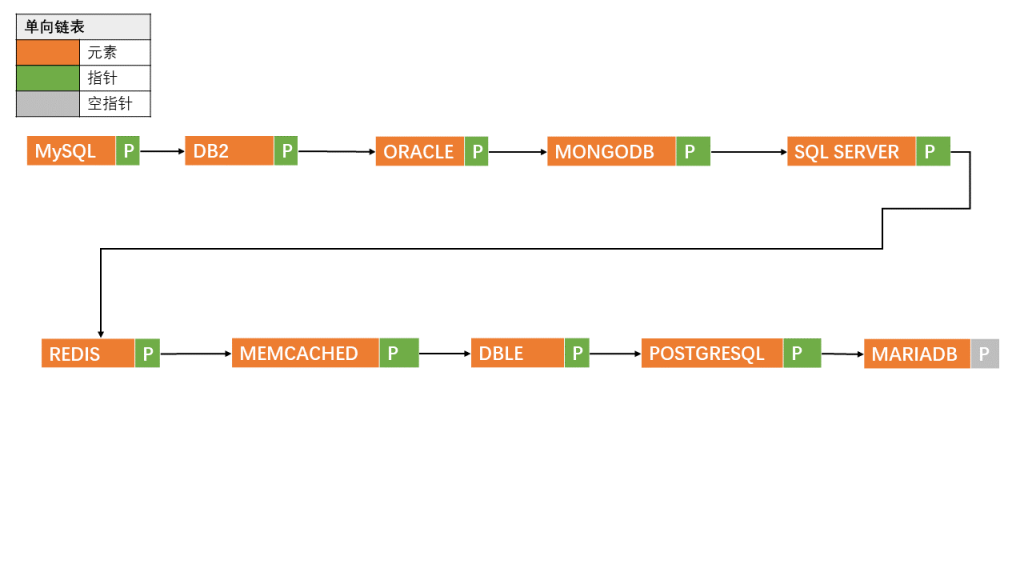
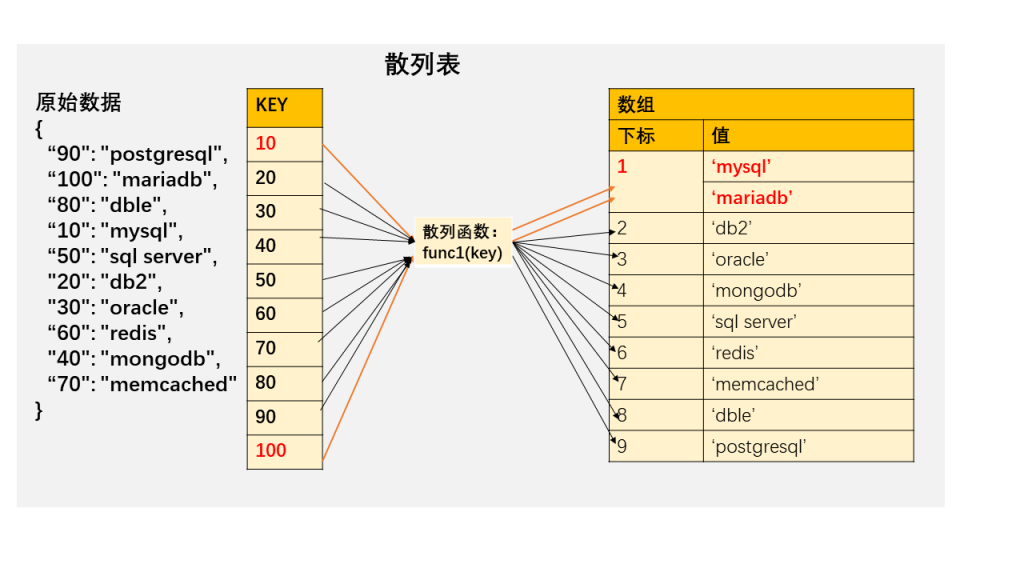
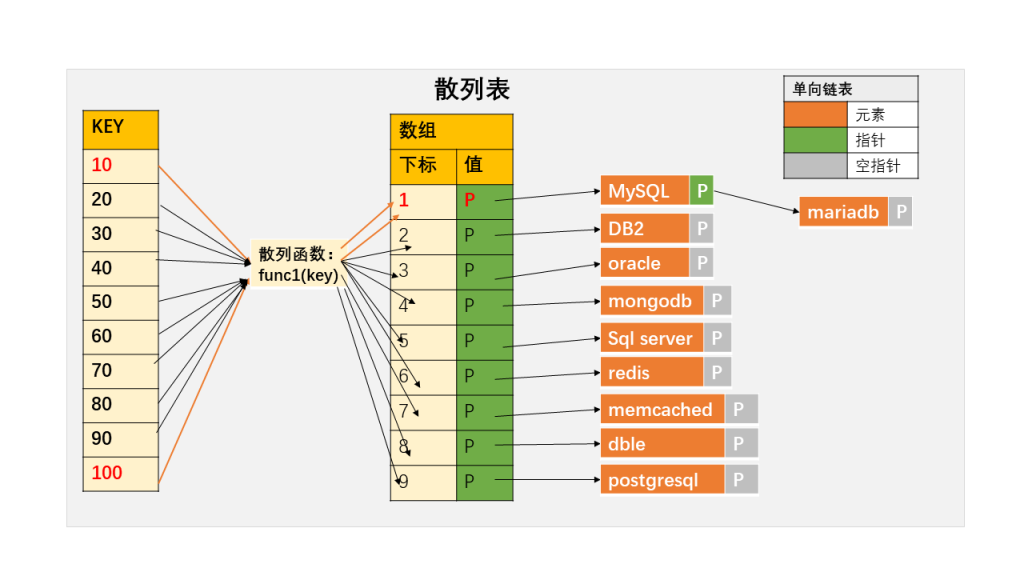
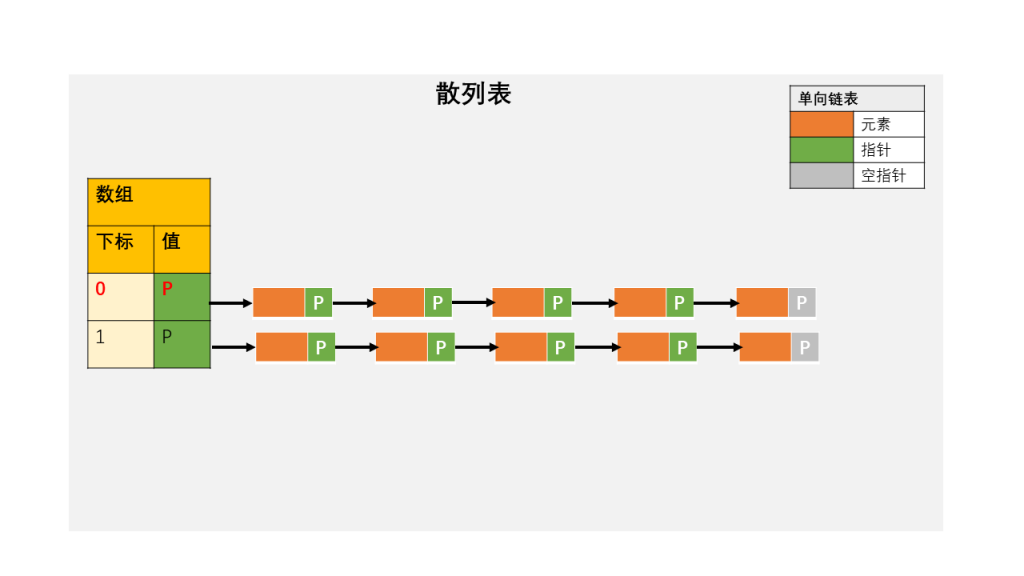
MySQL 也同样提供了这样的字典,比如下面定义了一个字典,存入变量 @a,把图 2 里前 4 个元素拿出来,对应的 value 分别为 “mysql”,”db2″,”oracle”,”mongodb”.
mysql> set @a='{"10":"mysql","20":"db2","30":"oracle","40":"mongodb"}';Query OK, 0 rows affected (0.00 sec)
mysql> select json_keys(@a);+--------------------------+| json_keys(@a) |+--------------------------+| ["10", "20", "30", "40"] |+--------------------------+1 row in set (0.00 sec)
mysql> set @x1=json_extract(@a,'$."10"');Query OK, 0 rows affected (0.01 sec)
mysql> set @x2=json_extract(@a,'$."20"');Query OK, 0 rows affected (0.00 sec)
mysql> set @x3=json_extract(@a,'$."30"');Query OK, 0 rows affected (0.00 sec)
mysql> set @x4=json_extract(@a,'$."40"');Query OK, 0 rows affected (0.00 sec)
mysql> select @x1 "dict['10']", @x2 "dict['20']", @x3 "dict['30']", @x4 "dict['40']";+------------+------------+------------+------------+| dict['10'] | dict['20'] | dict['30'] | dict['40'] |+------------+------------+------------+------------+| "mysql" | "db2" | "oracle" | "mongodb" |+------------+------------+------------+------------+1 row in set (0.00 sec)