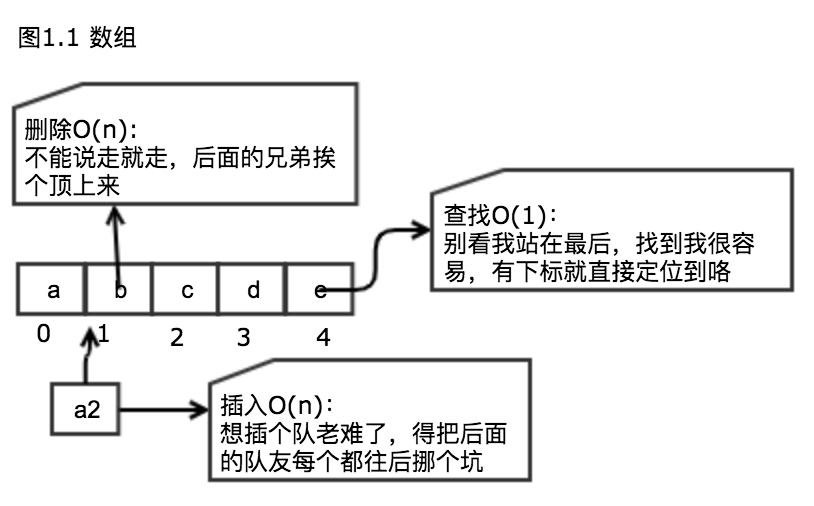
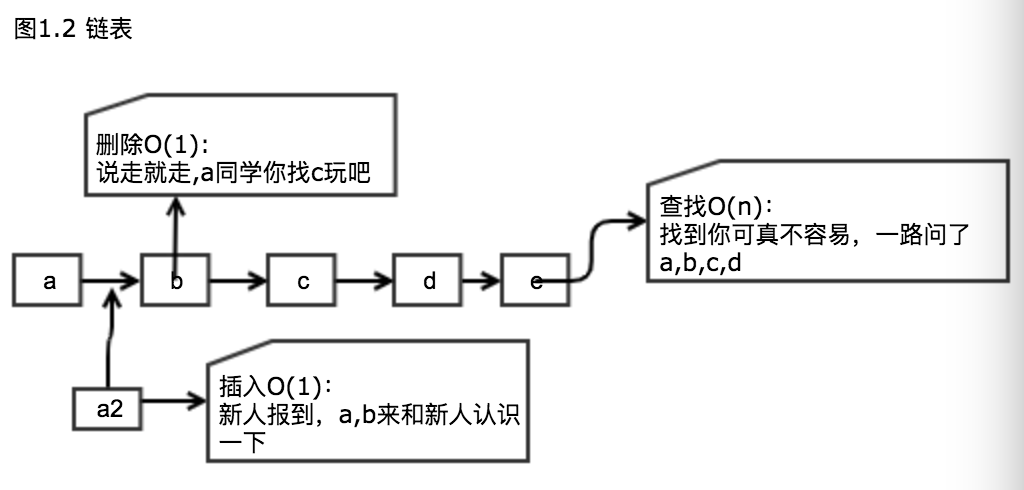
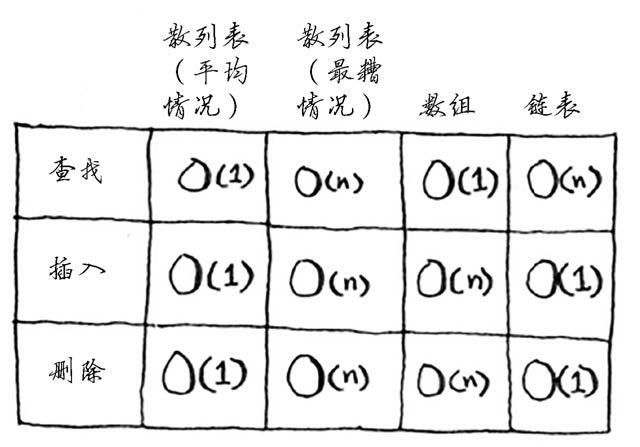
作者:赵红杰DBLE 项目测试负责人,主导分布式中间件的测试,在测试中不断发现产品和自身的 bug。迭代验证,乐在其中。本文来源:原创投稿 *爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。 背景 社区有大佬分享过跳增 hash 的文章,但是当时并不理解跳增 hash 使用的场景。 刚接触分布式数据库中间件 dble 的时候,最迷惑的概念之一是 hash 分片算法。 看到哈希,第一印象是散列表,感觉是存储相关的。hash 一个重要的特征是需要不同输入产生不同输出,但是在分片算法里,是需要多个值映射到一个分片节点上。这么大的差异,为什么可以用 hash 来对分布式数据库做逻辑分片,并且还命名叫 hash 分片!!!它们之间有哪些神似呢? 概念 散列表 要理解他们之间的相似和差异,先从对 hash 最初的认识——散列表说起。 散列表是一种数据结构,通过散列函数(也就是 hash 函数)将输入映射到一个数字,一般用映射出的数字作为存储位置的索引。 数组在查找时效率很高,但是插入和删除却很低。而链表刚好反过来。 设计合理的散列函数可以集成链表和数组的优点,在查找、插入、删除时实现 O(1) 的效率。散列表的存储结构使用的也是数组加链表。执行效率对比可以看下图 1.3: 散列表的主要特点:1. 将输入映射到数字2. 不同的输入产生不同的输出3. 相同的输入产生相同的输出4. 当填装因子超过阈值时,能自动扩展。填装因子 = 散列表包含的元素数 / 位置总数,当填装因子 =1,即散列表满的时候,就需要调整散列表的长度,自动扩展的方式是:申请一块旧存储容量 X 扩容系数的新内存地址,然后把原内存地址的值通过其中的 key 再次使用 hash 函数计算存储位置,拷贝到新申请的地址。5. 值呈均匀分布。这里的均匀指水平方向的,即数组维度的。如果多个值被映射到同一个位置,就产生了冲突,需要用链表来存储多个冲突的键值。极端情况是极限冲突,这与一开始就将所有元素存储到一个链表中一样。这时候查找性能将变为最差的 O(n),如果水平方向填充因子很小,但某些节点下的链表又很长,那值的均匀性就比较差。 hash 分片 理解了散列表的基本特点,再来看看分布式数据库的 hash 分片。 hash 分片设计的要点:1. 固定的数据映射到固定的节点 / 槽位2. 数据分布均匀3. 扩容方便主要是扩容时尽可能移动较少的数据。扩容之后实现新的数据分布均匀。想要实现动态扩容,尽可能不影响业务并保证效率,需要做到移动尽可能少的数据,一致性 hash 就是为了解决移动较少数据的问题,但是一致性 hash 的缺点是数据分布的均匀性较差。为了解决这个问题,聪明的 dev 们又设计了跳增一致性 hash 算法。到这里,可以看出 hash 与分片最紧密或者说最神似的点在于:1. 固定的输入有固定的输出2. 值呈均匀分布如果分布式数据库的分片数据分布不均匀,最糟情况就像散列表的极端冲突一样,落在最终数据库上的压力跟不使用分布式相同。3. 方便扩容当分片填充满的时候,需要扩容使总数据量在总分片之间再次达到数据均匀分布状态,扩容需要用 hash 函数重新映射旧值到新的分片。4. 散列表和 hash 分片想要有好的表现都依赖于设计良好的 hash 函数。正是由于这些相似特点,Hash 在分布式数据库里得到比较多的使用。回到测试的老本行,这些点便是我们测试思考的重点。了解了分布式与 hash 的关联,再来八几句 hash 函数,可以说hash函数设计的好坏,直接决定了分片策略是否合适。一致性 hash 和跳增 hash,大家参考社区相关文章:https://opensource.actionsky.com/20190910-dble/ hash 取模分片 还有一种比较简单的 hash 函数是取模 hash。目前的分布式数据库基本都提供了这种分片支持。主要业务场景是:分片键的值存在单调递增或递减、分片键的值不确定,基数大且重复的频率低、需要写入的数据随机分发、数据读取随机性较大。 取模 hash,举个最简单的例子就能明白:分片数设置为 2,要把数据均匀分布在这 2 个分片上,直接对分片 key 取模 2,这样模值为 0 的数据落在分片 1,模值为 2 的数据落在分片 2。只要输入的数据奇偶均匀,分片数据就保证均衡。 取模 hash 在 dble 里还做了一些变种支持,比如可以指定每个分片的连续值的数量,比如自然数 0-99 放分片 1,自然数 100-599 放分片 2,具体配置方式参考官方文档。这样做主要目的是改善 hash 在范围查询时的效率问题。 Hash 取模分片非常简单,均衡性比较好,能分散数据热点,并且能快速人为识别数据所在分片。缺点也很明显。 1. 在业务上范围查询效率比较低2. 扩容不便 因为取模 hash 强依赖于分片数,当新增或删减分片节点——即扩缩容时,大量的数据在重新映射后都需要挪动。比如上面的 2 分片数据,如果增加到 3 分片,原来分片 1 上的数据只有 1/3 的数据可以保留不动,另外 2/3 的数据都需要挪到新的分片上,分片 2 也是如此。 如果真的使用了 hash 取模分片,为了后期在扩容时移动尽可能少的数据,dble 的建议是:取模的基数不能大于 2880,原因是:2, 3, 4, 5, 6, 8, 9, 10, 12, 15, 16, 18, 20, 24, 30, 32, 36, 40, 45, 48, 60, 64, 72, 80, 90, 96, 120, 144, 160, 180, 192, 240, 288, 320, 360, 480, 576, 720, 960, 1440 是 2880 的约数。 以上是对分布式与 hash 的一些浅显认识,文章内容部分来自对书或互联网知识的个人理解,不当之处欢迎指正。Ref:《图解算法》《分布式系统常用技术及案例分析》https://actiontech.github.io/dble-docs-cn/1.config_file/1.05_sharding.xml.htmlhttps://tech.antfin.com/docs/2/99411 相关推荐: 分布式 | MyCat如何迁移到DBLE之分片算法对比解析:hash分片 分布式 | Global 表 Left Join 拆分表实现原因探究 分布式 | DBLE 之通过 explain 进行 SQL 优化 分类: DBLE 分布式中间件 标签:hash分布式分片算法