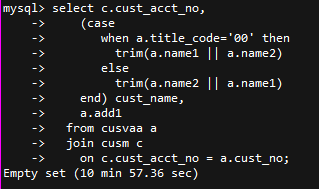
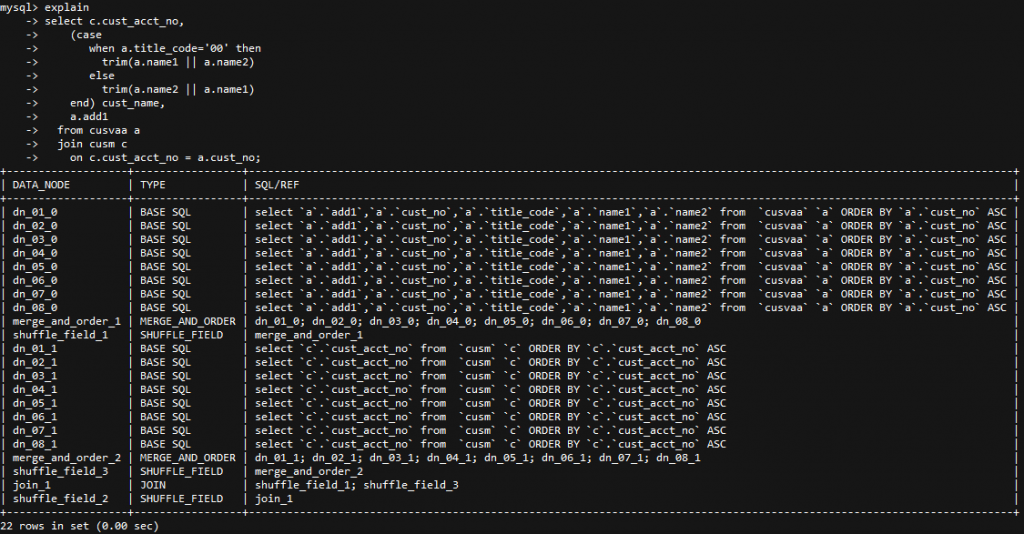
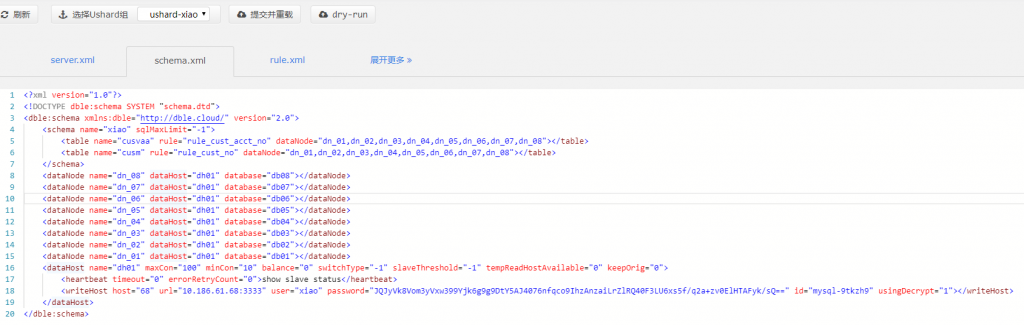
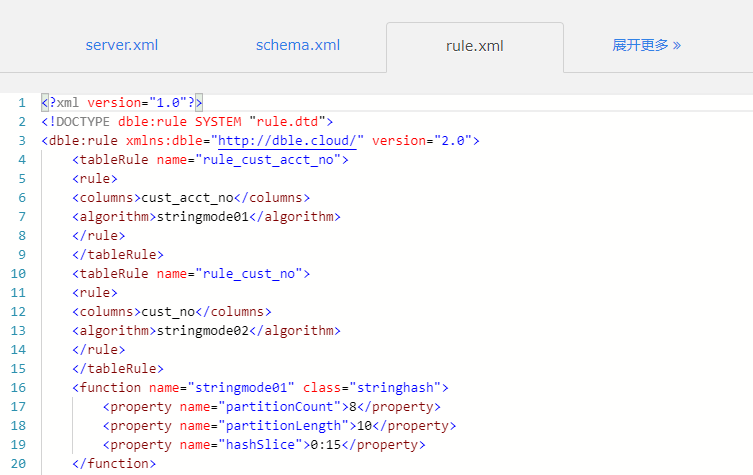
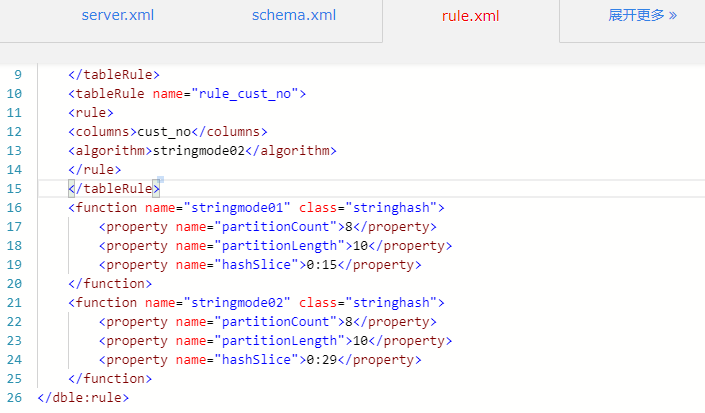
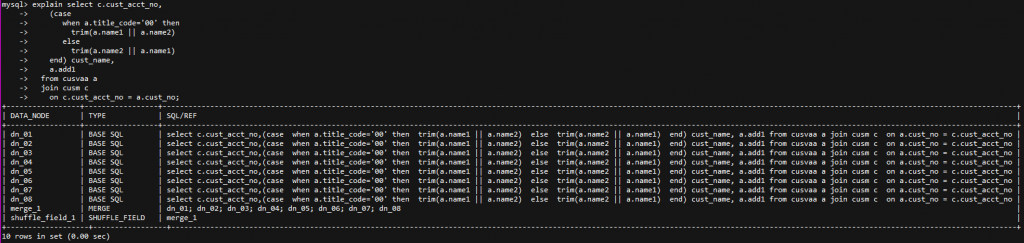
作者:肖亚洲爱可生 DBA 团队成员,负责项目中数据库故障与平台问题解决,对数据库高可用与分布式技术情有独钟。本文来源:原创投稿*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。 问题描述 客户 DBLE 测试环境在进行应用对接功能验证时,发现一个功能久久不出结果并出现超时的报错。从客户那里了解到当该功能在既定时间获取不到后端数据返回,就会出现该报错。 环境检查 当前 DBLE 版本是 2.19.07.3 版本,数据库版本是 MySQL-5.7.25。业务 SQL 涉及到的两张表 cusvaa、cusm 均是拆分表,数据量分别是 67 条、7600w 条;Join 条件是分片键且分片规则都使用的 stringhash,拆分成 8 个片,每个片长度 10。客户工程师再反馈如上情况后,问了我一个问题:“关联条件是分片键,且分片规则相同为什么执行效率这么慢?” 问题排查 带着客户的疑问,开始了问题的排查。当时应对该功能执行的 SQL 如下: 当我在看到这个截图的时候,首先的预感就是执行时间太长,Join 的分片键条件是不是无效的?之后跟客户要了执行计划。 该 SQL 在 DBLE 层执行计划如下: 在得到这些信息后,基本能够确认分片键没有起到效果。在执行计划中能够明确看到 DBLE 是将 SQL 拆分并下发到每个分片,将数据从分片中全量获取且排序后在 DBLE 中间层做 MERGE 与 Join 操作。 正常情况是应该将 SQL 下发到每个分片,将每个分片的执行结果返回到 DBLE 直接做 MERGE 操作。 想到客户说的采用的同样的拆分规则 stringhash,心里不禁有了嘀咕。客户是不是配置了 hashSlice 呢?随即让客户提供了 DBLE 的配置文件。 schema.xml 文件: rule.xml 文件: 看到客户提供的 rule.xml 文件,也确实验证了自己的猜想,虽然采用的是同一个分片规则 stringhash,但具体的分片函数 function 的配置不同,这分明就是两个分片规则啊。 之后让客户与业务开发确认了分片键的取值范围,调整了分片函数。如下: 调整完后进行动态加载,使配置生效。再次查看该 SQL 的执行计划: 看到这个执行计划后,确认当前的分片键起到了作用,之后让客户再次进行功能验证,结果也在秒级响应。 结论 Stringhash 的 function 配置不光要定义 partitionLength[] 和 partitionCount[] 两个数组,还需要配置 hashSlice 二元组。 DBLE 在进行 SQL 解析与路由的时候是会判断分片规则的所有内容的,针对分片规则一致的 SQL 才会直接下发到每个分片,计算结果后返回 DBLE 层做 MERGE 操作,反之就要去分片中捞所有数据到 DBLE 层做 MERGE、Join 操作。 在处理 dble 环境 sql 执行慢的问题时,我们不光要获取 sql 的执行情况还要确认客户提供给我的描述是否与实际情况相符。 分类: DBLE 分布式中间件 标签:DBLEMycat