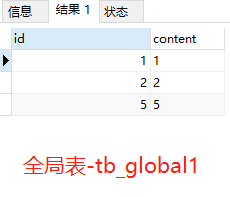
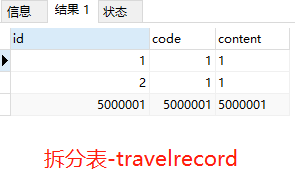
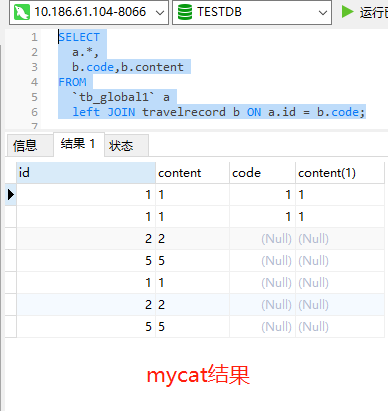
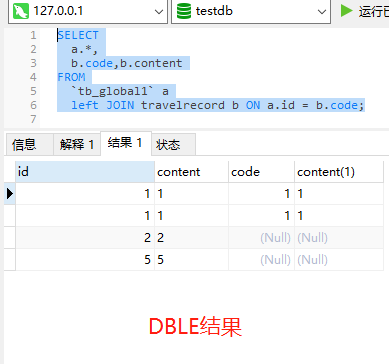
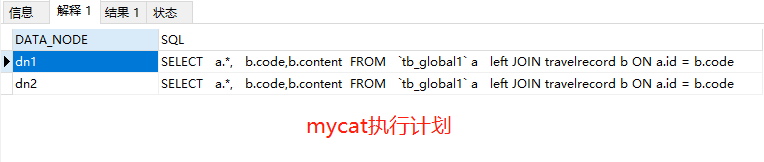
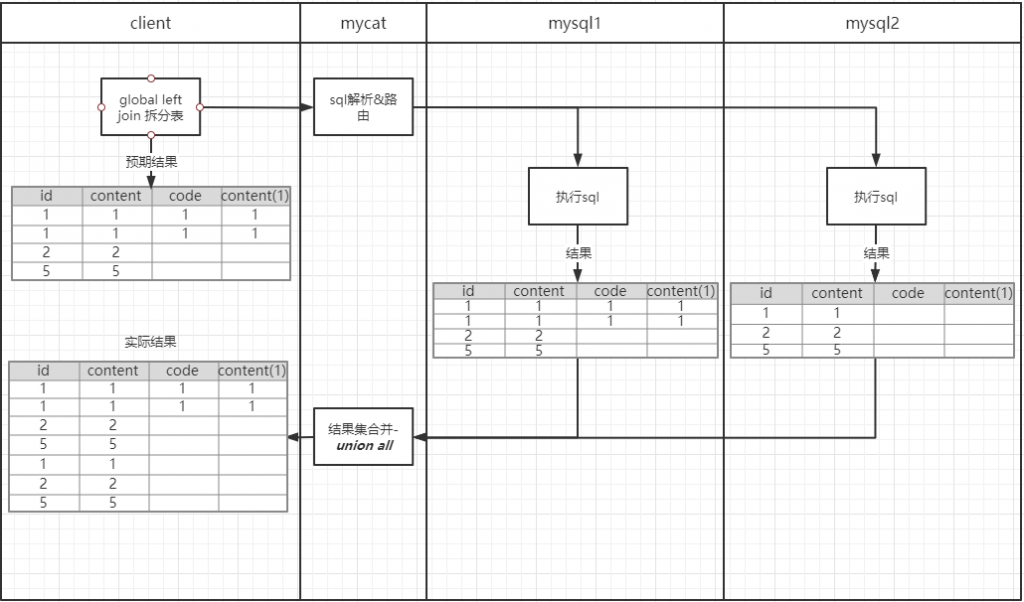
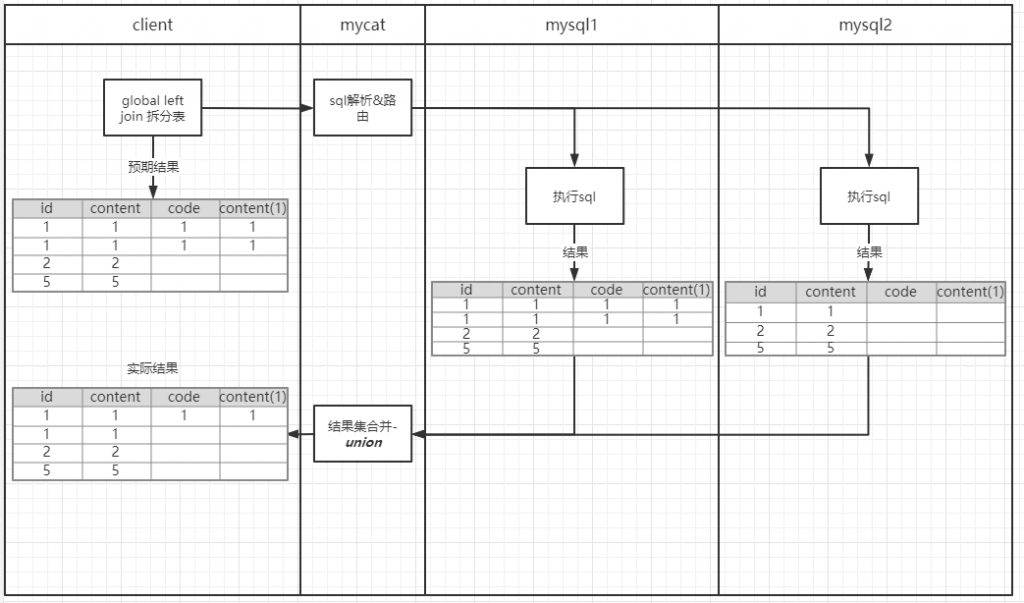
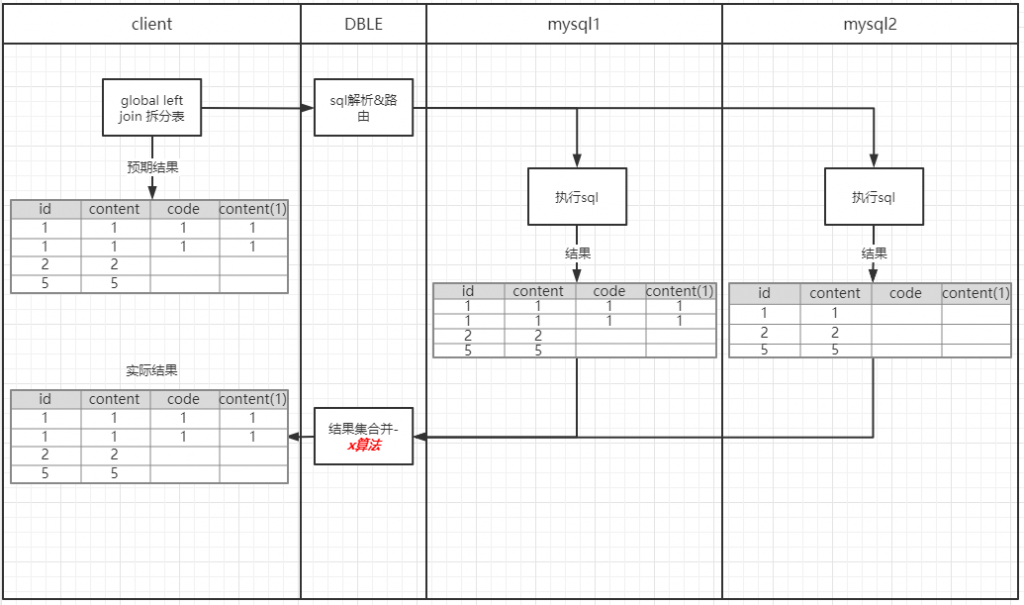
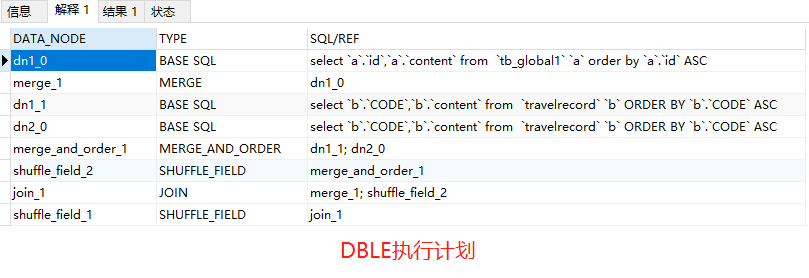
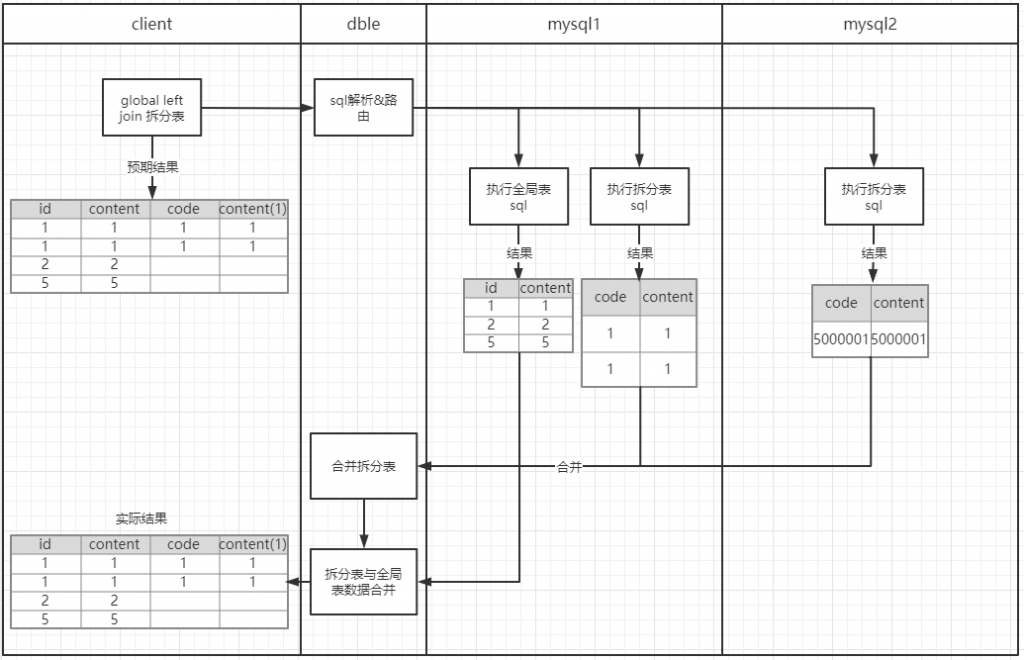
作者:郭奥门爱可生 DBLE 研发成员,负责分布式数据库中间件的新功能开发,回答社区/客户/内部提出的一般性问题。本文来源:原创投稿 *爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。 本文关键字:JOIN、原理解析、分库分表 相关文章推荐: 分布式 | DBLE 之通过 explain 进行 SQL 优化 分布式 | dble 中分布式时间戳方式的全局序列 问题 前几天,社区交流群一个小伙伴提出这样一个问题: 小伙伴说:全局表和分片表的左连接能否支持 — 目前测试 Mycat 结果不对。 很显然是想要脱坑的 Mycat 用户,急需找个替代品,主要的是他也找到了,哈哈哈。 场景重现 首先我们创建一个全局表和一个拆分表,各自设置两个分片节点,全局表在两个节点数据一致,拆分表 id=1、2 的在一个节点,id=5000001 的在另一个节点,其中 id=1 和 id=2 的只有 id 字段值不同、code&content 字段值都一样。如图: Mycat 实现效果 通过 a.id、b.code 将两张表左连接查询,结果如小伙伴所言:Mycat 结果不对。 DBLE 实现效果 同样,通过 a.id、b.code 将两张表左连接查询,结果如下所示;显而易见 DBLE 实际得到的结果符合预期! 结果探究 根据以上使用 Mycat 和 DBLE 进行 “Global 表 Left Join 拆分表查询”得到不同的结果,我们尝试着使用 EXPLAIN 查看同一种类型的查询在执行计划上会有什么不同? Mycat 执行计划 根据上图执行计划,我们简单分析一下。 Mycat 会将 SQL 原封不动的交由分片配置的所有实例去执行,然后根据执行结果进行合并,这里合并只是简单的对结果进行累加,很显然这样的计划显示 Mycat 内部处理逻辑是错误的。 因为全局表在每个配置的节点都会存储相同的数据,如果将每个节点和拆分表 Left Join 的结果进行简单的 UNION ALL 合并,会造成数据的重复,不能保证数据的准确性。 有些小伙伴可能猜想 UNION 不是会保证数据不重复吗?如果用 UNION 是否可行?同样分析一下。 上述结果仍然得不到我们想要的结果,因为 UNION 只是解决数据重复的问题,不适用于因为分片而导致的数据重复问题; 试想一下,如果 DBLE 未来通过某种算法可以对各个节点的结果集做一个准确的合并,那么这样的问题也就迎刃而解,也会性能方面有个整体的提升。 实际上我们想象中的 X 算法还没有一个良好的实现和证明,但现在又要解决查询正确性的问题,那么 DBLE 是怎么做的呢?下面我们来看下 DBLE 的执行计划: 从上面执行计划来看,简单分析下流程: DBLE 内部对于这种查询作出了一些区分:全局表只会下发一个实例,拆分表都会下发,然后针对结果做合并,这种处理逻辑肯定是没有错误的,只不过执行计划看起来相对复杂一些,这也代表在 DBLE 内部实现层面上下了不少功夫,但是这也是为了保证数据准确性而作出的一些牺牲吧。 分类: DBLE 分布式中间件 标签:JOIN分库分表原理解析