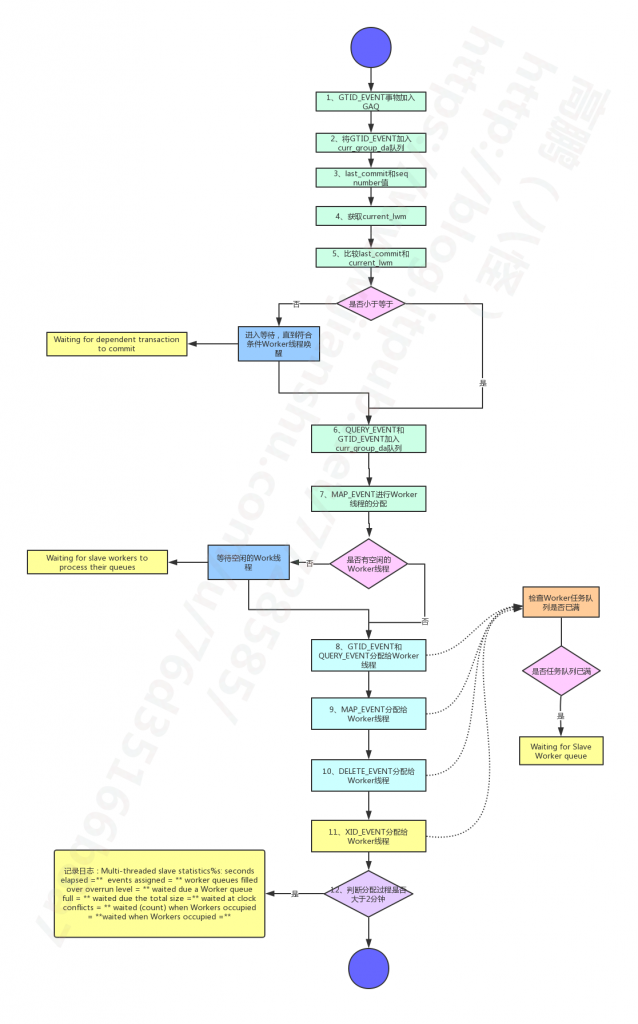
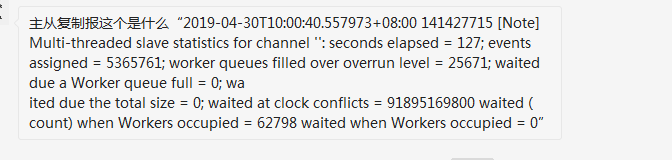
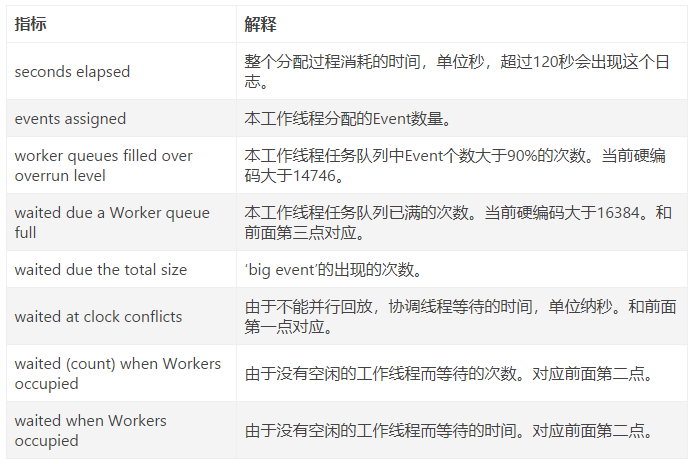
这个截图也是一个朋友问的问题。实际上这个日志可以算一个警告。实际上对应的源码为:
sql_print_information("Multi-threaded slave statistics%s: "
"seconds elapsed = %lu; "
"events assigned = %llu; "
"worker queues filled over overrun level = %lu; "
"waited due a Worker queue full = %lu; "
"waited due the total size = %lu; "
"waited at clock conflicts = %llu "
"waited (count) when Workers occupied = %lu "
"waited when Workers occupied = %llu",
rli->get_for_channel_str(),
static_cast<unsignedlong>
(my_now - rli->mts_last_online_stat),
//消耗总时间 单位秒
rli->mts_events_assigned,
//总的event分配的个数
rli->mts_wq_overrun_cnt,
// worker线程分配队列大于 90%的次数 当前硬编码 14746
rli->mts_wq_overfill_cnt,
//由于work 分配队列已满造成的等待次数 当前硬编码 16384
rli->wq_size_waits_cnt,
//大Event的个数 一般不会存在
rli->mts_total_wait_overlap,
//由于上一组并行有大事物没有提交导致不能分配worker线程的等待时间 单位纳秒
rli->mts_wq_no_underrun_cnt,
//work线程由于没有空闲的而等待的次数
rli->mts_total_wait_worker_avail);
//work线程由于没有空闲的而等待的时间 单位纳秒