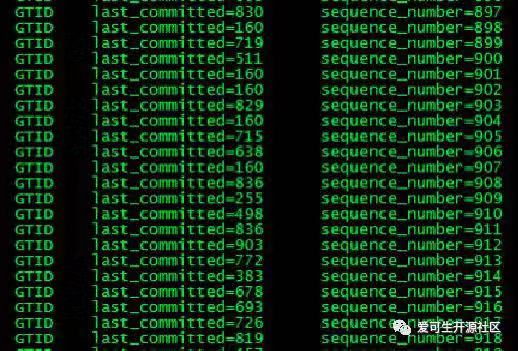
五、Writeset 设置对 last commit 的处理方式前一节我们讨论了基于 ORDER_COMMIT 的并行复制是如何生成 last_commit 和 seq number 的。实际上基于 WRITESET 的并行复制方式只是在 ORDER_COMMIT 的基础上对 last_commit 做更进一步处理,并不影响原有的 ORDER_COMMIT 逻辑,因此如果要回退到 ORDER_COMMIT 逻辑非常方便。可以参考 MYSQL_BIN_LOG::write_gtid 函数。根据 binlog_transaction_dependency_tracking 取值的不同会做进一步的处理,如下:ORDER_COMMIT:调用m_commit_order.get_dependency函数。这是前面我们讨论的方式。
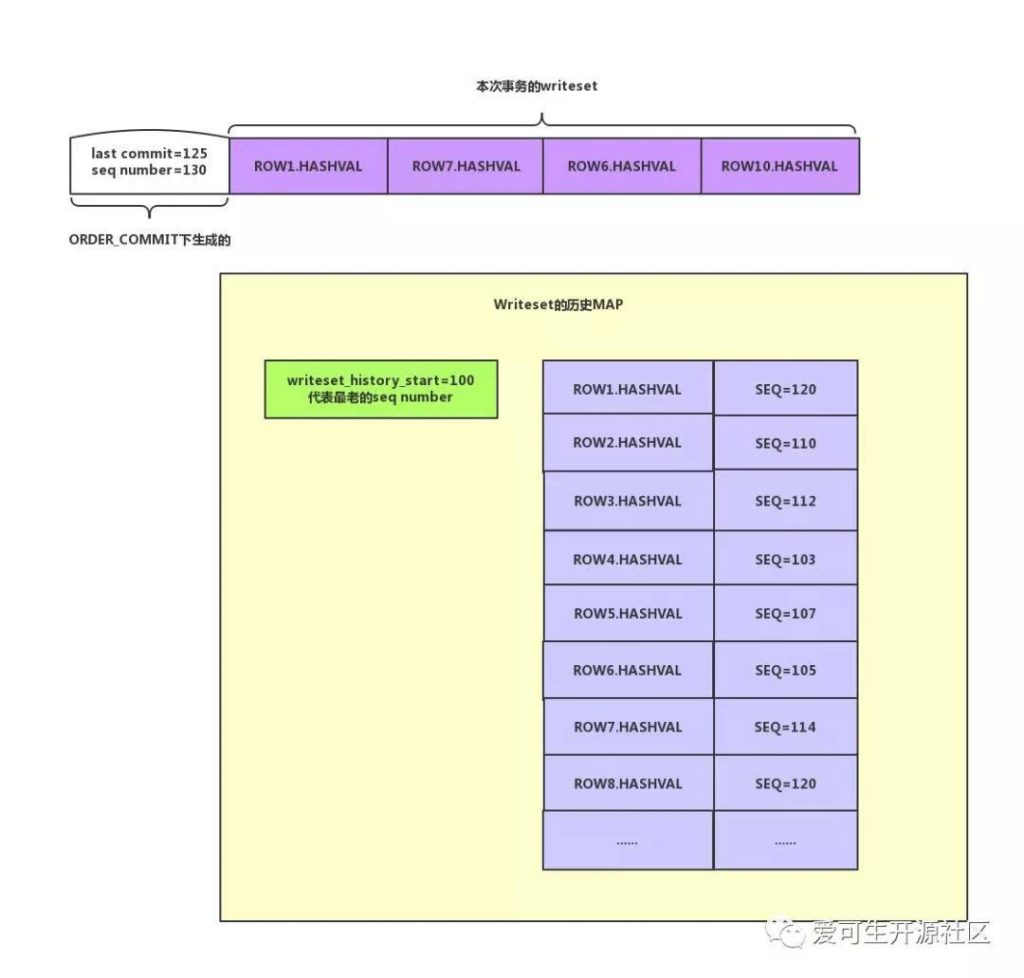
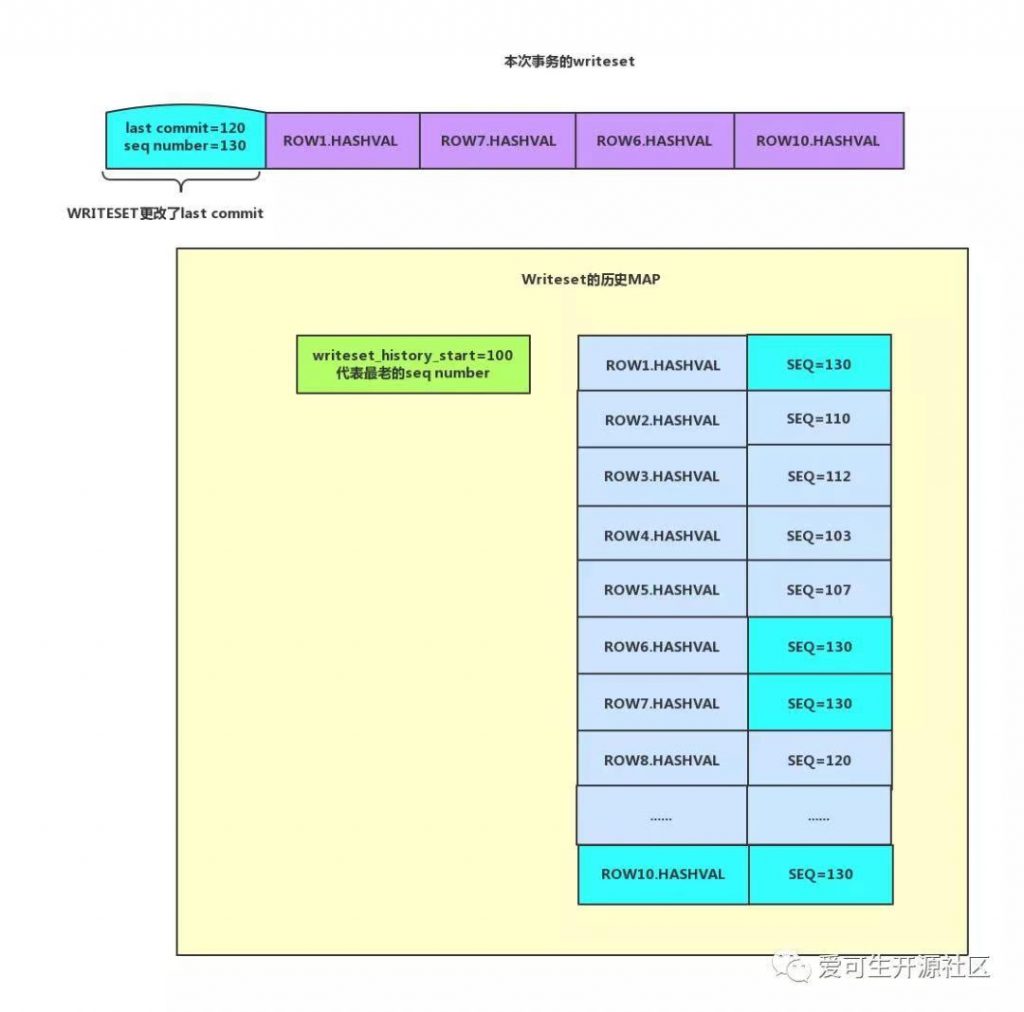
WRITESET:调用m_commit_order.get_dependency函数,然后调用m_writeset.get_dependency。可以看到m_writeset.get_dependency函数会对原有的last commit做处理。
WRITESET_SESSION:调用m_commit_order.get_dependency函数,然后调用m_writeset.get_dependency再调用m_writeset_session.get_dependency。m_writeset_session.get_dependency会对last commit再次做处理。
case DEPENDENCY_TRACKING_COMMIT_ORDER:
m_commit_order.get_dependency(thd, sequence_number, commit_parent);
break;
case DEPENDENCY_TRACKING_WRITESET:
m_commit_order.get_dependency(thd, sequence_number, commit_parent);
m_writeset.get_dependency(thd, sequence_number, commit_parent);
break;
case DEPENDENCY_TRACKING_WRITESET_SESSION:
m_commit_order.get_dependency(thd, sequence_number, commit_parent);
m_writeset.get_dependency(thd, sequence_number, commit_parent);
m_writeset_session.get_dependency(thd, sequence_number, commit_parent);
break;