近几个月来,NL2SQL 领域陆续发布了多个新数据集。根据目前公开的网络资料,SQLStorm[1]、CogniSQL[2]、RubikSQL 和 FinStat2SQL 四篇论文中提及了数据集发布信息。其中,RubikSQL 尚未公开源码及数据集,FinStat2SQL 也未明确说明是否会公开数据集。
因此,本文将重点介绍目前已可获取的 SQLStorm 和 CogniSQL 数据集。
什么是 SQLStorm?
SQLStorm v1.0[3] 是一个基于真实数据的大规模基准测试,包含三种不同规模(1 GB、12 GB 和 220 GB)的数据,覆盖超过 18,000 条查询。该基准首次采用人工智能生成查询负载,仅以极低成本(15 美元)就生成了海量(22 MB)且贴近真实场景的 SQL 查询,
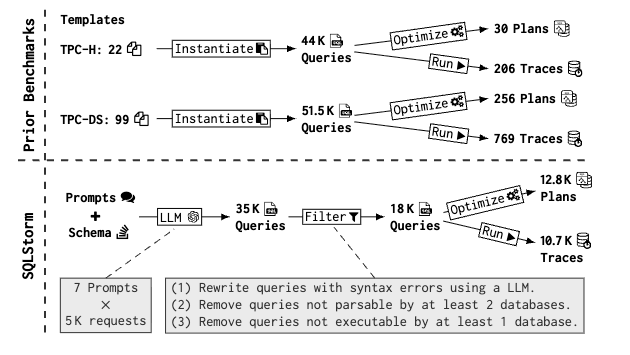
极大扩展了 SQL 功能与查询结构的覆盖范围。相比之下,传统人工编写的基准如 TPC-H、TPC-DS 和 JOB 在查询多样性和复杂度上均显不足。 SQLStorm 可用于以下场景:
-
提升不同系统之间的 SQL 兼容性; -
通过识别并修复系统崩溃或错误提高系统质量; -
借助查询执行趋势发现优化基数估计与查询优化器的机会; -
全面评估系统性能,包括执行速度与稳健性。
详细介绍
SQLStorm 使用大语言模型(LLM)生成用于数据库性能测试的 SQL 语句,旨在弥补传统数据集如 TPC-H 在 SQL 特征覆盖上的不足。该数据集兼容 PostgreSQL、Umbra 和 DuckDB 等主流数据库系统。数据部分基于 StackOverflow 提供的真实数据库,包括一组 Schema 和三种规模的数据:
-
StackOverflow DBA(1 GB) -
StackOverflow Math(12 GB) -
StackOverflow Full(222 GB)
查询语句的生成流程如下:
-
使用大模型生成约 35,000 条涵盖简单、中等和复杂类型的 SQL 语句; -
通过模型筛选,最终保留约 18,000 条高质量查询。
真实价值
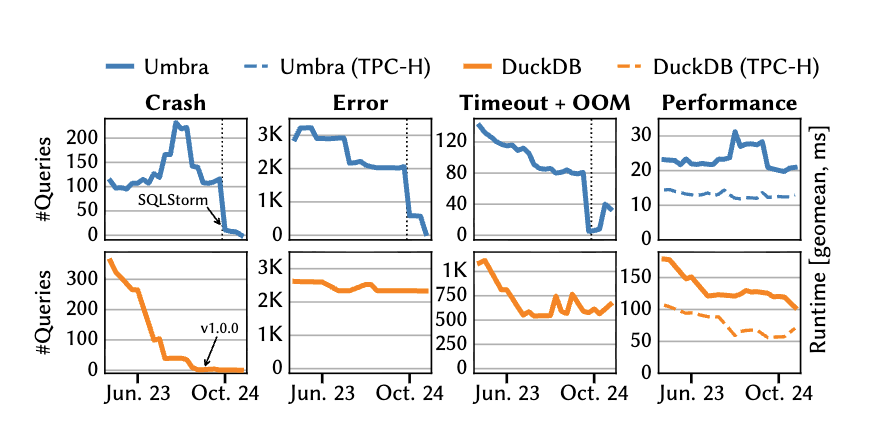
SQLStorm 能够以较低成本生成多样化 SQL,有效揭示数据库系统中的性能瓶颈和错误。例如,从引入 SQLStorm 之后,Umbra 通过修复 SQLStorm 中遇到的问题短时间内在 SQLStorm 的 Crash、Error,Timeout + OOM 等指标上得到了明显提升。并且通过查看第 4 组图,SQLStorm 发现了没有在 TPC-H 上体现出的性能退化问题,并且找到后修复了(注:Umbra 与 SQLStorm 似出自同一团队)。
小结
SQLStorm 也可以用来评估 SQL 优化之类的任务,借助 SQLStorm 已有的完整数据库的数据和样本,能有效评估 SQL 优化后的性能差异。另外也可以利用完整数据库的数据来评估不同 NL2SQL 生成的 SQL 在性能方面的质量。
什么是 CogniSQL?
CogniSQL[4] 发布了两类精选数据集,这些语料显著推动了与执行对齐的可扩展文本到 SQL 生成研究。通过开源这些资源,社区可直接利用高精度 SQL 样本和清晰推理路径,支持在有限计算资源下进行轻量级强化学习与推理增强的文本到 SQL 模型训练。
-
由 Qwen-QWQ-32B 生成的包含 5,024 条固定推理路径的训练集,能实现更好的可解释性和便于观测过程; -
由 Qwen2.5-7B-Coder 生成的 36,356 条正样本语料库,每条原始训练集都同时生成六条不同的训练集,训练集由推理过程和结果组成,以此来扩充推理路径。
详细分析
这两份数据集是论文中在 SFT 阶段使用到的数据集,其中在第一阶段使用了 Reasoning_Traces(由 Qwen-QWQ-32B 生成的 5024 条数据),在 SFT 之后,BIRD-dev 准确率从 ≈52.0%(基线)下降到 ≈46.0%;第二阶段,论文中尝试使用自生模型生成的数据 Positive_Sample_Corpus 进行 SFT。基于模型生成数据的 SFT 恢复了性能,获得了 ≈57.3% 的执行准确率——几乎与基线持平。这些结果表明,即使来自模型本身,高精度、分布均匀的样本也能使 SFT 受益。
真实价值
在数据集之外,该论文核心内容还是提出了 CogniSQL-R1-Zero 框架,在最终尝试实验了长 AI 代理流程,SFT,GRPO 后,最终使用 GRPO 方法进行强化学习训练以提升 NL2SQL 性能。实验表明,基于 Qwen2.5-7B-Coder 的 CogniSQL-R1-Zero 在 Bird-dev 上达到了 59% 的执行准确率,超越了参数量更大的基准模型(如 DeepSeek-Coder (236B) 和 Mistral (123B))。
小结
CogniSQL 的核心贡献在于通过小模型生成式方法构建了高质量的符合小模型推理轨迹和正样本语料,弥补了之前数据集缺乏符合小模型推理逻辑的空白,能够在低资源环境下通过 SFT 训练保持小模型的泛化能力。另外在数据集之外,论文还总结了一些大模型训练的经验:
-
零样本思维链(Zero-Shot CoT)效果有限:虽然 LLaMA 3.1 8B 能生成部分连贯的推理步骤,但仅有不到 20% 的 SQL 可正确执行,说明思维链与 SQL 生成之间存在显著差异。 -
多智能体流程成本过高:尽管多智能体协作在准确率上达到 85%,但其计算开销、延迟和系统复杂性难以适用于大规模实际场景。 -
监督微调(SFT)反而导致性能下降:使用蒸馏得到的推理数据对 Qwen-7B 进行 SFT 后,模型出现明显过拟合,准确率从 52.0% 降至 46.0%,泛化能力不足。 -
自生成数据有助于 SFT 恢复性能:通过采样并筛选模型自身生成的正确 SQL 进行 SFT,准确率回升至 57.3%,说明高精度、分布内数据对SFT的有效性具有关键作用。 -
混合方法(SFT+RL)稳定但非最优:冷启动后接 RL 训练虽收敛稳定且达到约 58.0% 准确率,但纯 RL 方法在峰值性能和工作流程简洁性方面表现更优。
[2] CogniSQL 论文: https://huggingface.co/datasets/CogniSQL/Reasoning_Traces
[3] SQLStorm 数据集: https://github.com/SQL-Storm/SQLStorm
[4] CogniSQL 数据集: https://huggingface.co/datasets/CogniSQL/Positive_Sample_Corpus