作者:xuty
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
一. 背景
记录下第一次使用 GDB 调试 ClickHouse 源码的过程,这里仅仅是通过简单的调试过程了解 ClickHouse 内部的机制,有助于解决疑惑,代码小白,有错误见谅。
二. 调试问题
调试 ClickHouse 主要是为了解决个人遇到的一个实际问题,下面先描述下这个问题:
-
通过 clickhouse 自带的 mysql表函数导入全量数据时(这里建了一张测试表memory_test,50w行数据56G),因为超过最大的内存限制(CK服务器36G内存),导致了如下报错。
localhost :) insert into `test`.`memory_test` select * mysql('192.168.1.1:3306','test','memory_test','root','xxxx');
Received exception from server (version 20.8.12):
Code: 241. DB::Exception: Received from 127.0.0.1:9000. DB::Exception: Memory limit (total) exceeded: would use 35.96 GiB (attempt to allocate chunk of 17181966336 bytes), maximum: 28.14 GiB: While executing SourceFromInputStream.
-
大致过程就是 ClickHouse 会将 mysql 的数据读入内存然后批量写入,这里涉及到一个 buffer 的问题,ClickHouse 会读入 多少行数据或者多少bytes的数据后再批量写入,根据show processlist观察来看,貌似达到100多w行数据就会写入一次,随后释放内存,再循环读写。那么我们的问题其实读取MySQL原表中100多万行的数据超过了我们 ClickHouse 内存配置大小。
-
关于这个问题,如果你CK服务器内存配置比较大其实是不会遇到的,我这里CK服务内存仅为32G,所以可能碰到这个内存问题,最简单的其实扩容下内存就行了,但是为了避免有些项目上不好进行内存扩容,所以需要想下其他方法解决。
-
最开始想到的是用 swap分区,但是实际测试下来,ClickHouse 只会用物理内存,不会用到虚拟内存。 -
第二个方式是通过 where条件+分页查询mysql,减小内存占用的峰值,实测有效,但是比较麻烦。
-
接着我想着是不是有什么参数可以控制这个批量写入的阀值,这样不就不会遇到内存不够的问题了嘛,100w会超过内存限制,50w应该就不会超过了把。但是我google了下并没有找到对应的参数,群里问了下也没人知道,没办法,只能去源码里找找看,这个值到底是不是写死的。
三. 打印栈帧
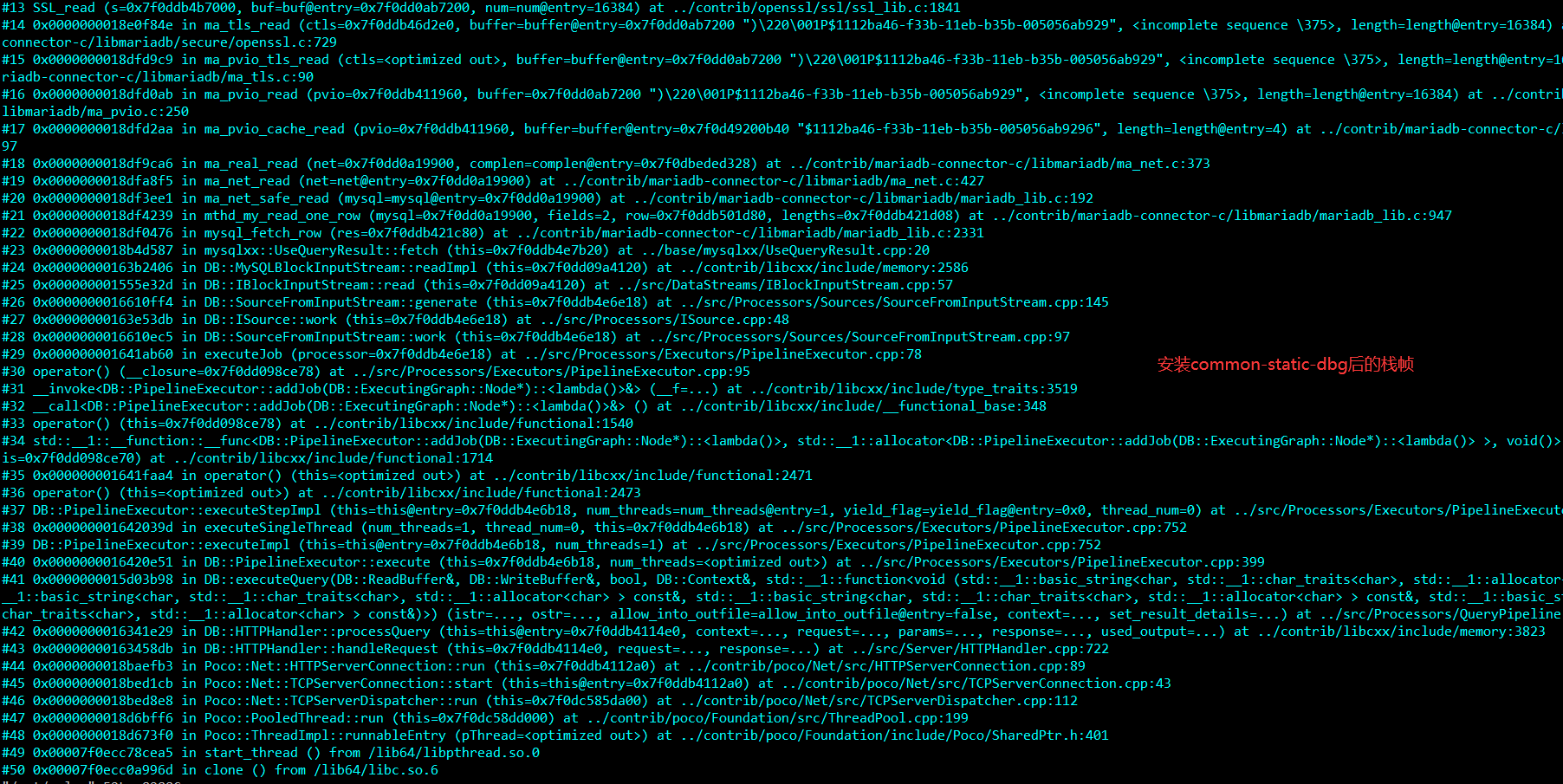
首先我们要通过 pstack 打印下堆栈信息,不然无法知道函数入口在哪,在这之前需要我们额外安装下对应 ClickHouse 版本的clickhouse-common-static-dbg的 rpm 包(调试库),不然堆栈信息会比较简陋,而且后面GDB调试也会有问题。
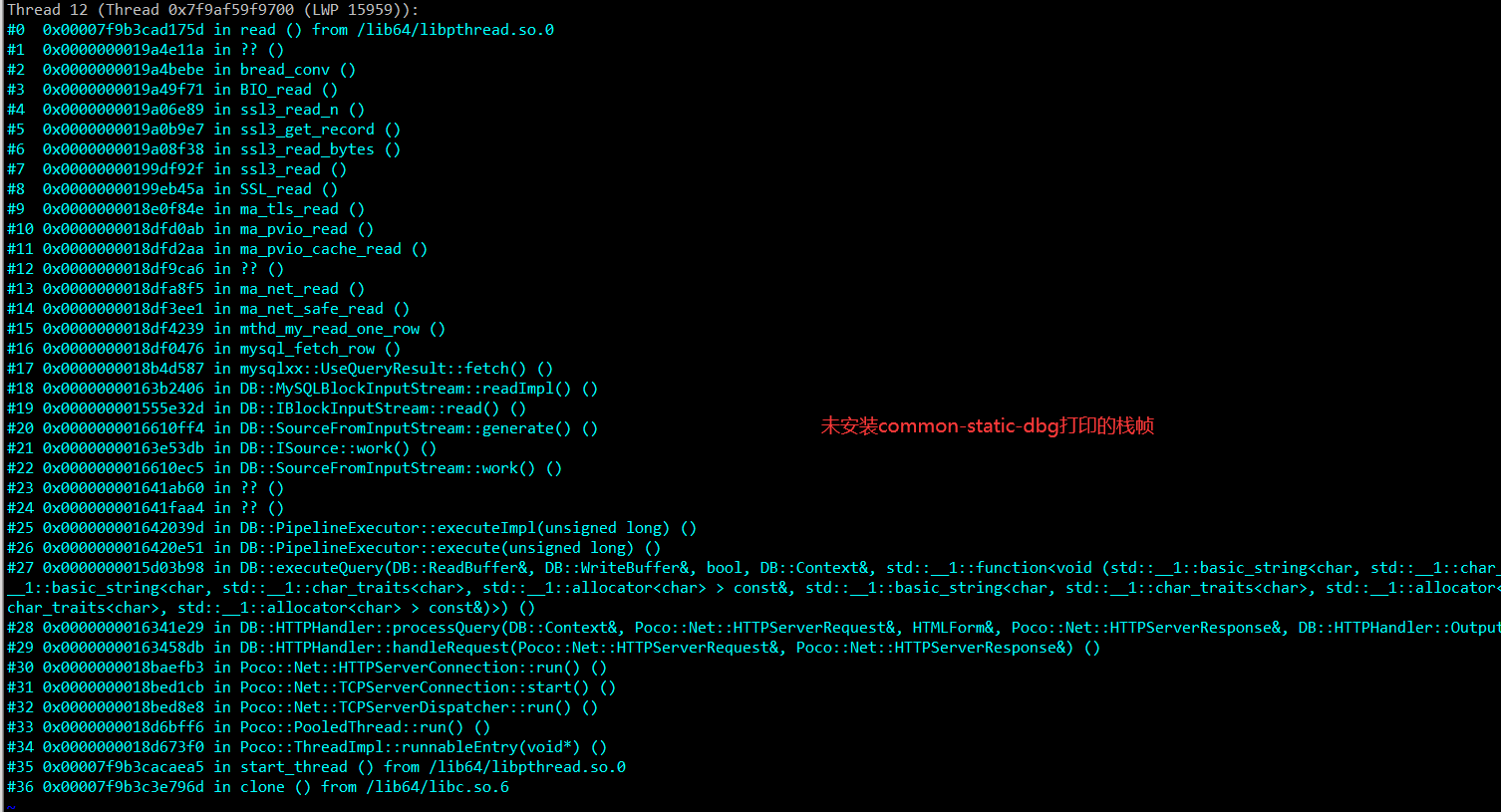
比如我的 ClickHouse 版本为 20.8.12.2 ,那么对应的rpm包就为clickhouse-common-static-dbg-20.8.12.2-2.x86_64.rpm
再 ClickHouse 中执行 insert 语句后,通过pstack + clickhouse进程pid > /opt/ck_pstack.log 导入到一个日志文件中。
四. GDB调试
GDB 不多介绍,不过个人更喜欢使用CGDB,使用 Yum 安装即可,我使用的 OS 版本是 CentOS7.9 。
使用 GDB 调试前,还需要将对应 ClickHouse 的源码下载后解压到/build/目录下(默认的编译目录)。
然后调试步骤大概是:
-
首先新建个窗口,clickhouse-client 连接进入 ClickHouse ,等待执行 SQL 。 -
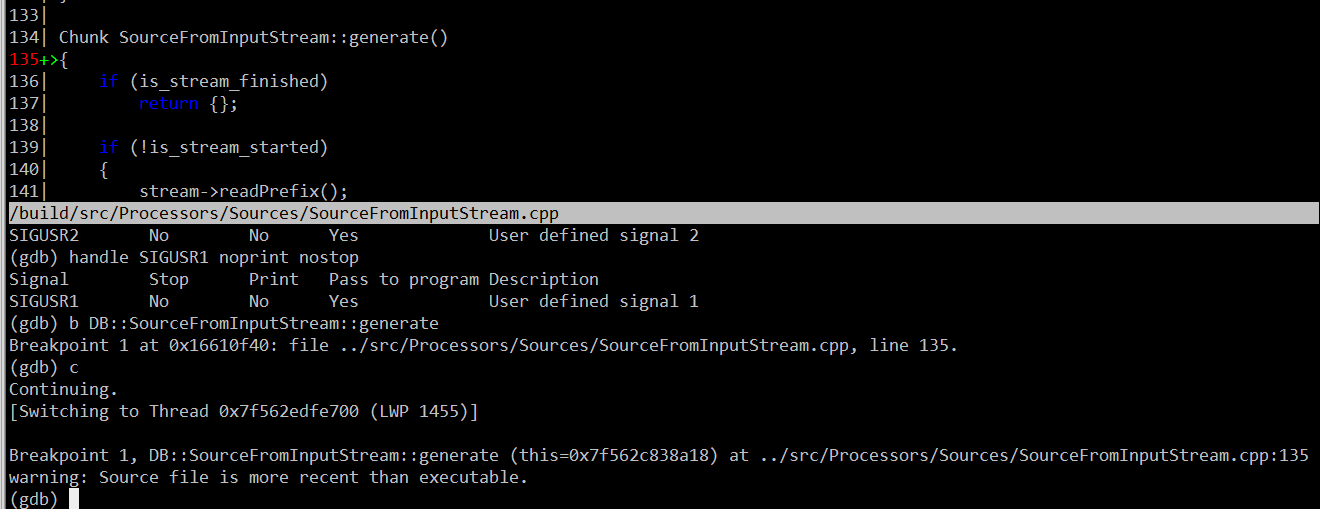
打开 CGDB ,attach 到 Clickhouse 的 pid 上,在对应函数行打上断点,这里选择的是 DB::SourceFromInputStream::generate(从栈帧中选择),CGDB 中需要配置忽略信号量,不然 CGDB 会一直断开。
(gdb) att 1446
(gdb) handle SIGUSR2 noprint nostop
Signal Stop Print Pass to program Description
SIGUSR2 No No Yes User defined signal 2
(gdb) handle SIGUSR1 noprint nostop
Signal Stop Print Pass to program Description
SIGUSR1 No No Yes User defined signal 1
(gdb) b DB::SourceFromInputStream::generate
Breakpoint 1 at 0x16610f40: file ../src/Processors/Sources/SourceFromInputStream.cpp, line 135.
-
在第一步骤打开的窗口中执行 insert 语句。 -
CGDB 中按 c 继续,就会跳到 generate 函数上
-
接着就是慢慢n,打印参数,一步一步看代码流程。
五. max_block_size
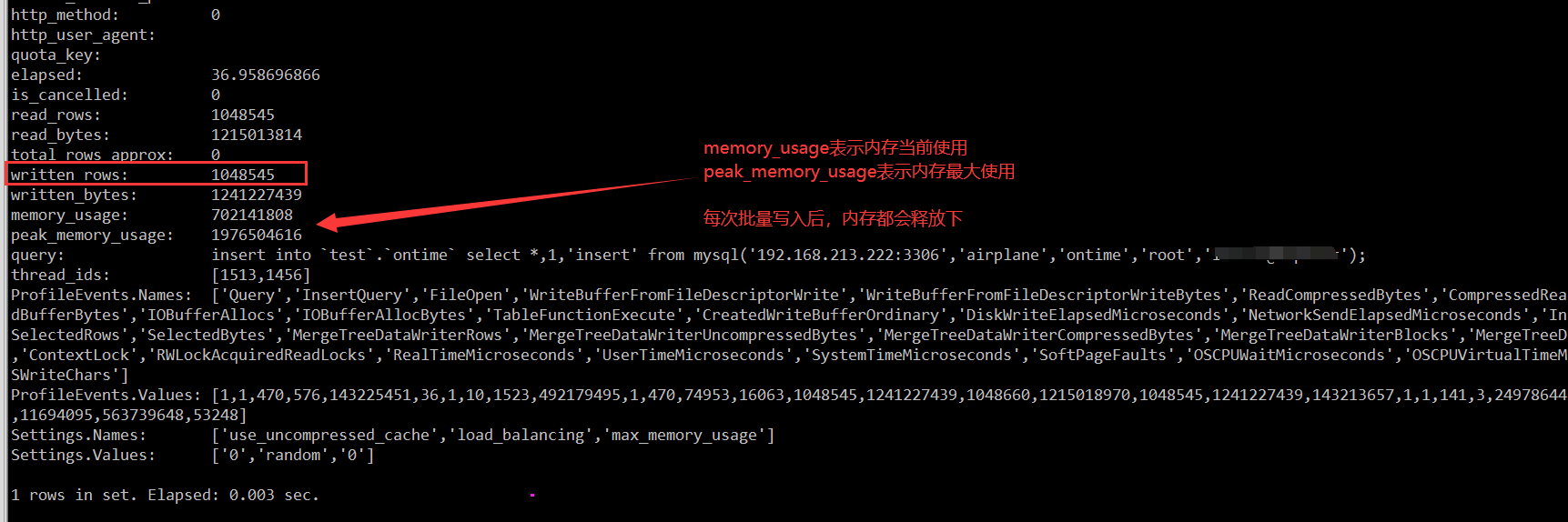
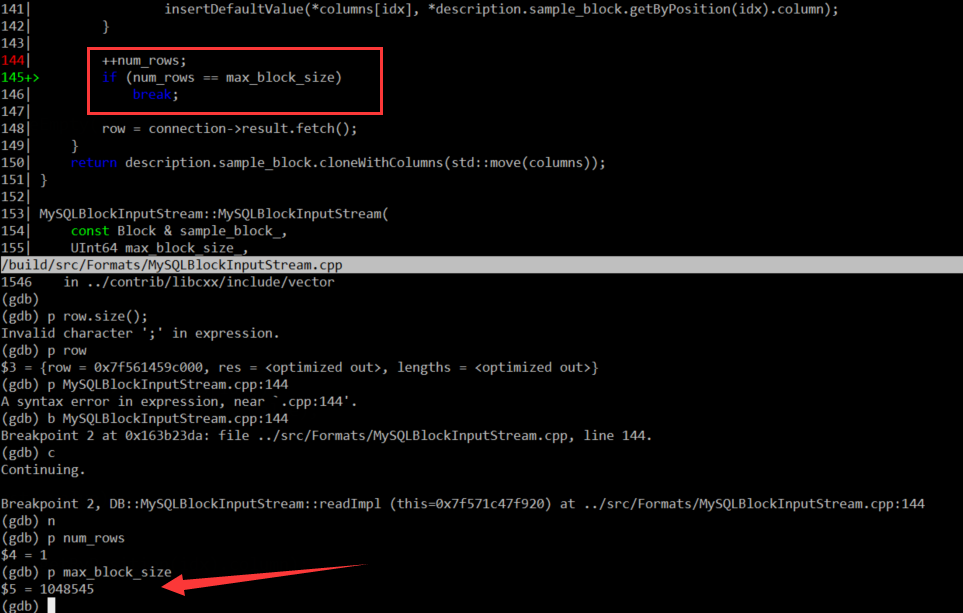
这里直接上调试发现的结果,当读取的行数等于 max_block_size 的时候,就会跳出循环读取,批量写入 ClickHouse ,释放内存,这个 max_block_size 的 GDB 打印的值为1048545,看着非常像是一个可以配置的参数。
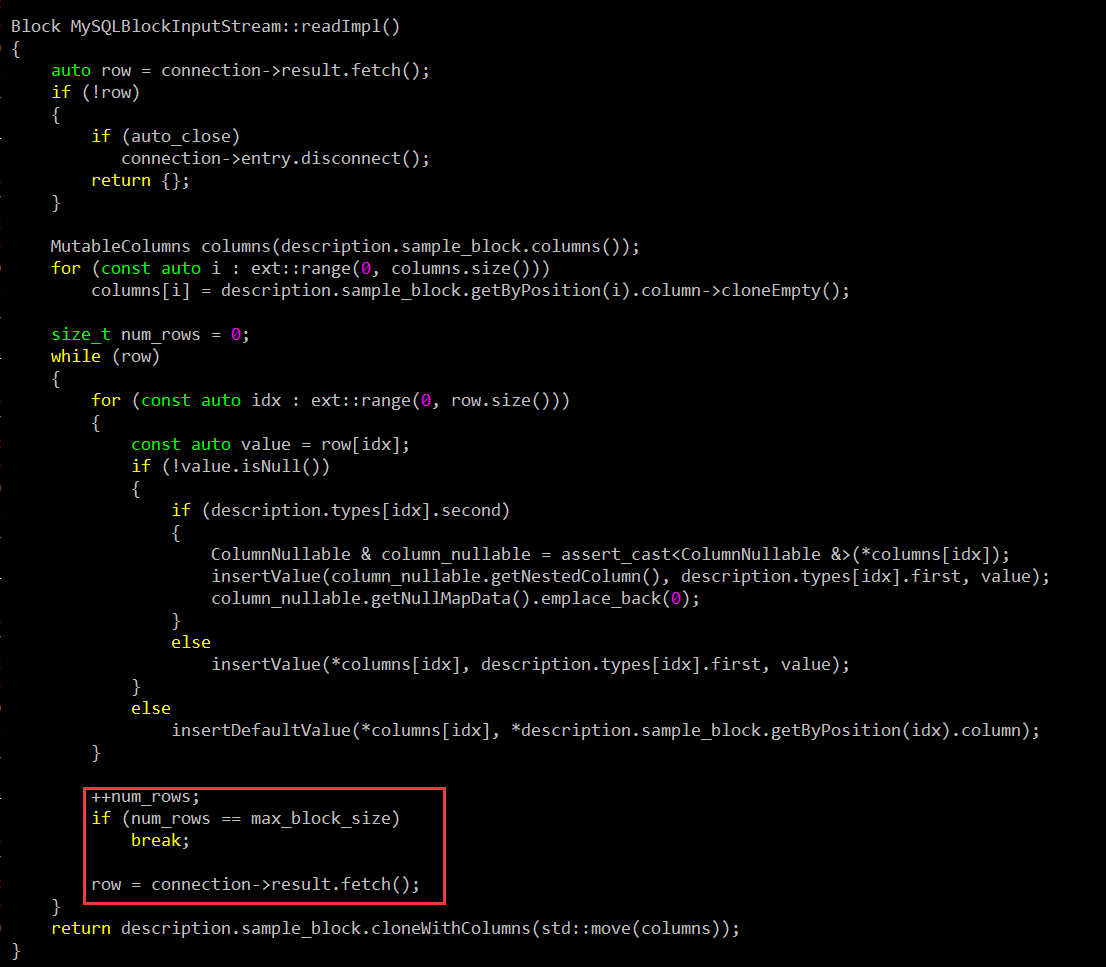
搜索源码中 max_block_size 的赋值,下面这段看着比较像,由min_insert_block_size_rows配置参数决定。
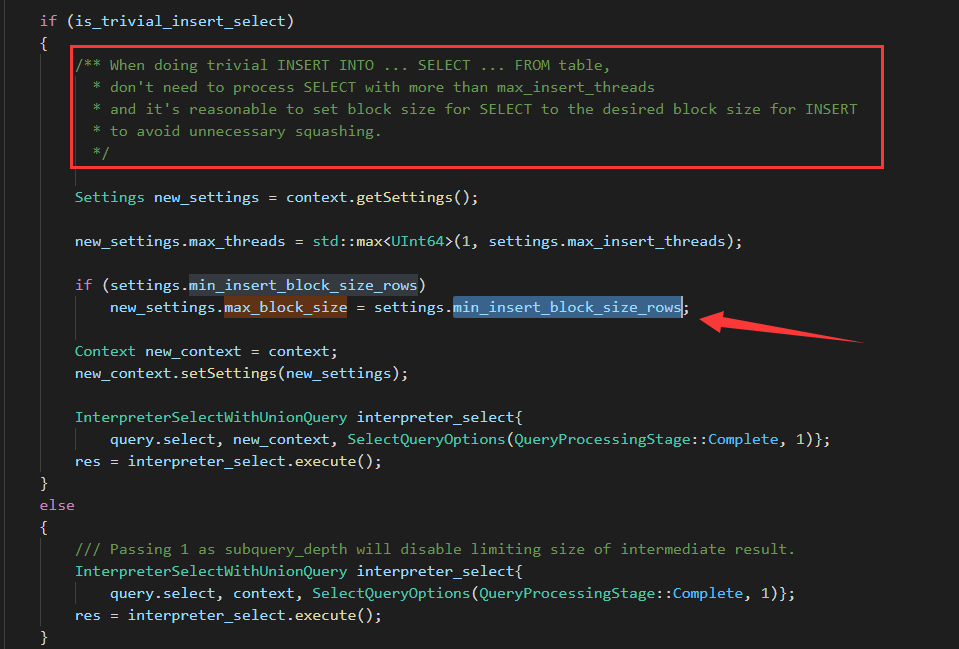
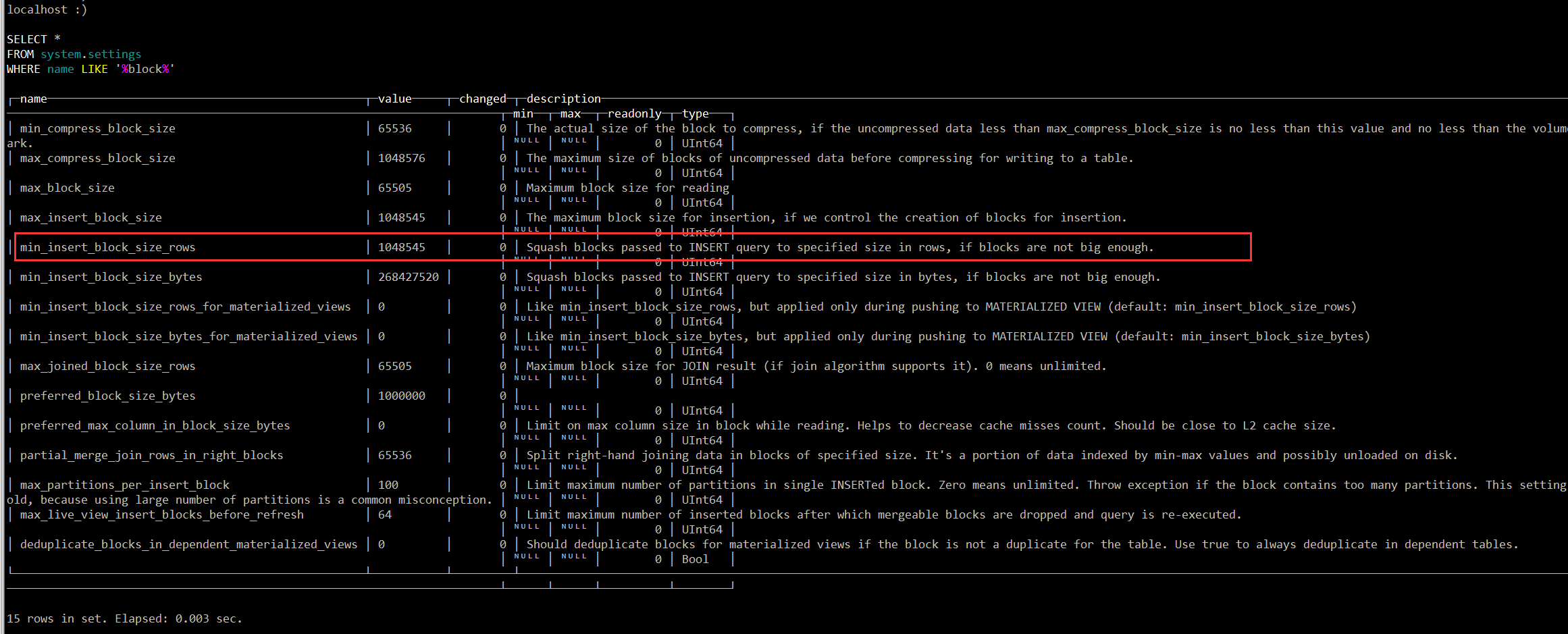
接着从 system.settings 表中搜索了下,发现 min_insert_block_size_rows 这个参数的描述和默认值确实都非常像,基本确定这个参数就会影响批量写入的行数。
六. 测试
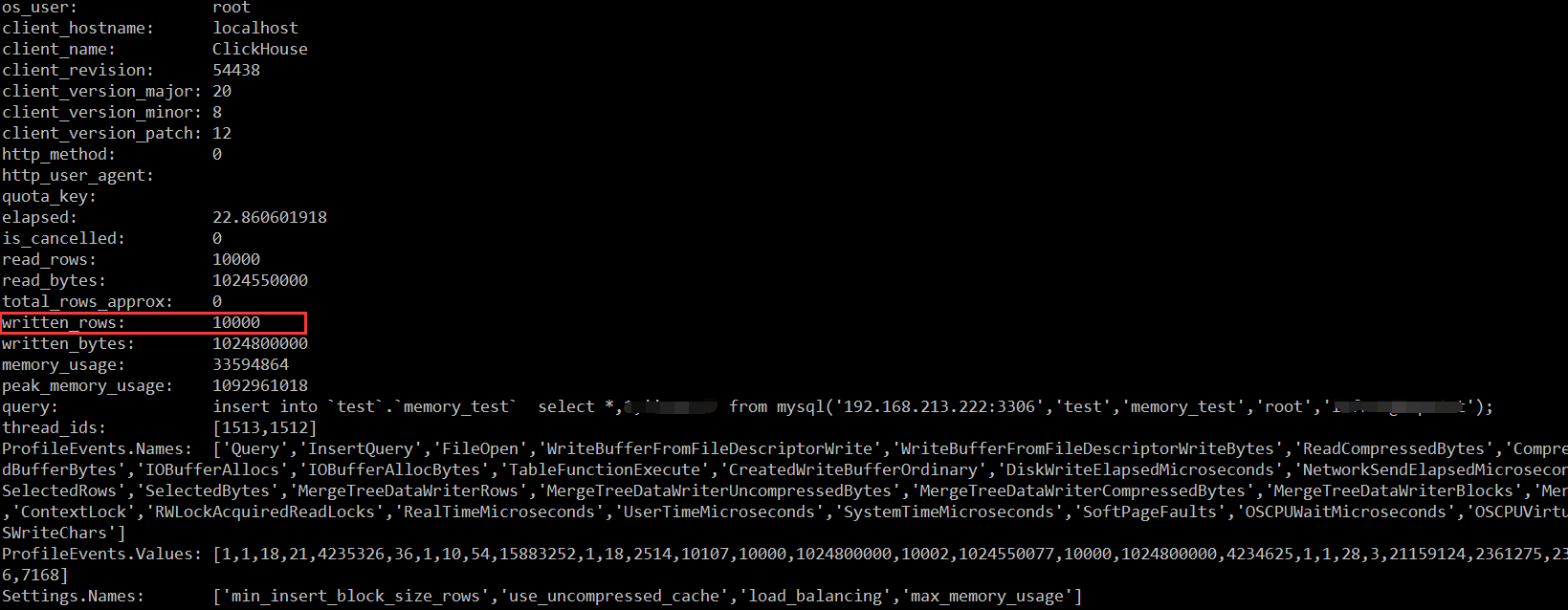
在会话中修改参数为1w,然后执行 insert ,可以跑通,而且不会报错。
localhost :) set min_insert_block_size_rows = 10000;
0 rows in set. Elapsed: 0.001 sec.
localhost :) insert into `test`.`memory_test` select * from mysql('192.168.213.222:3306','test','memory_test','root','xxxx');
INSERT INTO test.memory_test SELECT
*
FROM mysql('192.168.213.222:3306', 'test', 'memory_test', 'root', 'xxxx')
Ok.
0 rows in set. Elapsed: 2065.189 sec. Processed 500.00 thousand rows, 51.23 GB (242.11 rows/s., 24.81 MB/s.)
show processlist 也可以看到确实是1w行就写入,那么就不会再产生内存不足的问题,至此这个问题基本解决。