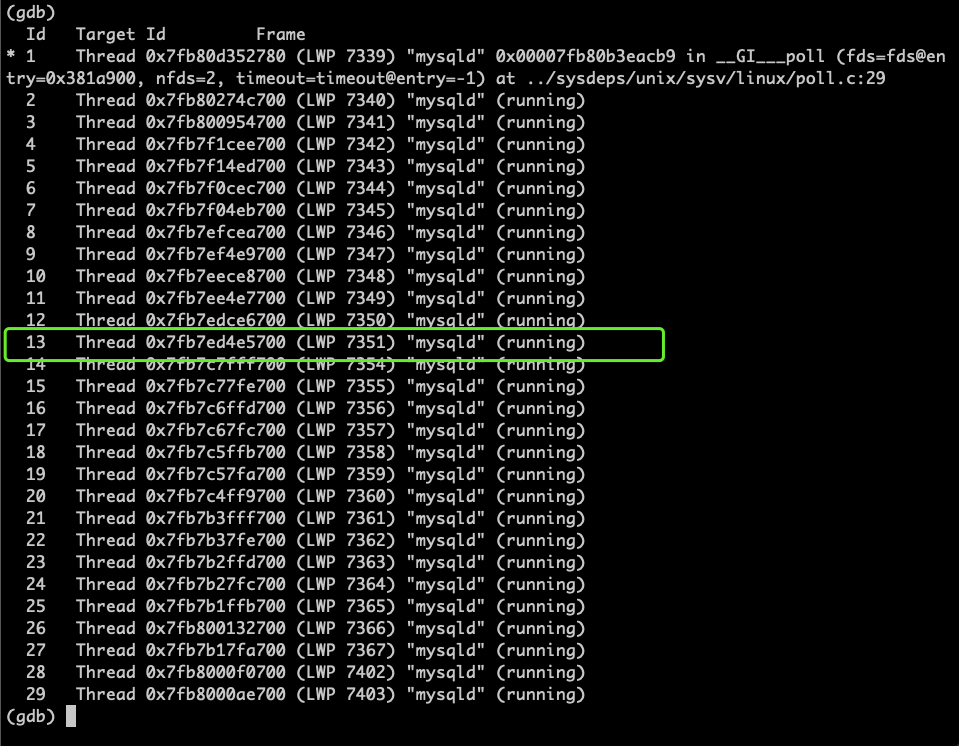
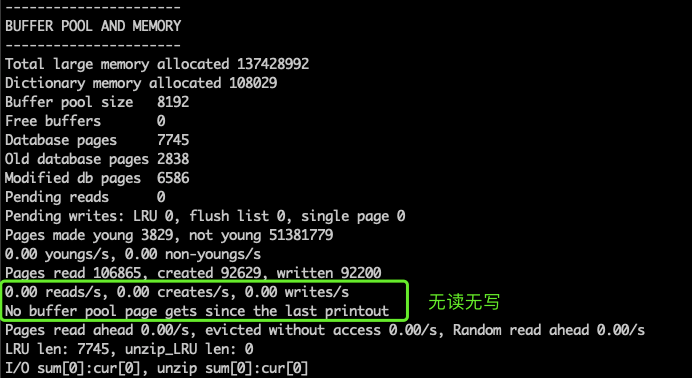
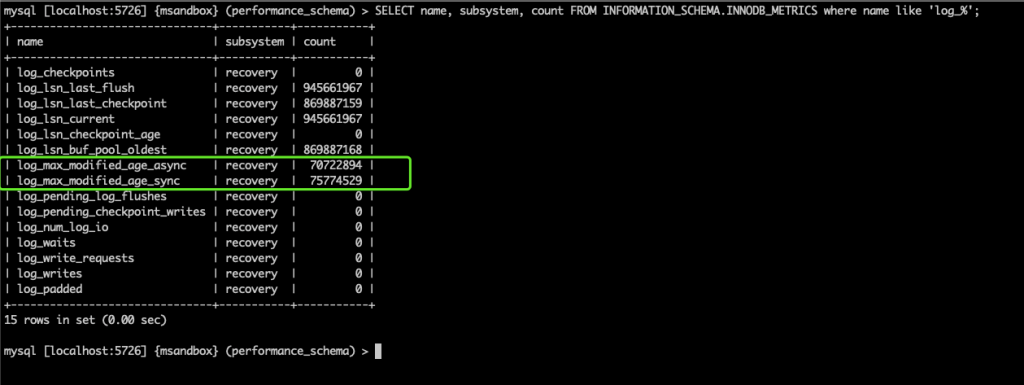
可以看到 innodb 定义的两条水位线:redo log 尚未 checkpoint 的日志大小(modified age)的水位线,一条异步水位线,一条同步水位线(这两条水位线是 innodb 自动算出来的,不要问为什么合理)
当超过异步水位线时,MySQL 开始调动 IO 尽力刷脏页,但业务仍能正常进行;当超过同步水位线时,将阻塞业务等待刷脏页。
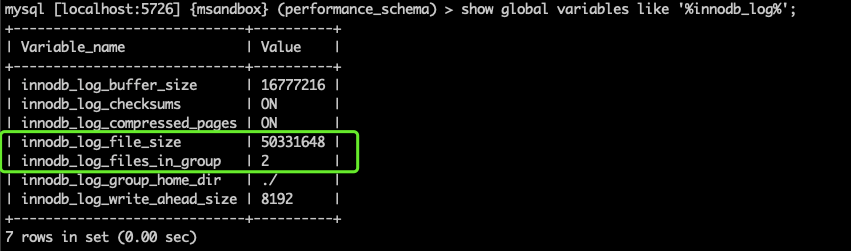
我们的场景下,modified age (=75774808) 刚好超过同步水位线,业务均开始阻塞。
至此,我们通过实验,验证了 innodb 刷脏页慢是会阻塞业务的。
江湖上一直有一个传说,处理 SQL 的线程会在紧急的状况下帮助刷脏页。
本实验中我们只停下了一个线程,大家也就可以验证这个传说不十分靠谱,所有的刷脏页都是通过专门的线程进行,处理 SQL 的线程只能提出刷脏页的需求,而不能直接动手。