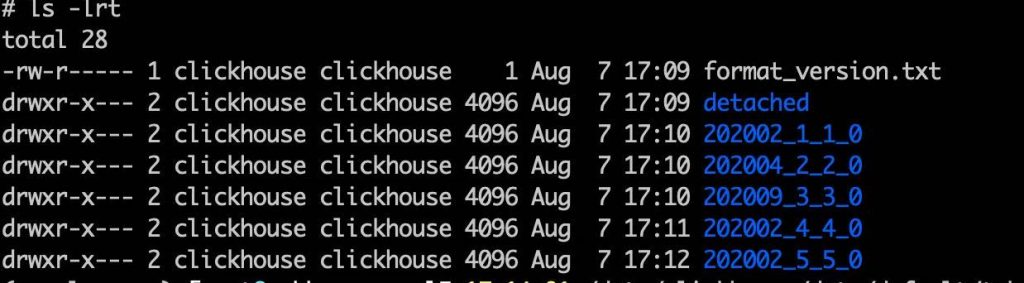
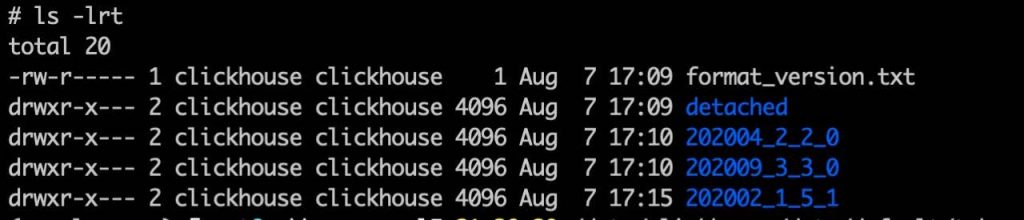
创建按照月份为分区条件的表 tab_partitionCREATE TABLE tab_partition(`dt` Date, `v` UInt8) ENGINE = MergeTree PARTITION BY toYYYYMM(dt) ORDER BY v;insert into tab_partition(dt,v) values ('2020-02-11',1),('2020-02-13',2);insert into tab_partition(dt,v) values ('2020-04-11',3),('2020-04-13',4);insert into tab_partition(dt,v) values ('2020-09-11',5),('2020-09-10',6);insert into tab_partition(dt,v) values ('2020-10-12',7),('2020-10-09',8);insert into tab_partition(dt,v) values ('2020-02-14',9),('2020-02-15',10);insert into tab_partition(dt,v) values ('2020-02-11',23),('2020-02-13',45);