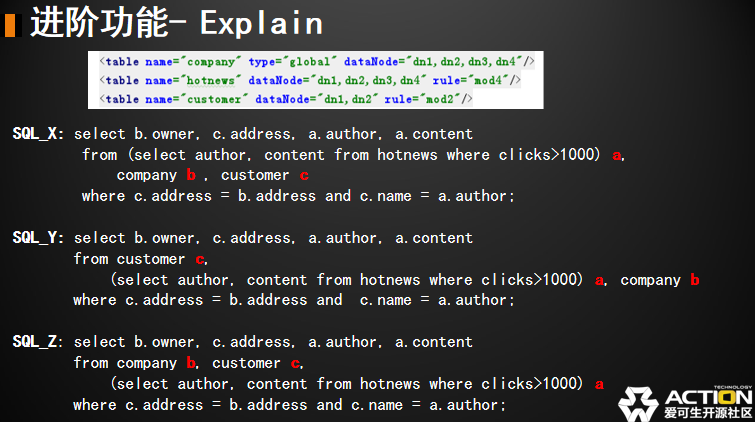
有三张表,表的配置不是很重要,重要的是下面这三个 SQL。这三个 SQL 大家如果仔细看的是第二层,唯一不一样就是 abc 的顺序。一个是 a 表 b 表 c 表,一个是 c 表 a 表 b 表,一个是 b 表 c 表 a 表。如果它们的结果是完全一样的,在 MySQL 当中的其实选哪种都没有关系,完全等价。但是在 dble 当中是不是这样?我们通过 explain 来看一下。
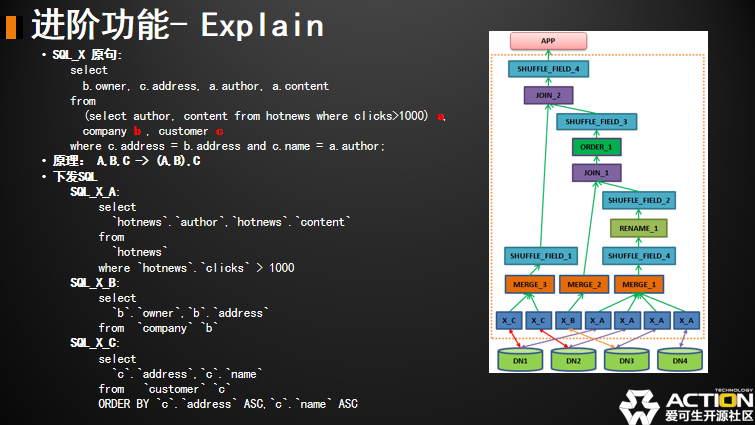
这是我们 Explain 执行第一条 SQL 的结果。结果比较长,就把长的先放一下。这样一个解表集就是把三张表的三个 SQL 下发下去。我们可以看到前两个 SQL 是不带 order 的,最后一个 SQL 是带 order by 的。看一下查询结果,因为这样看起来比较抽象,所以我们通过引用关系把它画成一棵树,上面是原句。
A 其实三个有 join,通过左契合的状态,A 表先和 B 表 Join,然后结果在和 C 表 Join。从右边的图也可以看的出来,我们按照表的顺序 X_A 是下发给四个节点。从四个节点默认回来以后,然后接一系列操作,比如 rename。因为原句当中 A 表是有子查询的,所以查完以后需要把别名换一下。然后再去做 Join,Join 的另外一边是 B 表,B 表是一个全局单表,然后去做 Join。Join 完毕的结果需要做一次排序,最后在同 C 表做 Join。C 表 Join 的时候,C 表是主表,生成结果再下发。这样我们就把刚刚的查询计划变成了一棵树。用于分析我们的查询计划是否合理。
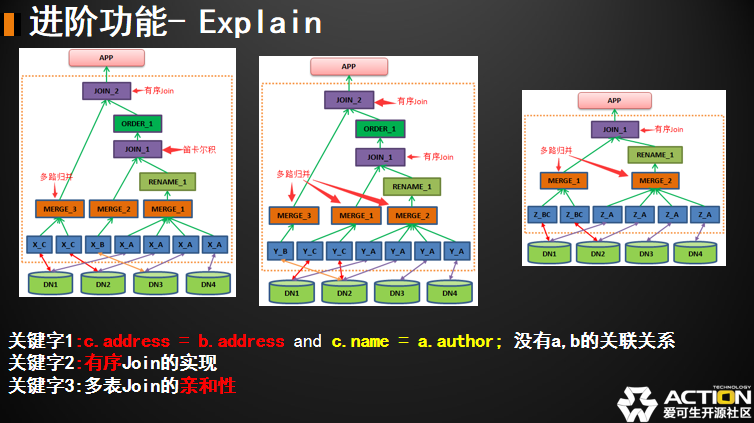
我们把三个 SQL 都转化为树,树的整体结构 A 和 B 基本上是一样。C 跟它们不一样。我们先来比较 A 和 B。比较 A 和 B 有什么不一样呢?A 表在第一次做 Join 的时候要做一个笛卡尔积。因为我的原句当中 ON 条件只有 C 的什么等于 B 的什么,C 的什么等于 A 的什么,A 和 B 之间是没有直接关系的。做完笛卡尔积需要转换为一个有序的序列跟另外一边有序的序列再做 Join,而我的第二张图 A 表先跟 C 表做 Join,A 和 C 没有关系,所以它就不需要做笛卡尔积。它只需要做一个有序的 Join,Join 出来再按照第二层 Join 关系排序,然后就可以返回结果集。
然后我们看第三张图其实没有那么复杂,只有一次 Join ,这是为什么呢?因为第三张图先做 B C 的。B C 中一张表是 Global 表,所以它其实是可以做部分优化。B 和 C 之间做 Join 其实可以先把 Global 表和另外一张表整体下发,下发之后的结果再 Join,其中一次 Join 是在 MySQL 节点上做的,并没有在这。如果大家去实测的话,从左往右越来越好的一个性能比较。
我们把这三张图拿出来再回述一下。为什么出现这种现象啊?有几个关键字需要注意。
第一个是我的 Join 关系,当我的 A 表和 B 表没有 Join 关系的时候,尽量不要把它们写在一起。因为 DBLE 现在做等价优化。如果等价优化还没有做好,不会去根据你真正的关联关系选择驱动表的,而是根据你 SQL 的顺序去选择驱动表。所以当两个没有关联关系的表放在一起并且放在前面的时候,直接就把它们俩做 Join 这样会造成一个笛卡尔积的计算,性能当然会差。
第二个是有序 Join 有序 Join 我们介绍了,其实就是避免在中间件做笛卡尔积。有排序下发在 MySQL 执行,然后我在中间件就不用做笛卡尔积了。