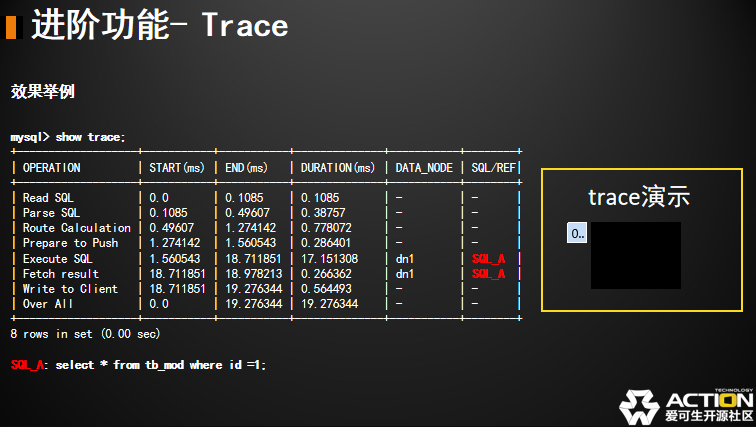
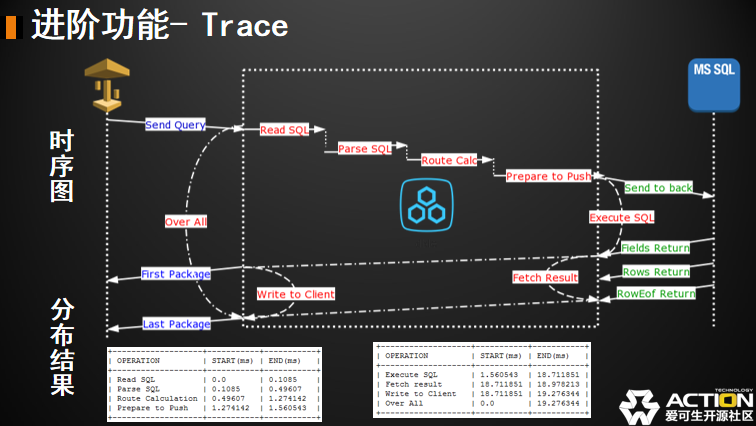
首先是一个客户端发送给我中间件的时间。这段时间对我来说是不可考量的,因为没有到我们中间件这一层,我是不知道花了多少时间的。但我们从经验判断,大概半个 RTT。如果 SQL 不是特别大的话,然后到了中间件层。我有读 SQL 的时间,我有解析 SQL 的时间,我有路由计算的时间,还有准备下发的一些准备工作。比如说:我去连接池里拿连接。这一部分我们管它叫前端的部分。然后,我们在中间件会分为前后端。前端的这一部分基本上是线性的,执行完一个才能执行后面一个。然后我就开始下发给 MySQL 了。
给 MySQL 以后,比如说我是一个 select 语句。我们可以想象一下 select 语句多行,不是一行。比如说有 100万行,那 MySQL 不可能同时返回,MySQL 协议是一行行回来的。有可能第一行到了,第二行还在路上。所以,我下面的结果会有一个 Fields Return。如果大家熟悉 MySQL 协议的话,知道结果集是先把列回来了,才会一行行去处理。
最后是行结束标记,所以我收到了第个MySQL结果包就开始统计时间了,直到我收到了最后一行是我 Fetch Result 这段时间。同样的,在我们这样一个简单的查询当中收到了一行,其实我已经可以往客户端开始写数据了。它是一个流式的,不需要等待所有的结果都出来。所以我们是可以往回写的,而直到我收到了最后一行,最后一行结束 RowEof,然后才可以把 Last Package 最后一个包写回去。我们总共的时间,其实是从我入 DBLE 这一侧 over all 时间。所以我现在所有的操作都是红色标记这一段的时间。如果你发现了性能问题,你就可以通过这个工具来分析问题。
案例分析
我们实际当中排查过一个案例。问题是三个节点,在这一部分时间其实就发给三个了,发给了三个以后,我们会看到有两个 Execute SQL 的时间大概是另外一个时间的二分之一。所以我们发现三个节点,有一个 MySQL 本身就慢。
而我们知道木桶原理,最慢的那个导致最后就慢了。排查后发现最后一个 MySQL 配置的参数不太对,把 MySQL 的参数调优达到了和另外两个 MySQL 一样的情况,最后这个性能就调整好了。但是也有可能有其它的原因,这个就需要具体分析了。