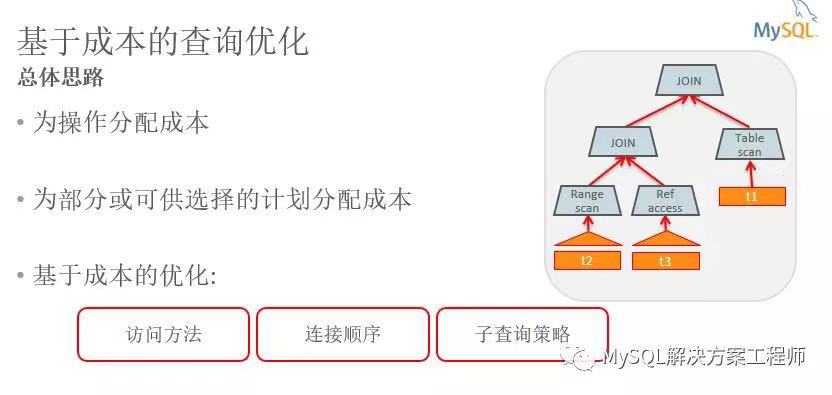
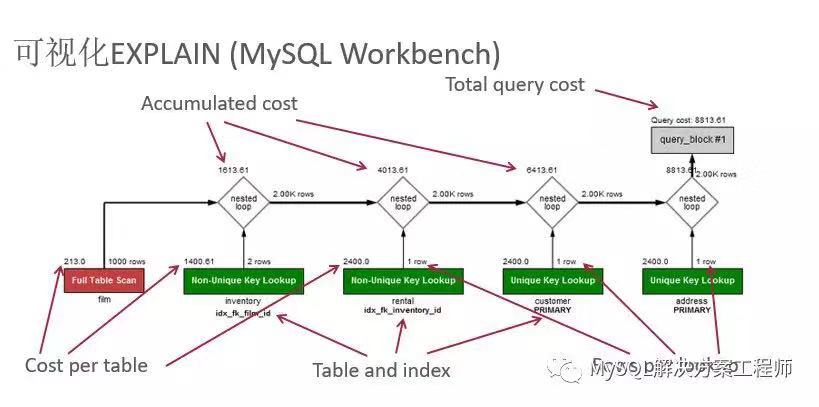
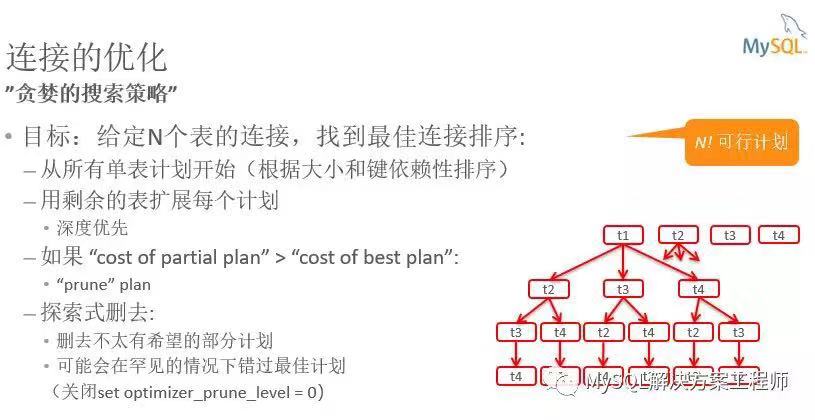
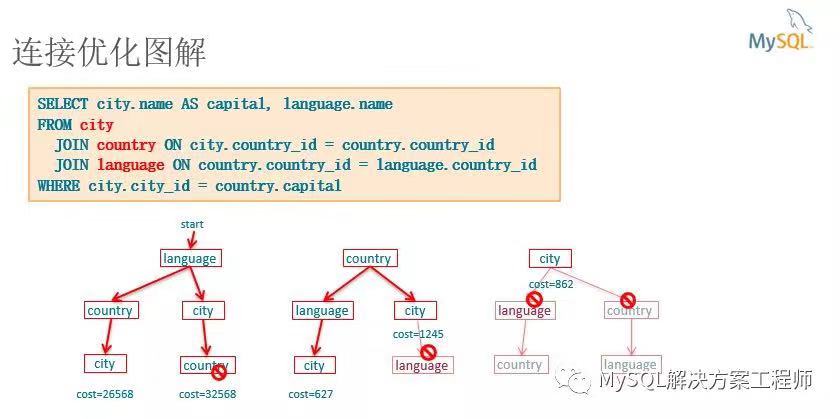
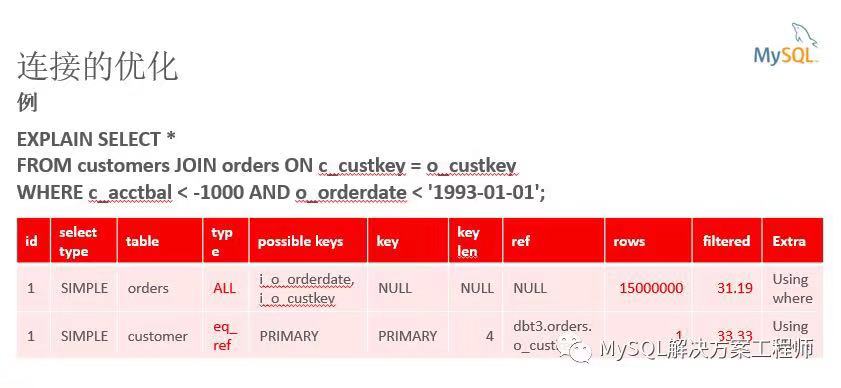
这是 MySQL 中成本模型的一个非常简单的视图。
作为输入,它需要基本操作,例如从表格读取数据或连接两个表格。作为输出,它产生对执行此操作的成本的估计。除了成本估算之外,它还会估算该操作产生的行数。成本模型由计算不同操作的成本和估计行数的公式组成。除了成本公式之外,成本模型还包含一组“成本常数”。这些是 MySQL 服务器在执行查询时执行的基本操作的成本。
成本模型使用来自数据字典的信息和来自存储引擎的统计信息来进行计算。主要的统计信息是表中的行数,对于索引,也获得基数,即有多少个不同的列值,以及索引范围中的行数。从数据字典中,我们使用关于行和索引的信息:如行和键的长度,唯一性以及列是否可以为空。
在 MySQL 5.7 中,已经配置了成本模型。成本常数存储在数据库表中,可以更改以更好地表示系统的特征。
使用这个模型,优化器在大多数情况下会选择一个最好的计划。但是,有时候优化器不能成功找到最佳计划。这可能是由于其决策所依据的数据不准确或由于成本模型本身的不准确性。