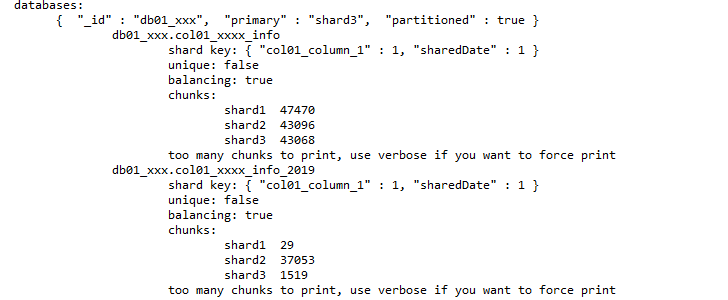
从sh.status()的输出中可以发现db01_xxx库中col01_xxxx_info和col01_xxxx_info_2019在后端各个shard的chunk数量已经严重不均衡,前者chunk数量之差47470-43068为4402个chunk,后者37053-29为37024个chunk,遇到这种情况,第一反应是看config primary的日志,MongoDB默认情况会开启balancer进程在各个shard之间迁移chunk来让shard间的chunk数量基本保持一致,chunk迁移的方向是从chunk数量最多的分片往chunk数量最少的分片迁移,在3.2版本及以下,balancer进程由Mongos发起,如果有多个Mongos进程,多个Mongos会竞争一把锁,谁获得锁谁就将获得运行balancer进程的权限,但是在3.4版本及以后,balance进程已经放在了config server的Primary节点,这样就不会有锁竞争这一过程了,查看config primary的在迁移窗口的日志有大量如下报错:
2019-05-27T00:04:06.140+0800 I SHARDING [Balancer] Balancer move db01_xxx.col01_xxxx_info_2019: [{ col01_column_1: "3177000047924787", sharedDate: new Date(1546561546000) }, { billingContractNo: "3177000049293528", sharedDate: new Date(1548383450000) }), from shard2, to shard1 failed :: caused by :: ConflictingOperationInProgress: Unable to start new migration because this shard is currently donating chunk [{ col01_column_1: "3177000525560227", sharedDate: new Date(1527215797000) }, { col01_column_1: "3177000525560227", sharedDate: new Date(1527217436000) }) for namespace db01_xxx.col01_xxxx_info to shard3
从日志得到以下信息:
1. 存储col01_xxxx_info_2019集合的chunk的迁移方向是从shard2往shard1迁移,shard2 chunk数量最多,shard1数量最少,现象符合。
2. 存储col01_xxxx_info集合的chunk的迁移方向是从shard1往shard3迁移(donating chunk),shard1数量最多,而shard3 chunk数量最少,现象符合。
3. 第1点失败的原因是第二点,原因是自动迁移的进程产生了冲突(ConflictingOperationInProgress)并等待,从而导致迁移失败。
该现象与MongoDB已知的BUG现象基本一致,该BUG表示当存在多个集合的自动的数据均衡操作时,分片节点不能同时作为源端和目标端,BUG链接为:Sharding balancer schedules multiple migrations with the same conflicting source or destination[链接1](相关链接见文末)