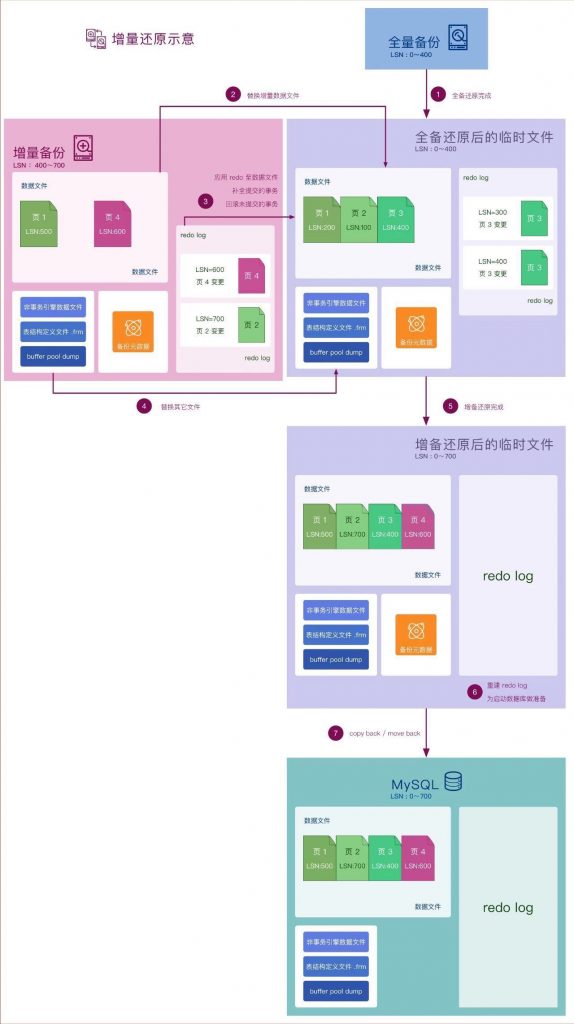
上一期文章介绍了全量备份和恢复的过程( [原理解析] XtraBackup全量备份还原 ), 先来回顾一下全量备份和恢复的要点:
1. 全量备份开始时,要监听并记录redo log的变化。
2. 全量备份拷贝InnoDB数据文件时,数据库同时会写入数据,导致数据文件的新旧程度不一致。
3. 拷贝InnoDB数据文件后,对数据库施加全局读锁后,才能拷贝非事务类型的信息,比如:binlog点位、非事务类引擎的数据文件等。
4. 全量恢复时,对InnoDB数据文件的不一致,通过将步骤1中记录的redo log的变化回放,可消除步骤2中的数据文件的新旧程度不一致的问题。