前言
当我们对 AI4SQL/AI4DB/DB4AI 类产品进行研究时,我们发现 SQL 领域应用能力的提升很大程度上依赖于高质量的数据集。
还需要在此基础上进行数据合成,生成针对特定问题的训练集和评估集。为了帮助更多开发者快速获取资源,我们将近年来公开的 Text2SQL/NL2SQL 数据集进行了整理清单,持续分享给大家!
上一期我们将带来 目前 DBA 还大幅领先 AI 的 SQL 能力的数据集的 BIRD-CRITIC[1],本期我们继续介绍两款与科学研究相关的数据集:BiomedSQL[2] 和 LogicCat[3]。
BiomedSQL
BiomedSQL 是一个专为评估大语言模型在科学表格推理任务上表现而设计的文本到 SQL 基准测试。它包含精心筛选的:问题/SQL 查询/答案 三元组,涵盖多种生物医学和 SQL 推理类型。该基准测试要求模型能够应用隐含的科学标准,而不仅仅是进行语法翻译。
相关论文[4]
数据集分析
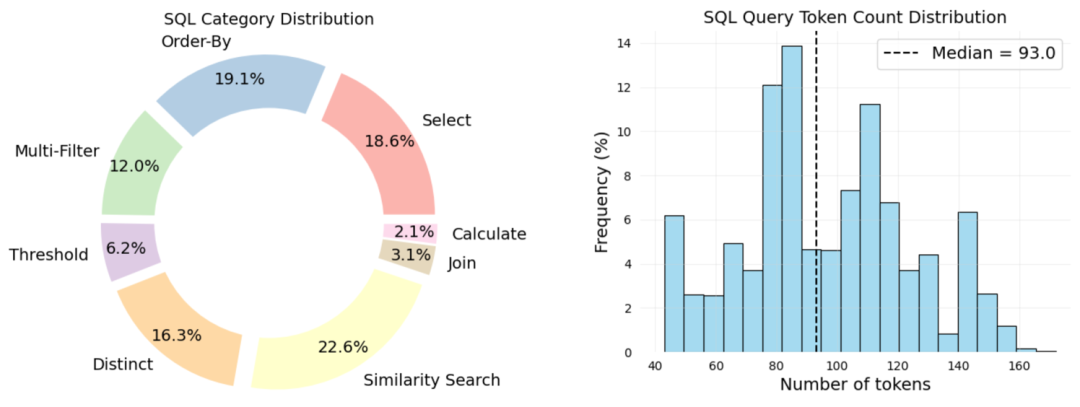
为表征 BiomedSQL 的科学和计算复杂性,作者对所有 68,000 个问题-查询对进行了 SQL 操作类型和生物医学推理类别的标注。较简单的操作,如选择、排序和计算——需要相对浅层的语法解析,大语言模型通常在这方面表现良好。相比之下,多条件过滤、阈值判断、表连接和相似性搜索等操作则更具挑战性,因为它们需要多步逻辑组合、隐式模式链接或基于模式的检索能力。
科学推理分类
为探究科学推理能力,我们将 BiomedSQL 查询划分为三类反映生物医学专家典型认知过程的推理类型:
-
隐式科学规范的具象化:查询常涉及领域特定概念(如”显著相关的 SNPs”),这些概念暗示着不明显的统计阈值,例如全基因组关联分析显著位点的 p<5×10⁻⁸ 阈值或基于 β 系数的方向性判断。这些规范很少在数据库模式中明确说明,必须由模型自行推断。 -
缺失上下文知识的整合:专家经常整合辅助数据(如药物批准状态或临床试验阶段),即使问题未直接提及。例如,判断某药物是否对特定适应症”获批”,需要解析适应症特定的试验阶段信息——这远超简单的二元”获批”标志。 -
复杂多跳推理工作流的执行:BiomedSQL 中许多问题需要跨多张表串联关系操作。例如”帕金森病相关基因在哪些组织中表达最显著?”这一问题,需要经过基因-疾病关联、基因表达、组织注释和统计排序的四步推理。大语言模型往往难以将这类多跳逻辑转化为有效可执行的 SQL 语句。
小结
这是首个专门为评估生物医学领域中 SQL 生成过程中的科学推理而设计的大规模文本到 SQL 基准。论文实验表明,BiomedSQL 对当前最先进的 LLMs 构成了重大挑战,执行准确率和答案质量仍远远落后于领域专家的表现。通过聚焦于隐含的领域惯例、多步推理和结构化的生物医学数据,BiomedSQL 突出了当前系统的关键局限性,并为未来的研究提供了严格的测试平台。
LogicCat
LogicCat 是一个具有挑战性的 Text-to-SQL 数据集,旨在测试复杂的推理能力,包括物理、算术、常识和假设性推理。该数据集包含 4,038 个英文问题及其对应的 SQL 查询,并附有 12,114 个逐步推理标注,涵盖 45 个不同领域的数据库。

实验表明,当前最先进的模型在该数据集上表现不佳,仅达到 14.96% 的执行准确率,但引入思维链标注后,性能提升至 33.96%,凸显了其在推动推理驱动的 SQL 生成研究方面的潜力。
相关论文[5]
数据集分析
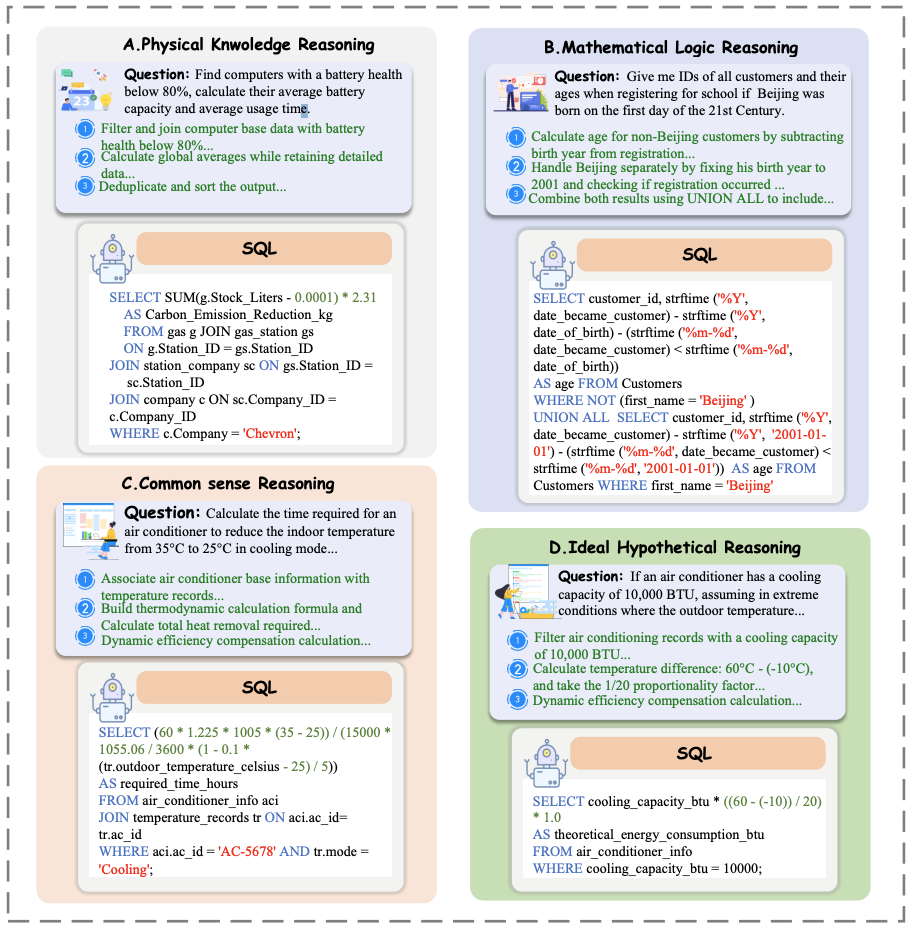
LogicCat 包含四种推理类型:
-
物理知识推理
侧重于解决需要运用物理公式和单位感知计算的物理问题,测试模型在多步推理中应用物理原理的能力。 -
数学逻辑推理
涉及运用算术、逻辑和分析思维解决数学问题,特点是计算步骤密集且常需对数据值进行操作。 -
常识推理
要求模型基于隐性的现实世界知识推断缺失细节,生成符合逻辑的 SQL 查询,有助于零样本学习并提升模型可解释性。 -
理想假设推理
测试模型在未见过场景中进行反事实和想象性思维的能力,通过复杂的条件关系挑战模型的理解与推理能力。
小结
尽管现有的数据集(如 Spider、BIRD 等)在 SQL 语法解析和执行方面提供了挑战,但它们在评估深度逻辑推理和计算能力方面存在局限性。这些数据集通常缺乏对特定领域知识和复杂数学推理的覆盖,无法充分评估模型在实际应用中所需的高级推理和精确数值计算能力。
为了解决这一问题,LogicCat 数据集旨在通过包含物理、数学、常识和假设推理等多领域复杂推理任务,推动 Text-to-SQL 模型在逻辑推理和领域知识整合方面的发展。
后续更新
我们将继续介绍高质量数据集,敬请期待。