作者:Rebooter.S
原文:https://sqlflash.ai/blog/sql-llm-dataset/,May 20, 2025
爱可生开源社区翻译,本文约 1600 字,预计阅读需要 5 分钟。
前言
当我们对 AI4SQL/AI4DB/DB4AI 类产品进行研究时,我们发现 SQL 领域应用能力的提升很大程度上依赖于高质量的数据集。
还需要在此基础上进行数据合成,生成针对特定问题的训练集和评估集。为了帮助更多开发者快速获取资源,我们将近年来公开的 Text2SQL/NL2SQL 数据集进行了整理清单,持续分享给大家!
我们按照时间顺序整理了数据集的论文和数据集地址,包括近年来具有代表性的数据集。其中,评估集的代表:Spider、BIRD-SQL,我们还在列表中关联了排行榜。
2025 年 3 月
2025 年 3 月,有以下 3 款数据集发布!
NL2SQL-Bugs
NL2SQL-BUGs 是首个专注于检测 NL2SQL 翻译中语义错误的基准数据集,旨在解决现有模型生成的 SQL 查询存在系统无法识别的语义错误问题。该数据集通过专家标注构建了两级分类体系(9 个类别和 31 个子类别),包含 2018 个带有错误标注的实例。

实验发现,当前大型模型的平均检测准确率仅为 75.16%,并成功识别了 Spider 和 BIRD 基准测试中存在的 122 个标注错误。该成果为 NL2SQL 系统的错误检测与纠错提供了重要的验证集。
相关链接:论文[1] / 数据集[2]
OmniSQL
SynSQL-2.5M 是 OmniSQL 论文中发布的数据集,作者认为这是目前最大的跨领域文本到 SQL 的合成数据集。它采用纯合成数据技术构建,包含 250 万个高质量样本,涵盖 16,583 个数据库和大量多样化的 SQL 语法结构。
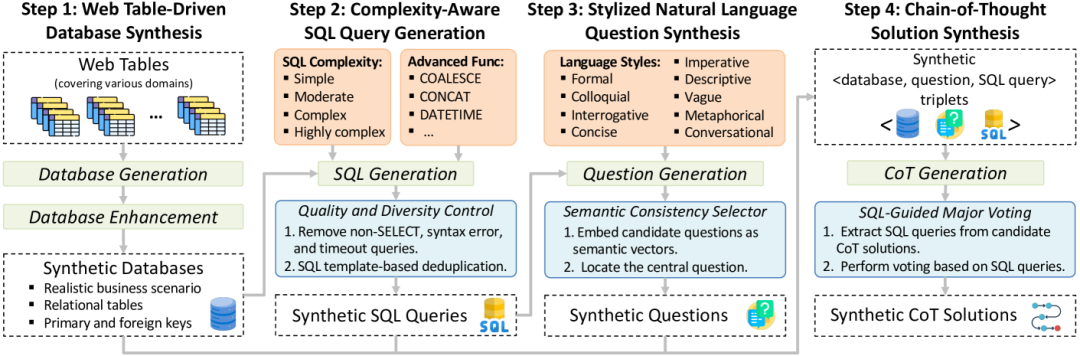
该数据集基于开源大模型生成,提供可直接用于训练的高质量数据,并遵循 Apache 2.0 许可开放。OmniSQL 系列大模型(7B/14B/32B)也同步发布,开发者也可以使用该数据集训练自己的模型。
相关链接:论文[3] / 数据集[4]
TINYSQL
TinySQL 是一个渐进式的文本到 SQL 数据集,旨在解决现有 SQL 数据集过于复杂,不适合机制可解释性研究的问题。通过控制 SQL 命令和语言变体的复杂性,它提供从基础到高级的查询任务,支持模型行为分析。
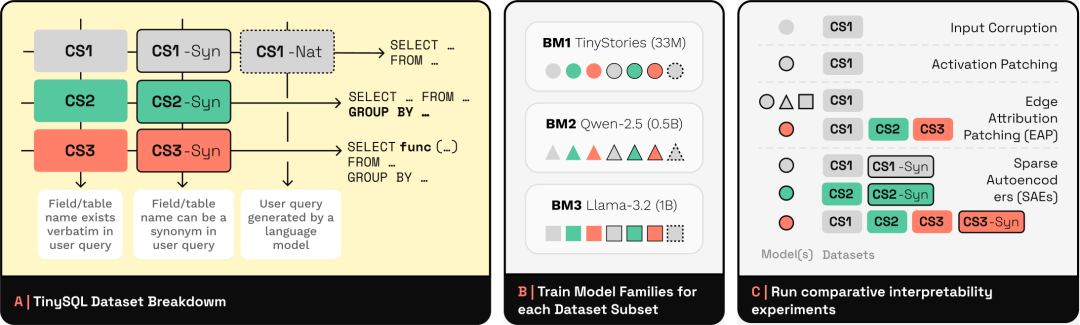
该数据集有助于研究人员理解 Transformer 如何学习和生成 SQL 查询,并评估可解释性方法的可靠性。应用场景包括模型机制分析、可解释性技术验证以及合成数据集设计的改进。
相关链接:论文[5] / 数据集[6]
2025 年以前
2025 年之前的 20 个数据集,我们可以通过发布时间线,一览 Text2SQL 数据集发展的历史和它们之间的联系。
WikiSQL
2017 面 9月,Salesforce 提出了一个大型 Text2SQL 数据集 WikiSQL,数据来自维基百科,属于单一领域,包含 80,654 个自然语言问题,77,840 条 SQL 语句。SQL 语句形式比较简单,不包含排序、分组和子查询等复杂操作。
相关链接:论文[7] / 数据集[8]
Spider 1.0
2018 年 9 月,耶鲁大学提出了多库多表、单轮查询的 Text2SQL 数据集 Spider,也是业界公认的最难的大规模跨领域评测榜单,包含 10,181 个自然语言问题和 5,693 条 SQL 语句。
相关链接:论文[9] / 排行榜[10]
SParC
2019 年 6 月,耶鲁大学提出了一个大型数据集 SParC,用于复杂、跨领域、上下文相关(多轮)的语义解析和文本到 SQL 任务,该数据集由 4,298 个连贯的问题序列组成(12k+ 个独特的单独问题,由 14 名耶鲁学生用 SQL 查询注释),这些问题是从用户与 138 个领域的 200 个复杂数据库的交互中获得的。
相关链接:论文[11] / 排行榜[12]
CSpider 中文
2019 年 9 月,西湖大学提出了一个大型中文数据集 CSpider,用于复杂跨域语义解析和文本到 SQL 的任务,该数据集由 2 名 NLP 研究人员和 1 名计算机科学专业的学生从 Spider 翻译而来,包含 10,181 个问题和 5,693 个独特的复杂 SQL 查询,涉及 200 个数据库和多个表,涵盖 138 个不同的领域。
相关链接:论文[13] / 排行榜[14]
CoSQL
2019 年 9 月,耶鲁大学和 Salesforce Research 提出了一个跨域数据库 CoSQL,它由 30k+ 个回合加上 10k+ 个带注释的 SQL 查询组成,这些查询来自 Wizard-of-Oz (WOZ) 集合中的 3k 个对话,查询了跨越 138 个域的 200 个复杂数据库。
相关链接:论文[15] / 排行榜[16]
KaggleDBQA
2021 年 6 月,KaggleDBQA 是一个具有挑战性的跨领域、复杂的真实 Web 数据库评估数据集,具有领域特定的数据类型、原始格式和不受限制的问题。
相关链接:论文[17] / 数据集[18]
Spider-Syn
2021 年 6 月,Spider-Syn 是一个基准数据集,旨在评估和增强 Text2SQL 模型在自然语言问题中同义词替换的鲁棒性。Spider-Syn 由伦敦玛丽女王大学的研究人员及其合作者基于原始 Spider 数据集开发。
相关链接:论文[19] / 数据集[20]
SEDE
2021 年 6 月,SEDE(Stack Exchange Data Explorer)是一个全新的文本转 SQL 任务数据集,包含超过 12,000 条 SQL 查询及其自然语言描述。它基于 Stack Exchange Data Explorer 平台用户的真实使用情况,带来了其他语义解析数据集前所未有的复杂性和挑战,例如复杂的嵌套、日期操作、数字和文本操作、参数,以及最重要的:欠规范和隐藏假设。、
相关链接:论文[21] / 数据集[22]
CHASE
2021 年 8 月,CHASE 是一个大规模实用的中文跨数据库上下文相关文本到 SQL 数据集(关系数据库的自然语言接口)。它与我们在 ACL 2021 上的论文《CHASE: A Large-Scale and Pragmatic Chinese Dataset for Cross-Database Context-Dependent Text-to-SQL》一同发布。
相关链接:论文[23] / 数据集[24]
Spider-DK
2021 年 9 月,Spider-DK 是一个基准数据集,旨在评估和增强 Text2SQL 模型在处理领域知识时的稳健性。Spider-DK 由伦敦玛丽女王大学的研究人员开发,以原始 Spider 数据集为基础。
相关链接:论文[25] / 数据集[26]
EHRSQL
2023 年 1 月,EHRSQL 是一个大规模、高质量的数据集,旨在对 MIMIC-III 和 eICU 的电子健康记录进行文本到 SQL 的问答。该数据集包含从 222 名医院工作人员(例如医生、护士、保险审查员和健康记录团队)收集的问题。
相关链接:论文[27] / 数据集[28]
BIRD-SQL
2023 年 5 月,香港大学与阿里巴巴联合发布了大规模跨领域数据集 BIRD,该数据集包含超过 12,751 个独特的问题-SQL 对,95 个大型数据库,总大小达 33.4 GB,涵盖区块链、曲棍球、医疗保健和教育等 37 个专业领域。
相关链接:论文[29] / 排行榜[30]
UNITE
2023 年 5 月,统一基准测试由 18 个公开的文本到 SQL 数据集组成,包含来自 12 个以上领域的自然语言问题、来自超过 3.9K 个模式的 SQL 查询以及 2.9K 个数据库。与广泛使用的 Spider 基准测试相比,我们引入了约 12 万个额外的示例,SQL 模式(例如比较和布尔问题)的数量也增加了三倍。
相关链接:论文[31] / 数据集[32]
Archer
2024 年 2 月,Archer 是一个具有挑战性的双语文本到 SQL 数据集,专门用于复杂推理,包括算术推理、常识推理和假设推理。它包含 1,042 个英文问题和 1,042 个中文问题,以及 521 个独特的 SQL 查询,涵盖 20 个领域的 20 个英文数据库。
相关链接:论文[33] / 排行榜[34]
BookSQL
2024 年 6 月,BookSQL 拥有 10 万个查询-SQL 对,约为现有最大 Text2SQL 数据集 WikiSQL 的 1.25 倍。具体而言,在设计查询时,我们咨询了金融专家,以了解各种实际用例。我们还计划创建一个排行榜,供研究人员对会计领域的各种 Text2SQL 模型进行基准测试。
相关链接:论文[35] / 数据集[36]
Spider 2.0
2024 年 8 月,XLang AI 提出的 Spider 2.0 是一个高级评估框架,用于评估实际企业级工作流中的文本转 SQL 任务。它包含 600 个复杂的文本转 SQL 工作流问题,这些问题源自各种企业数据库用例。数据集包含来自实际数据应用程序的数据库,通常包含 1,000 列以上,并存储在云端或本地系统(例如 BigQuery、Snowflake 或 PostgreSQL)。
相关链接:论文[37] / 排行榜[38]
BEAVER
2024 年 9 月,BEAVER,来源于真实的企业数据仓库,以及我们从实际用户历史中收集的自然语言查询及其正确的 SQL 语句。
相关链接:论文[39] / 数据集[40]
PRACTIQ
2024 年 10 月,PRACTIQ:一个实用的对话文本到 SQL 数据集,包含模糊和无法回答的查询。
相关链接:论文[41]
TURSpider
2024 年 11 月,TURSpider 是一个新颖的土耳其语文本到 SQL 数据集,包含类似于原始 Spider 数据集的复杂查询。TURSpider 数据集包含两个主要子集:开发集和训练集,与流行的 Spider 数据集的结构和规模保持一致。开发集包含 1034 行数据,其中 1023 个唯一问题和 584 个不同的 SQL 查询。训练集包含 8659 行数据,8506 个唯一问题及其对应的 SQL 查询。
相关链接:论文[42] / 数据集[43]
synthetic_text_to_sql
2024 年 11 月,gretelai/synthetic_text_to_sql 是一个丰富的高质量合成 Text2SQL 样本数据集,使用 Gretel Navigator 设计和生成,并在 Apache 2.0 下发布。
相关链接:数据集[44]
推荐计划
后续我们将持续推荐高质量数据集,敬请期待!!
[2] NL2SQL-Bugs 数据集: https://github.com/HKUSTDial/NL2SQL-Bugs-Benchmark
[3] OmniSQL 论文: https://arxiv.org/html/2503.02240
[4] OmniSQL 数据集: https://huggingface.co/datasets/seeklhy/SynSQL-2.5M
[5] TINYSQL 论文: https://arxiv.org/html/2503.12730
[6] TINYSQL 数据集: https://huggingface.co/collections/withmartian/tinysql-6760e92748b63fa56a6ffc9f
[7] WikiSQL 论文: https://arxiv.org/pdf/1709.00103.pdf
[8] WikiSQL 数据集: https://github.com/salesforce/WikiSQL
[9] Spider 1.0 论文: https://arxiv.org/pdf/1809.08887.pdf
[10] Spider 1.0 排行榜: https://yale-lily.github.io/spider
[11] SParC 论文: https://arxiv.org/pdf/1906.02285.pdf
[12] SParC 排行榜: https://yale-lily.github.io/sparc
[13] CSpider 论文: https://arxiv.org/pdf/1906.02285.pdf
[14] CSpider 排行榜: https://taolusi.github.io/CSpider-explorer/
[15] CoSQL 论文: https://ar5iv.labs.arxiv.org/html/1909.05378
[16] CoSQL 排行榜: https://yale-lily.github.io/cosql
[17] KaggleDBQA 论文: https://arxiv.org/abs/2106.11455
[18] KaggleDBQA 数据集: https://github.com/Chia-Hsuan-Lee/KaggleDBQA/
[19] Spider-Syn 论文: https://ar5iv.labs.arxiv.org/html/2106.01065
[20] Spider-Syn 数据集: https://github.com/ygan/Spider-Syn
[21] SEDE 论文: https://ar5iv.labs.arxiv.org/html/2106.05006
[22] SEDE 数据集: https://github.com/hirupert/sede
[23] CHASE 论文: https://aclanthology.org/2021.acl-long.180.pdf
[24] CHASE 数据集: https://github.com/xjtu-intsoft/chase
[25] Spider-DK 论文: https://ar5iv.labs.arxiv.org/html/2109.05157
[26] Spider-DK 数据集: https://github.com/ygan/Spider-DK
[27] EHRSQL 论文: https://arxiv.org/html/2301.07695
[28] EHRSQL 数据集: https://github.com/glee4810/EHRSQL
[29] BIRD-SQL 论文: https://arxiv.org/pdf/2305.03111.pdf
[30] BIRD-SQL 排行榜: https://bird-bench.github.io/
[31] UNITE 论文: https://ar5iv.labs.arxiv.org/html/2305.16265
[32] UNITE 数据集: https://github.com/awslabs/unified-text2sql-benchmark
[33] Archer 论文: https://arxiv.org/html/2402.12554
[34] Archer 排行榜: https://sig4kg.github.io/archer-bench/
[35] BookSQL 论文: https://arxiv.org/html/2406.07860
[36] BookSQL 数据集: https://github.com/Exploration-Lab/BookSQL
[37] Spider 2.0 论文: https://spider2-sql.github.io/
[38] Spider 2.0 排行榜: https://spider2-sql.github.io/
[39] BEAVER 论文: https://arxiv.org/html/2409.02038
[40] BEAVER 数据集: https://github.com/peterbaile/beaver
[41] PRACTIQ 论文: https://arxiv.org/html/2410.11076
[42] TURSpider 论文: https://ieeexplore.ieee.org/document/10753591
[43] TURSpider 数据集: https://github.com/alibugra/TURSpider
[44] synthetic_text_to_sql 数据集: https://huggingface.co/datasets/gretelai/synthetic_text_to_sql