作者:贲绍华
爱可生研发中心工程师,负责项目的需求与维护工作。其他身份:柯基铲屎官。
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
—
一、主从复制简介
Redis 主从架构下,使用默认的异步复制模式来同步数据,其特点是低延迟和高性能。当 Redis master 下有多个 slave 节点,且 slave 节点无法进行部分重同步时, slave 会请求进行全量数据同步,此时 master 需要创建 RDB 快照快照发送给 slave ,从节点收到 RDB 快照到开始解析与加载。
二、主从复制风暴
在复制重建的过程中,slave 节点加载 RDB 还未完成,却因为一些原因导致失败了,slave 节点此时又会再次发起全量同步 RDB 的请求,循环往复。当多个 slave 节点同时循环请求时,导致了复制风暴的出现。
三、问题现象
3.1 CPU:
master 节点会异步生成 RDB 快照,数据量非常大时 fork 子进程非常耗时,同时 CPU 会飙升,且会影响业务正常响应。
3.2 磁盘:
从 Redis 2.8.18 版本开始,支持无磁盘复制,异步生成的RDB快照将在子进程中直接发送 RDB 快照至 slave 节点,多个 slave 节点共享同一份快照。所以磁盘 IO 并不会出现异常。
3.3 内存与网络:
由于 RDB 是在内存中创建与发送,当复制风暴发起时,master 节点创建RDB快照后会向多个 slave 节点进行发送,可能使 master 节点内存与网络带宽消耗严重,造成主节点的延迟变大,极端情况会发生主从节点之间连接断开,导致复制失败。slave 节点在失败重连后再次发起新一轮的全量复制请求,陷入恶性循环。
四、出现的场景
- 单master节点(主机上只有一台redis实例)当机器发生故障导致网络中断或重启恢复时。
- 多master节点在同一台机器上,当机器发生故障导致网络中断或重启恢复时。
- 大量slave节点同时重启恢复。
- 复制缓冲区过小,缓冲区的上限是由client-output-buffer-limit配置项决定的,当slave还在恢复RDB快照时,master节点持续产生数据,缓冲区如果被写满了,会导致slave节点连接断开,再次发起重建复制请求。发起全量复制->复制缓冲区溢出->连接中断->重连->发起全量复制->复制缓冲区溢出->连接中断->重连…
- 网络长时间中断导致的连接异常:跨机房、跨云、DNS解析异常等导致的主从节点之间连接丢失。主从节点判断超时(触发了repl-timeout),且丢失的数据过多,超过了复制积压缓冲区所能存储的范围。
- 数据量过大,生成RDB快照的fork子进程操作耗时过长,导致slave节点长时间收不到数据而触发超时,此时slave节点会重连master节点,再次请求进行全量复制,再次超时,再次重连。
五、解决方案
5.1 降低存储上限
Redis 实例的存储数据的上限不要过大,过高的情况下会影响 RDB 落盘速度、向 slave 节点发送速度、slave 节点恢复速度。
5.2 复制缓冲区调整
master 节点 client-output-buffer-limit 配置项阈值增大(或调整为不限制),repl_timeout 配置项阈值增大。使 slave 节点有足够的时候恢复RDB快照并且不会被动断开连接。
5.3 部署方式调整
单个主机节点内尽量不再部署多个 master 节点,防止主机因为意外情况导致的所有 slave 节点的全量同步请求发送至同一主机内。
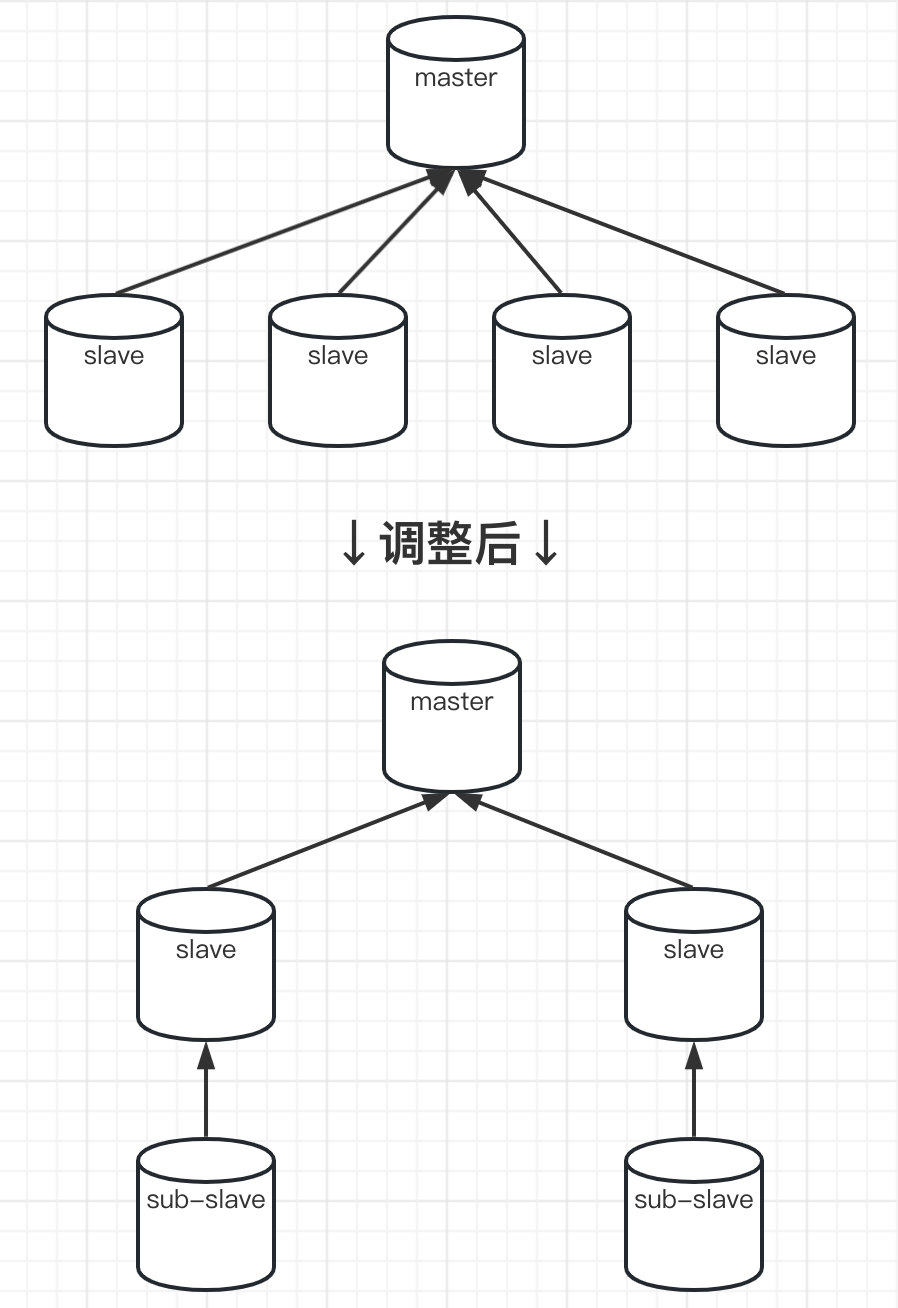
5.4 架构调整
减少 slave 节点个数。或调整 slave 架构层级,在 Redis 4.0 版本之后,sub-slave 订阅 slave 时将会收到与 master 一样的复制数据流。