作者:文韵涵
爱可生 DBLE 团队开发成员,主要负责 DBLE 需求开发,故障排查和社区问题解答。
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
背景
SQL-1:select a.name from tabler a Left Join gtable1 b on a.name = b.name and a.id = 2; (tabler、gtable1分别为分片表、全局表,其中tabler.id 为分片列;两个表配置的节点均为dn1~4)
查看 SQL-1 在 DBLE 中执行计划 Explain-1:

从explain中,将分片表 tabler 分别下发各个节点,全局表 gtable1 单独下发一个节点分别获取数据;
另外,没有 ”on a.name = b.name and a.id = 2 ” 条件的身影,想必是在DBLE层面对数据进行的join合并和筛选处理了。
提出Suppose-1
SQL-1 on中 “a.id = 2”,a.id作为分片列; 看起来可以根据a.id明确路由单节点下发tabler表,然后gtable1作为全局表可以随意选一个路由节点下发;
具体假设:根据“a.id = 2” 确定路由节点为dn1,那么SQL-1貌似可以整体下发(直接透传)到dn1节点中了,这样以来可以减少在DBLE层面join数据的处理。
After a while:….咦….啊…为啥….好像不行诶………..
经过一顿胡乱操作,发现 Suppose-1 的优化方案并不适合在left/right join场景下。
SQL-2:select a.name from tabler a Left Join gtable1 b on a.name = b.name where a.id = 2;
提出的Suppose-1 的实现方案几乎与在DBLE中处理SQL-2的思维雷同;
反思:误认为 SQL-2中 “where a.id = 2” 与 SQL-1中 “on … a.id = 2 ”属于同一种过滤。
正视 On 和 Where 的定义
- On:作为两表在做笛卡尔积关联时,附加的关联条件,生成虚拟表V。
- Where:对虚拟表V(两表关联后的结果)筛选时用的过滤条件,只保留符合条件的数据行
MySQL 中执行 Left Join
1、Employee 为左表,Info 为右表,On关联条件:a.name = b.name
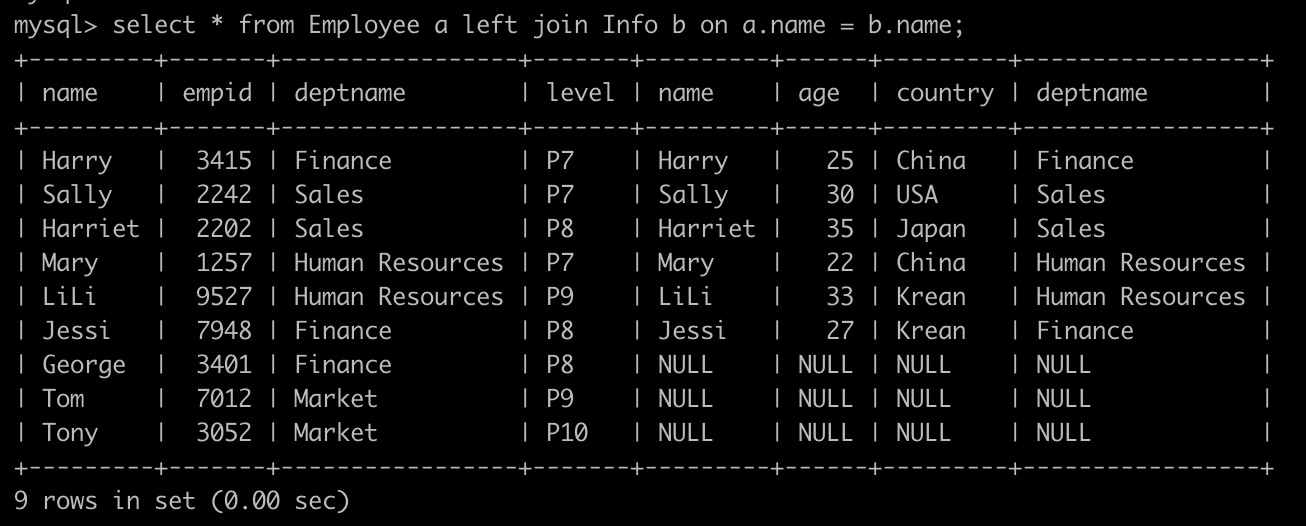
Result-1:左表数据全部展示,右表符合关联条件的则显示对应的信息,若没有关联信息,则右表填充null。(图中,左表的全部信息有10个name,而右表的name没有George,Tom,Tony,所以对应右表显示null)
2、在Result-1中追加 On 关联条件:b.country = ‘China’ 。

Result-2:左表数据依旧全部展示,在Result-1基础上的数据行找到符合 “b.country = ‘China’ ” 关联条件,如果不符合,则右表填充null。(图中,右表中只有两条country为China的数据,其余的都不符合关联条件,所以右表显示null)
3、在Result-1中追加 Where 过滤条件:b.country = ‘China’ 。
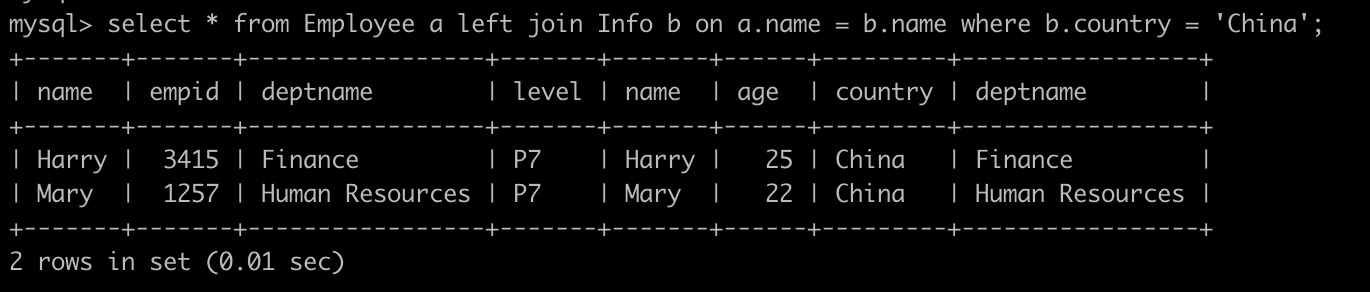
Result-3:在Result-1的基础上,进行 “b.country = ‘China’ ” 过滤条件的筛选,剔除不符合的数据行。(图中,只显示符合country为China过滤条件的两条数据)
总结
- 从上面的 Result-2 和Result-3 ,可以很明显的看出Left join下使用 On 和Where 的区别:
- On :关联条件不影响左表全部信息显示,它是作为右表是否符关联条件,不符合的,右边将由NULL填充。
- Where :不关心JOIN类型,在虚拟表V基础上再进行条件过滤,只返回符合条件的数据行。
- LEFT JOIN
- 水平视角,等价于 左表的全部信息 +(右边符合关联条件的信息+不符合关联条件的NULL填充)
- 垂直视角,等价于 INNER JOIN + 补足左表 + 右表NULL填充
- 左外连接 (⟕) :左外连接写成R ⟕ S,其中R与S为关系。左外连接的结果包含R中所有元组,对每个元组,若在S中有在公共属性名字上相等的元组,则正常连接,若在S中没有在公共属性名字上相等的元组,则依旧保留此元组,并将对应其他列设为NULL。
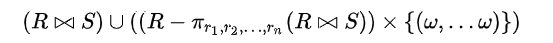
- 在LEFT JOIN中,左表的数据需全部显示;根据提出的Suppose-1方案, SQL-1中只会下发dn1一个节点,并不符合on关联条件的定义,所以Suppose-1优化方案不可行;(目前的Explain-1是符合预期的)
(Right Join与 Left Join相似,Right Join的左边作为右表,右边作为左表,可套用以上的描述,然后在显示的两表调换顺序即可)。
MySQL Left Join 中 on 关联条件的实现逻辑
数据准备
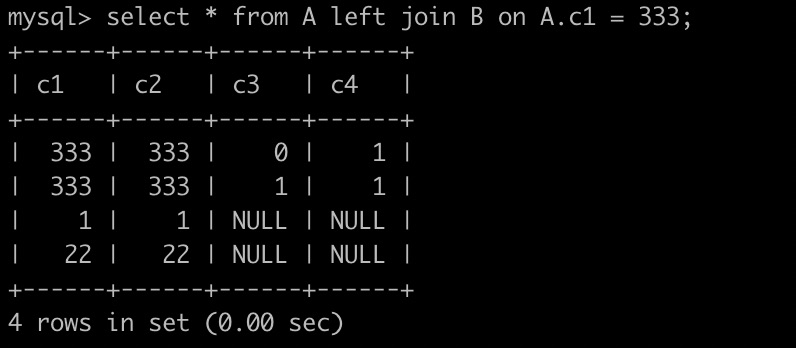
create table A(c1 int, c2 int); create table B(c3 int, c4 int); insert into A values(1,1),(22,22),(333,333); insert into B values(0,1),(1,1);
查询

提问
图1结果符合预期,但图2的结果有点不理解,不是说 on 条件不会过滤么,这里好像过滤了吧?
解答
图2中没有对数据过滤; 需要了解 MySQL 中采用嵌套循环连接的join算法,这里列举 Left join实现的伪代码:
for(leftTable :leftRow) {// 遍历左表的每一行
boolean b = false;
for(rightTable: rightRow) {// 遍历右表每一行
if(满足on关联条件){
System.out.println(leftRow + rightTable); // 则左、右行进行合并输出
b=true;
}
}
if(!b) { // 遍历完rightTable,发现leftRow没有关联对应的行,则用null补一行
System.out.println(leftRow + NULL); // 则左行与NULL合并输出
}
}
具体解读:
图1,“A.c1 > 0” 作为关联条件总是为true,查询结果等于两个表的笛卡尔积。
图2,“A.c1 = 333” 也还是关联,套用伪代码:左表c1列为333的时候,已经满足了on条件,左、右边数据合并;左表c1列为1和22时,不符合关联条件,所以各自就用左边数据+NULL合并补了一行;
参考文档
- https://dev.Mysql.com/doc/refman/5.6/en/nested-join-optimization.html
- https://zh.wikipedia.org/wiki/%E5%85%B3%E7%B3%BB%E4%BB%A3%E6%95%B0_(%E6%95%B0%E6%8D%AE%E5%BA%93)