作者:马莹乐
爱可生研发团队成员,负责 mysql 中间件的测试。本人是测试技术爱好者,欢迎大家试用 dble 新功能~
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
split 功能的介绍
当旧业务需要改造为基于 dble 的分布式业务时,会面临已有历史数据的拆分和导入问题,dble 支持的导入导出方式有多种,具体详见文档3.11.1,本次我们介绍的 split 功能可以理解为导入过程加速器,那它是怎么加速的呢?
大家可以考虑这样一个场景:一份原始数据通过 mysqldump 工具 dump 下了一个sql文件(下称“dump文件”),正常情况下,这个 dump 文件也不会太小,直接拿着这个 dump 文件通过 dble 的业务端去导入,可能需要等上一段时间才能完成,而且这个过程一定会比直接往 MySQL 里导入数据慢一些,万一导入数据期间发生了什么错误,也会难以排查。
那当我拿到 dump 文件后,就只能通过直连 dble 业务端导入数据才能实现历史数据的拆分和导入吗?有没有一种可能的方式,是先把 dump 文件按照配置拆分成 dump 子文件,然后我们就可以拿着这些拆分后的 dump 子文件,分别到与之对应的后端 MySQL 上直接导入数据呢?
于是 dble 的 split 功能应运而生。在这里它就是做 dump 文件拆分工作的。它工作的大致过程就是先根据分库分表的配置,对 dump 文件 按照分片 进行处理,配置有多少分片就会产生多少个拆分后的 dump 子文件。当然,任凭你 sharding.xml 里配置的有 shardingTable 、有 globalTable 、有 singleTable ,还是全都有,都会体现在生成的 dump 子文件里,我们拿着这些 dump 子文件,就可以直接导入到各自分片对应的后端 MySQL 中,当完成后端数据的导入操作后,只需要再同步一下 dble 的元数据信息,这样就完成了历史数据的拆分和导入。
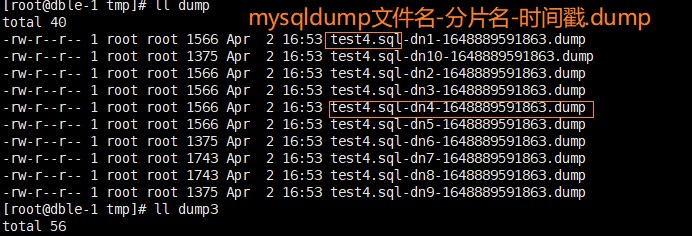
经 split 处理后,生成的 dump 子文件示例:
不过在使用 mysqldump 导出历史数据 sql 文件时,需要按照以下格式进行导出,否则可能出现错误,因为有些 mysqldump 参数,dble 不支持。
./mysqldump -h127.0.0.1 -utest -P3306 -p111111 --default-character-set=utf8mb4 --master-data=2 --single-transaction --set-gtid-purged=off --hex-blob --databases schema1 --result-file=export.sql
其他注意点参见文档3.11.2
基本使用介绍
语法与示例
登录 dble 的管理端口 9066 执行 split 命令,语法如下:
mysql > split src dest [-sschema] [-r500] [-w512] [-l10000] [--ignore] [-t2]src:表示原始dump文件名dest:表示生成的dump文件存放的目录-s:表示默认逻辑数据库名,当dump文件中不包含schema的相关语句时,会默认导出到该schema。如:当dump文件中包含schema时,dump文件中的优先级高于-s指定的;若文件中的schema不在配置中,则使用-s指定的schema,若-s指定的schema也不在配置中,则返回报错-r:表示设置读文件队列大小,默认500-w:表示设置写文件队列大小,默认512,且必须为2的次幂-l:表示split后一条insert中最多包含的values,只针对分片表,默认4000--ignore:insert时,忽略已存在的数据-t:表示多线程处理文件中insert语句时线程池的大小
使用示例:
mysql > split /path-to-mysqldump-file/mysqldump.sql /tmp/dump-dir-name;mysql > split /path-to-mysqldump-file/mysqldump.sql /tmp/dump-dir-name -sdatabase1;mysql > split /path-to-mysqldump-file/mysqldump.sql /tmp/dump-dir-name -sdatabase1 -r600;mysql > split /path-to-mysqldump-file/mysqldump.sql /tmp/dump-dir-name -sdatabase1 -r600 -w1024;mysql > split /path-to-mysqldump-file/mysqldump.sql /tmp/dump-dir-name -sdatabase1 -r600 -w1024 -l10000;mysql > split /path-to-mysqldump-file/mysqldump.sql /tmp/dump-dir-name -sdatabase1 -r600 -w1024 -l10000 --ignore;mysql > split /path-to-mysqldump-file/mysqldump.sql /tmp/dump-dir-name -sdatabase1 -r600 -w1024 -l10000 --ignore -t4;
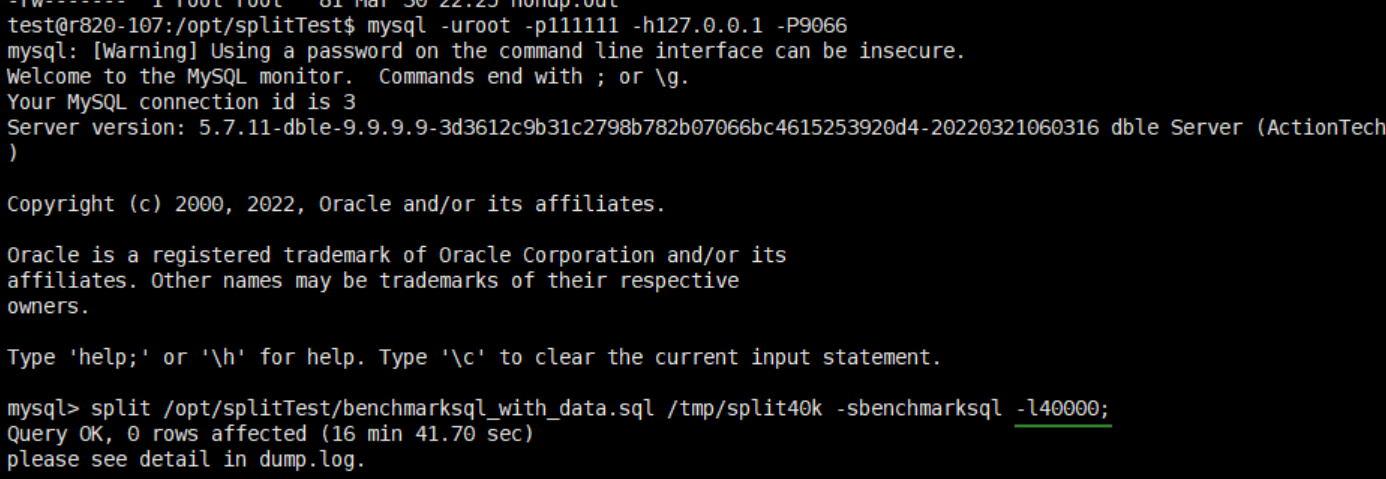
一个 split 执行的示例:
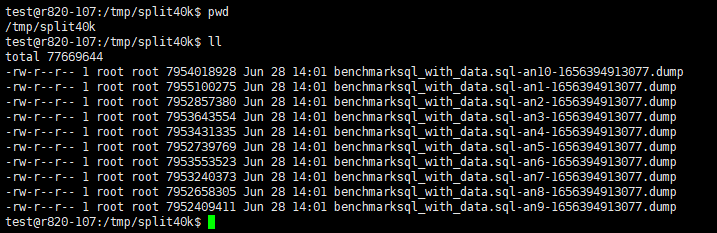
根据此示例,则可以在指定的目录/tmp/split40k下查看到 split 生成的 dump 子文件:
更加详细的使用说明,可查阅文档 split命令的介绍 部分。
split 性能测评
讲了那么多,那它到底快了没快,快了多少呢?拆好的数据会不会缺斤少两?
我们准备做个试验来看看。在同样的测试环境下,准备了3组测试,具体如下:
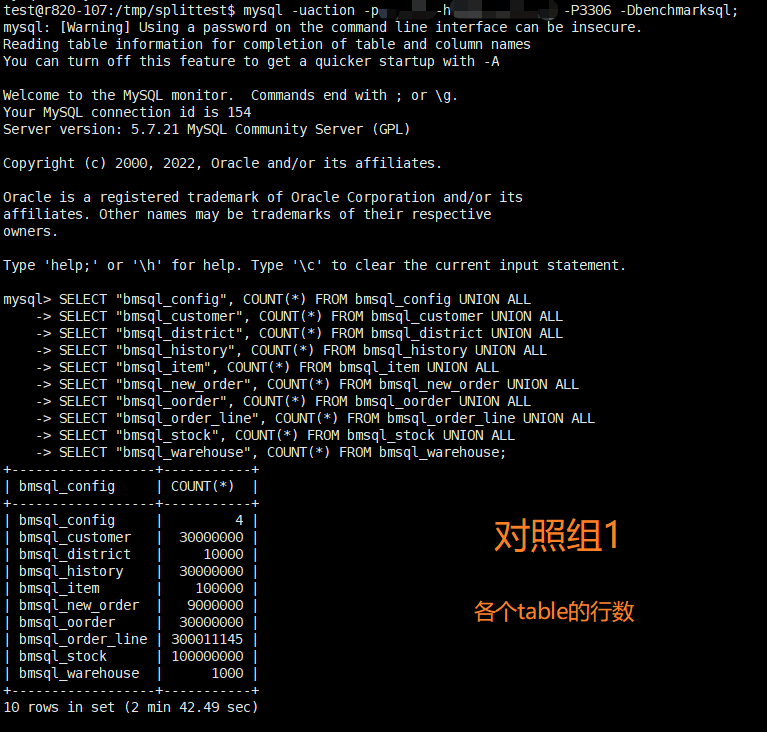
- 对照组1: 同一 dump 文件,在不使用 dble 的情况下,直连 MySQL 整体导入 MySQL 的耗时,并获取各个 table 的总行数,用来作为其他测试组导入的数据是否存在问题的标杆。
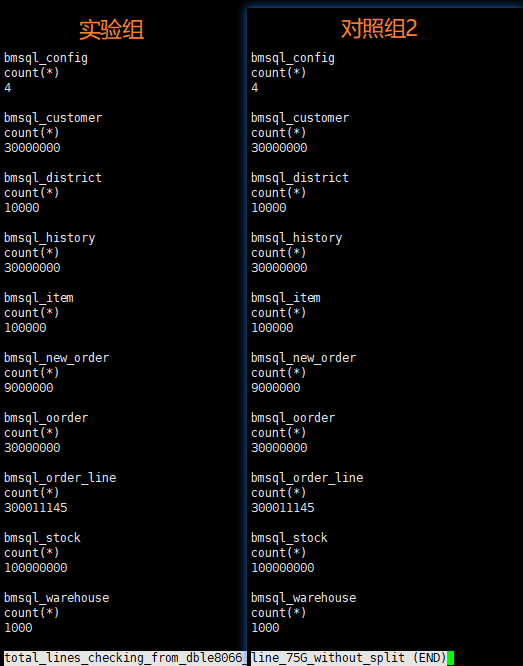
- 对照组2: 同一 dump 文件,同一环境下,直连 dble 导入数据的耗时,以及各个 table 的总行数,各个分片上每张表的行数和 checksum 值
- 实验组: 同一 dump 文件,同一环境下,split 处理+导入的耗时,以及各个 table 的总行数,各个分片上每张表的行数和 checksum 值
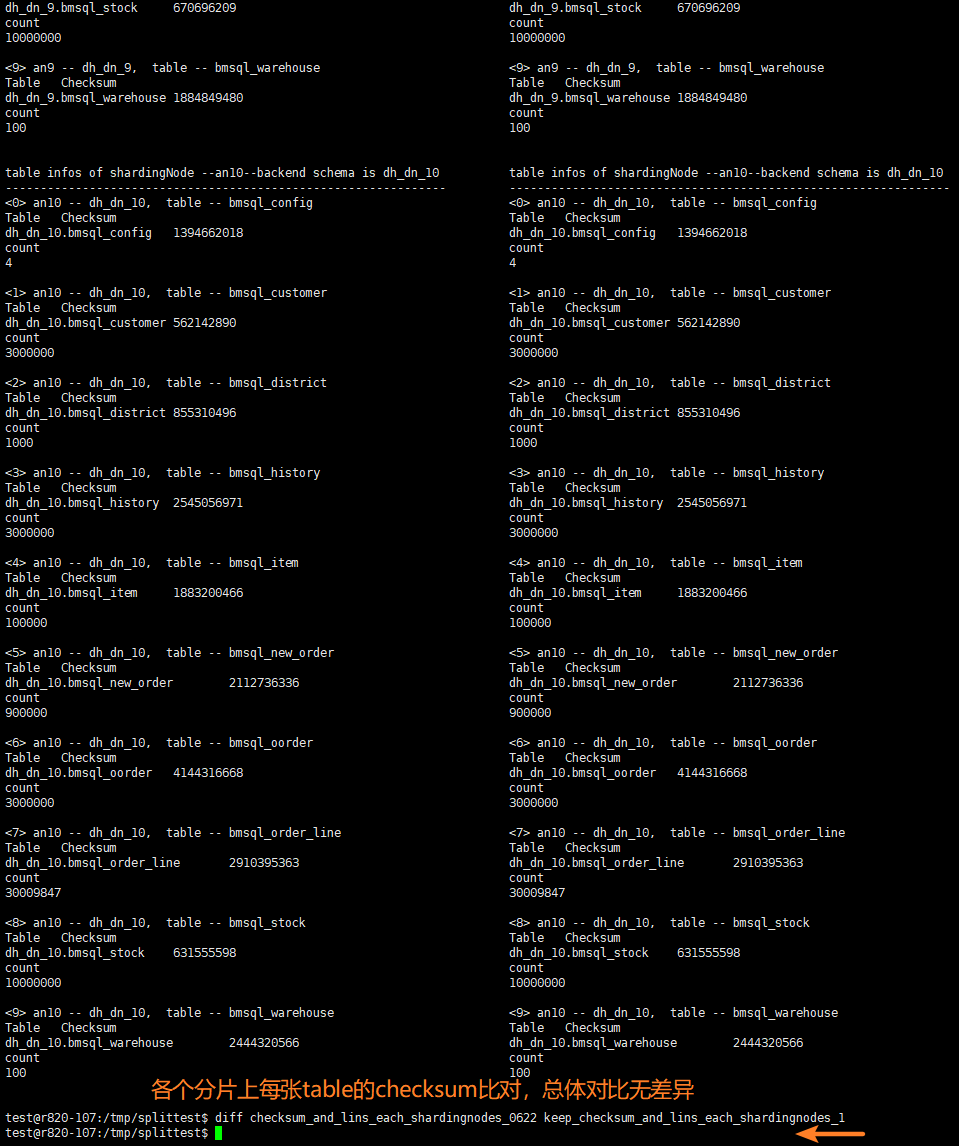
注:由于数据经过了拆分,dble 业务端暂不支持checksum table的语法,所以难以从 table checksum 值这个层面去对比原始 MySQL 中各个 table 总体的 checksum 值,所以本次试验只对比了这3组测试中各个 table 总行数,以及对照组2和实验组各个分片对应table的行数和 checksum 值。
试验环境
- 测试使用 dble :单节点 dble ,版本为
5.7.11-dble-3.22.01.0-e5d394e5994a004cd11b28dc5c171904769adad3-20220427091228 - 数据文件来源:
使用 benchmarksql 造1000个 warehouse 的数据作为数据源(本次测试使用的表结构未添加外键关系),mysqldump 获取的 dump 文件约75G
本次试验采用了10个分片的测试,同时由于每个分片的数据导入的时间和数据量的大小成正比,所以采用求模的拆分算法,使得数据可均匀分布在每个分片上。
- split 命令:实验组采用 split 命令
/opt/splitTest/benchmarksql_with_data.sql /tmp/splittest -sbenchmarksql; - dble 配置:
本次试验拿4个 MySQL 实例作为后端 MySQL ,并统一采用10个分片作为对照组2和实验组的配置,相关配置如下:
sharding.xml
<?xml version="1.0"?><!DOCTYPE dble:sharding SYSTEM "sharding.dtd"><dble:sharding xmlns:dble="http://dble.cloud/" version="4.0"><schema name="benchmarksql"> <globalTable name="bmsql_config" shardingNode="an$1-10" checkClass="CHECKSUM" cron="0 0 0 * * ?"></globalTable> <globalTable name="bmsql_item" shardingNode="an$1-10" checkClass="CHECKSUM" cron="0 0 0 * * ?"></globalTable> <shardingTable name="bmsql_warehouse" shardingNode="an$1-10" function="benchmarksql-mod" shardingColumn="w_id"></shardingTable> <shardingTable name="bmsql_district" shardingNode="an$1-10" function="benchmarksql-mod" shardingColumn="d_w_id"></shardingTable> <shardingTable name="bmsql_customer" shardingNode="an$1-10" function="benchmarksql-mod" shardingColumn="c_w_id"></shardingTable> <shardingTable name="bmsql_history" shardingNode="an$1-10" function="benchmarksql-mod" shardingColumn="h_w_id"></shardingTable> <shardingTable name="bmsql_new_order" shardingNode="an$1-10" function="benchmarksql-mod" shardingColumn="no_w_id"></shardingTable> <shardingTable name="bmsql_oorder" shardingNode="an$1-10" function="benchmarksql-mod" shardingColumn="o_w_id"></shardingTable> <shardingTable name="bmsql_order_line" shardingNode="an$1-10" function="benchmarksql-mod" shardingColumn="ol_w_id"></shardingTable> <shardingTable name="bmsql_stock" shardingNode="an$1-10" function="benchmarksql-mod" shardingColumn="s_w_id"></shardingTable></schema> <shardingNode name="an1" dbGroup="ha_group1" database="dh_dn_1"/> <shardingNode name="an2" dbGroup="ha_group2" database="dh_dn_2"/> <shardingNode name="an3" dbGroup="ha_group3" database="dh_dn_3"/> <shardingNode name="an4" dbGroup="ha_group4" database="dh_dn_4"/> <shardingNode name="an5" dbGroup="ha_group1" database="dh_dn_5"/> <shardingNode name="an6" dbGroup="ha_group2" database="dh_dn_6"/> <shardingNode name="an7" dbGroup="ha_group3" database="dh_dn_7"/> <shardingNode name="an8" dbGroup="ha_group4" database="dh_dn_8"/> <shardingNode name="an9" dbGroup="ha_group1" database="dh_dn_9"/> <shardingNode name="an10" dbGroup="ha_group2" database="dh_dn_10"/> <function name="benchmarksql-mod" class="Hash"> <property name="partitionCount">10</property> <property name="partitionLength">1</property> </function></dble:sharding>
试验过程
在同一测试环境下,分别测试 对照组1、2和实验组。实验组并未将 dump 子文件转移至它对应的后端执行本机导入,而是在 dump 子文件所在机器上远程连接到各自后端 MySQL 服务,同时并发导入,并开始计时,由于是并发导入,所以导入的耗时取决于耗时最长的后端MySQL节点。
当各个分片的 dump子 文件均导入完成后,可在dble管理端执行reload @@metadata; 重新加载所有元数据信息。
接着可以:
- 获取3组测试各自导入数据的耗时
- 查看10张 table 各自的总行数在3组测试中是否完全一致,其中对照组2和实验组(即直连 dble 执行的导入和 split 执行的导入),则可以通过 dble 业务端直接查询
select count(*) from tb_name; - 对照组2和实验组,还可通过后端 MySQL ,检查每个分片对应的各个 table 的 checksum 值
checksum table tb_name;和行数select count(*) from tb_name;
试验记录
对照组
对照组1
同一 mysqldump 文件(75G),在不使用 dble 的情况下,直连 MySQL 整体导入,耗时统计:13181s

对照组2
同一 mysqldump 文件(75G),未经 split 分片,(mysqldump 文件在 dble 所在主机本机)直连 dble导 入耗时统计:50883s

实验组
同一 mysqldump 文件(75G),经过 split 分片处理+(在 dble 本机远程连接后端 MySQL )并发导入到后端 MySQL 的耗时统计:912s+1839s=2751s
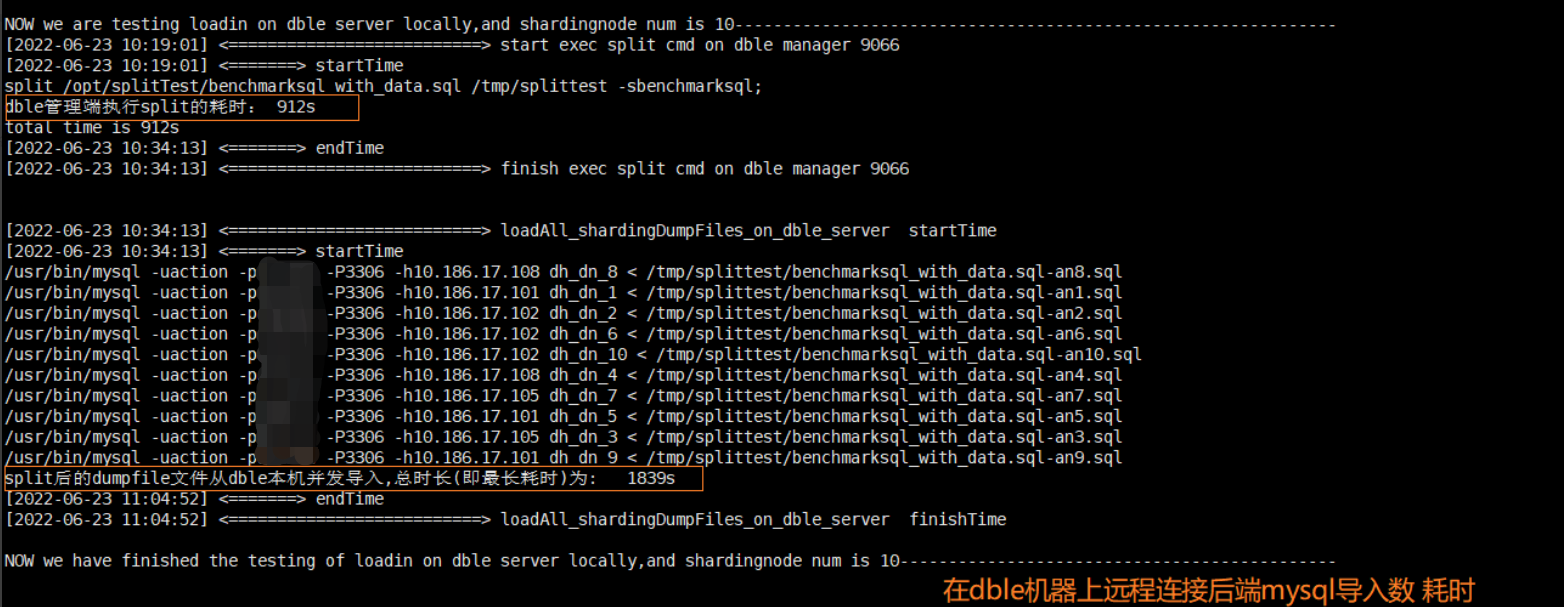
数据对比:
3组测试中,benchmarksql 相关的10个table总行数完全一致,其中对照组2和实验组(即直连 dble 执行的导入和 split 执行的导入)后端的各个分片上对应的每张 table 的 checksum 值和行数均是一致的。
试验结果:
在本次试验中:
- 导入速率对比:同一 mysqldump 文件(75G),split 导入的速率是直接整体 MySQL 导入速率的5倍,是直接通过 dble 整体导入速率的18倍。split 的导入速度达到98G/h。
- 导入正确性对比:通过 split 导入数据的方式和通过直连 dble 业务端导数据的最终结果是一致的。
小结
理论上,执行 split 命令的机器性能足够好,且 MySQL 服务器充足时,导入的速度可进一步提高,如,我们可以尝试以下策略:
- 适当增加分片数
- 拆分算法的选择,规划数据更加均匀分布在每个后端 MySQL 服务器上
- dump 子文件也可先传输至后端 MySQL 本机,再执行导入,以减小网络上的消耗
强大如 split ,也还是存在一些使用上的限制,如:
- 不支持显式配置的 childTable(但支持含有外键关系的表以智能ER关系配置在sharding.xml中)
- 不支持 view
- 对于使用全局序列的表,表原先全局序列中的值会被擦除,替换成全局序列,需要注意。
更多详细信息可参考split命令的介绍
其他
测试dble split功能执行+导入耗时shell脚本参考,感兴趣的亲可以点击 这里 查看
`