作者:任坤
现居珠海,先后担任专职 Oracle 和 MySQL DBA,现在主要负责 MySQL、mongoDB 和 Redis 维护工作。
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
1、背景
线上某核心业务采用了国内某云厂商 Mongo RDS ,版本为 4.2 ,采用4分片集群。
临上线前进行各种场景测试,在运行邮件发送测试时发现 Mongo 集群负载严重不均衡。 在1分钟的压测时间内,Shard 3 主节点 cpu 被100%打满,其余3个 shard 主库负载均在正常范围,据开发反馈该场景 insert 比较多,可能是 insert 流量倾斜导致的。 我们的分片表都是采用 hash 分片,并且分片字段的选择性都很高,理论上不存在数据倾斜的 情况。
2、诊断
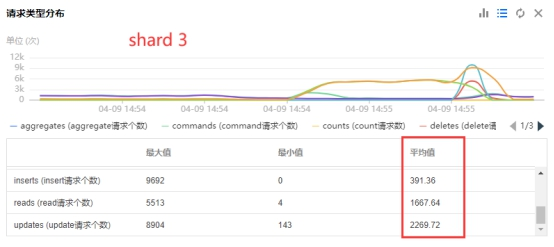
查看对应时间段监控指标,shard 3 主节点,cpu 在这1分钟被打满, 100ms以上慢查询平均 每秒1300+ 。

作为对比,查看 shard 4 同一时间段的负载,该分片几乎没有1条慢查询,cpu 负载也很低。
仔细查看 QPS 细分指标,shard 3 的 read 和 update 分别达到了1600+和2200+,而 shard4 只有500和600左右,insert 两边几乎一致都是400左右,可以先排除掉 insert 倾斜的可能性。
查看这个时间段 shard 3 的慢查询日志,总量有几十万,但是目前该厂商 RDS 平台功能还在完善中,不支持在页面直接查看每个 shard 实例的慢查询日志。
只能在群里求助官方人员,让他们从后台导出每个 shard 对应时间段的慢查询文件然后传过来,其中 shard 3 的慢查询文件有几百兆。
文件太大只下载了一部分,打开文件看到前几个慢查询都针对用户表 users 的 update ,sql text 都超过10K,当时判定是 users 的 update 倾斜导致的问题。
该表针对 pid 列进行 hash 分片,目前有260w行,db.users.getShardDistribution()显示数据分布很均匀。
本次测试的 pid 是连号的,从2600001‐2635000总共3.5w条数据,现在怀疑这3.5w条数据分布倾斜。
但是目前该厂商 RDS 不支持直接登录 shard 实例,也就无法直接确认这3w多条数据的分布情况。
现在问题演变成了:只允许登录 mongos 的前提下,如何确认某个范围的数据在 shard 节点上的物理分布情况?
社区群里求助,很快有热心群友给出建议:
1、对于每个 pid 值,执行 convertShardKeyToHashed( pid ) 计算 hash 值,再根据该 hash 值找出其所属 chunk 和节点。
该方案的难点在于每个 chunk 只记录范围上限和下限,对于给定的 hash 值无法直接判断其落在了哪个chunk,编写相应脚本的逻辑会比较复杂。
2、新建一个同等结构的分片表,将这3w条记录导入,然后查看该表的分布情况。
这个方案很好,对同一批数据采用相同的分片键和分片策略,理论上分布情况也应该是相同的,正在准备操作时热心群友又给出了第3个方案。
3、对这批 pid 执行范围查询并查看执行计划 executionStats ,每个 shard 会返回 docs 或者 keyexamined 情况。
思路打开了,这个应该是最优解。
以上建议均是由同一位网友提出的,在此感谢@徐靖(公众号”DB说”)。
当即执行了一把
db.users.find({ "pid" : { "$gte" : 2600001, "$lt" : 2635000} }).explain("executionStats")
......
"totalKeysExamined" : 34994,
"totalDocsExamined" : 34994,
"docsExamined" : 8643, ‐‐ shard1
"docsExamined" : 8693, ‐‐ shard2
"docsExamined" : 8824, ‐‐ shard3
"docsExamined" : 8834, ‐‐ shard4
......
确认这3w多条数据分布是均匀的,至此时间已经过去了几个小时。
现在确认了所有分片数据都是均匀散列的,接下来只能核对非分片表。
正在准备查询时,云厂商发来消息,他们通过后台查看慢日志确认是某个单表导致的,该表的 primary shard 正好是 shard 3 。
当即和开发确认,每次操作流程确实会涉及该表,调用一次 findAndModify 。
那为何在官方提供的慢查询日志文件里没有找到,再次查看发现文件开头的时间点不在 CPU 异常时间段内,有点疏忽了。
该单表只有3条数据,即便开启分片这3条数据也只会落到单个 shard 节点,不会有任何性能提升,将该表计算逻辑挪到了 redis ,再次压测问题消失。
3、小结
类似这种 QPS 分布不均匀的案例去年在自建 Mongo 集群遇到过一次,当时通过查看 shard 节点的 oplog 快速定位并解决了。
这次之所以绕了这么大的弯,原因如下:
- 该厂商 RDS 平台功能不太完善,不支持在页面上直接查看 shard 节点的慢查询,也不支持 直接登录 shard 实例,好在官方已承诺最快下个月会上线类似功能。
- 第一次查看官方发来的慢查询文件时,没有仔细看对应的时间点,直接导致排查方向搞偏了。