作者:任坤
现居珠海,先后担任专职 Oracle 和 MySQL DBA,现在主要负责 MySQL、mongoDB 和 Redis 维护工作。
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
1、背景
某业务写多读少,上线前预估TPS最高可达4w且可能会随时增长,去年上线时采用了mongo 4分片集群架构。
现在业务趋于稳定,日常TPS只有最高值的1/10不到,项目组出于成本考虑想要将其迁移到内存KV数据库,但是 redis纯内存模式机器成本有点高,经过调研后决定尝试360开源的pika。
我们采用的是3.3.6版本,机器A配置为8c8G200G,压测出现大量超时ERROR: redis: connection pool timeout,qps只有3k左右,且磁盘的%util 一直接近100,处于“饱和”状态。
同样版本的pika,在机器B上测试,qps能达到40K且没有1个超时错误,这台机器配置24c48G1.5T。 从多家云厂商那里获悉相同型号的云主机,硬盘容量越大IO吞吐会越高,因此一开始怀疑是硬件问题。
针对两台云主机进行FIO测试,配置更高的机器读写吞吐是会高一些(大概提升20%左右),但并没有pika qps指标相 差10倍这么夸张。
将机器B的pika配置文件复制到机器A上,重启pika再测进行压测,这次机器A的qps也能达到40K,说明pika配置 参数导致的性能差异。
2、诊断
两个配置文件参数相差的有点多,只能逐个修改并压测。
测试过程略过,最后确认是max-write-buffer-size设置不合理导致的,该参数默认值14045392(13M),调大为 4294967296(4G)后pika qps就从3k提升到了40K。

以下是对应测试案例的iostat截图
— max-write-buffer-size 14045392(13M)

— max-write-buffer-size 4294967296
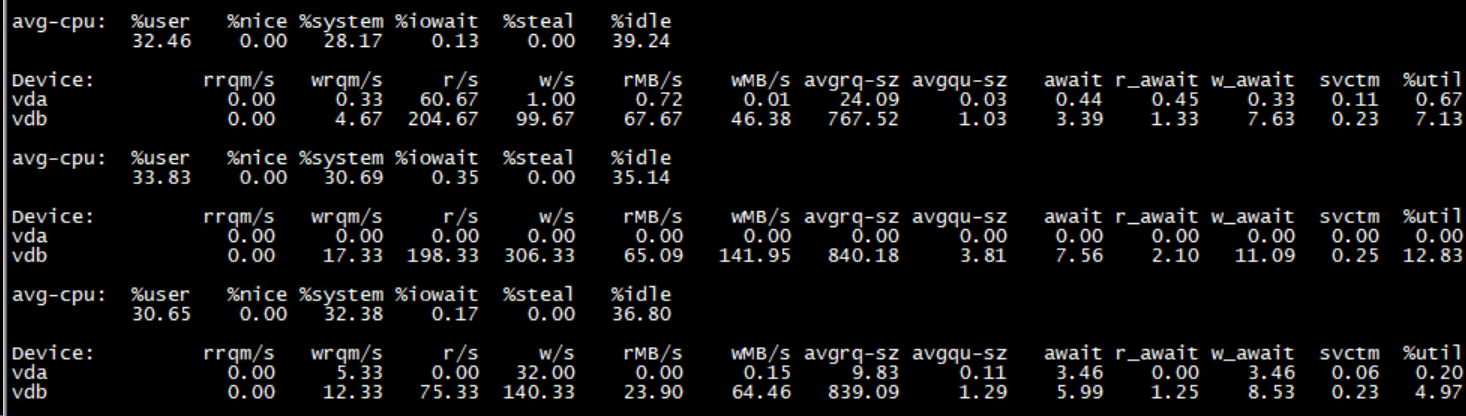
两者最大的差异是w/s和avgrq-sz,其中avgrq-sz描述的是IO请求的平均大小,以扇区(512字节)为单位。
图1每秒磁盘写请求4700,每个请求平均大小为55 * 0.5 ~= 27.5K,出现了大量的小块写。
图2每秒磁盘写请求200左右,每个请求平均大小为800 * 0.5 ~= 400K,明显采用了批量落盘的策略。
再看%util 指标,这个不是我们通常理解的磁盘饱和度,而是磁盘使用率,其计算时只关注io请求数量,不理会每 个io请求的大小,即便达到了100,并不意味着磁盘吞吐已达上限。
假设某路段有1w辆私家车(每车只有1个人,avgrq-sz=1)同时通行,即便平均每秒放行10辆车(w/s=10),总体运 力也只有10人/s,若是改成50座大巴车(avgrq-sz=50),即便每秒只放行1辆车(w/s=1),总体运力也会提高到50 人/s。
在这个案例中,%util 记录的只是平均每秒通行的机动车数量,不关心每辆车坐了多少人,如果私家车的%util 是 100,那大巴车的%util只有10并且吞吐更高,跟上述截图描述的场景十分吻合。
关于max-write-buffer-size参数,pika官档原文如下:https://github.com/OpenAtomFoundation/pika/wiki/pika- %E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6%E8%AF%B4%E6%98%8E
# Pika 底层单个rocksdb单个memtable的大小, 设置越大写入性能越好但会在buffer刷盘时带来更大的IO负载, 请 依据使用场景合理配置 [RocksDb‐Tuning‐Guide](https://github.com/facebook/rocksdb/wiki/RocksDB‐Tuning‐Guide) write‐buffer‐size : 268435456 # pika实例所拥有的rocksdb实例使用的memtable大小上限,如果rocksdb实际使用超过这个数值,下一次写入会造成 刷盘 [Rocksdb‐Basic‐Tuning](https://github.com/facebook/rocksdb/wiki/Setup‐Options‐and‐Basic‐Tuning) max‐write‐buffer‐size : 10737418240
RocksDB采用WAL + LSM架构,memtable可以看作是用户数据落盘的基本单位,memtable越大则落盘时越倾 向于批量写,更能有效利用磁盘IO吞吐。

最初的参数文件没有设置max-write-buffer-size,只有write-buffer-size,奇怪的是调大write-buffer-size并不会 将前者自动增大,两者不具备联动关系。
我在压测时尝试调大write-buffer-size到1G(max-write-buffer-size保持默认值),性能依然上不去,看来是max- write-buffer-size起到了决定性作用。
经过多次压测,最终我们的主要参数设置如下:
thread‐num : 8 #和cpu核数相同 thread‐pool‐size : 8 write‐buffer‐size : 268435456 max‐write‐buffer‐size : 4294967296 compression : snappy max‐background‐flushes : 2 max‐background‐compactions : 2
3、结论
通过这个案例对iostat的输出指标有了更深一步的了解,以后再遇到%util达到100时先不要轻易作出磁盘IO已饱和 的结论,很可能是大量小IO请求导致的,可通过w/s和avgrq-sz进行辨别比较。
使用pika时,一定要设置max-write-buffer-size值,虽然和write-buffer-size参数名字很像,但两者没有联动关系 且max-write-buffer-size起到了决定性作用。
最后,我们的应用成功迁移到pika,相比之前的mongo集群节省了不少的机器资源开销,可见没有最好的DB,只有最适合的。