作者:杨家鑫
多点⾼级 DBA ,擅⻓故障分析与性能优化,喜欢探索新技术,爱好摄影。
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
背景
提⾼ TiDB 可⽤性,需要把多点已有上百T TiDB集群拆分出2套

挑战
-
现有需要拆分的12套TiDB集群的版本多(4.0.9、5.1.1、5.1.2都有),每个版本拆分⽅法存在不⼀样
-
其中5套TiDB,数据量均超过10T、最⼤的TiDB集群⽬前数据量62T、单TiDB集群备份集⼤,消耗⼤量磁盘空间和带宽资源
空间最⼤3套集群

-
tidb使⽤⽅式多样(每种⽅式拆分⽅法不同),有直接读写tidb,也有mysql->tidb汇总分析 查询,也有tidb->cdc->下游hive
-
全量备份TiDB在业务⾼峰期是否会产⽣性能影响
-
⼤数据量的拆分数据的⼀致性保证
⽅案
⽬前TiDB官⽅提供的同步⼯具有:
-
DM全量+增量(该⽅法⽆法⽤于tidb->tidb,适⽤于MySQL->TiDB) -
BR全量物理备份+CDC增量同步(CDC同步在tidb、tikv节点OOM后修复成本⾼https://github.co m/pingcap/tiflow/issues/3061) -
BR全量物理备份+binlog增量(类似于MySQL记录所有变更的binlog⽇志,TiDB binlog由 Pump(记录变更⽇志)+Drainer(回放变更⽇志)组成,我们采⽤该⽅法进⾏全量+增量同步拆分)
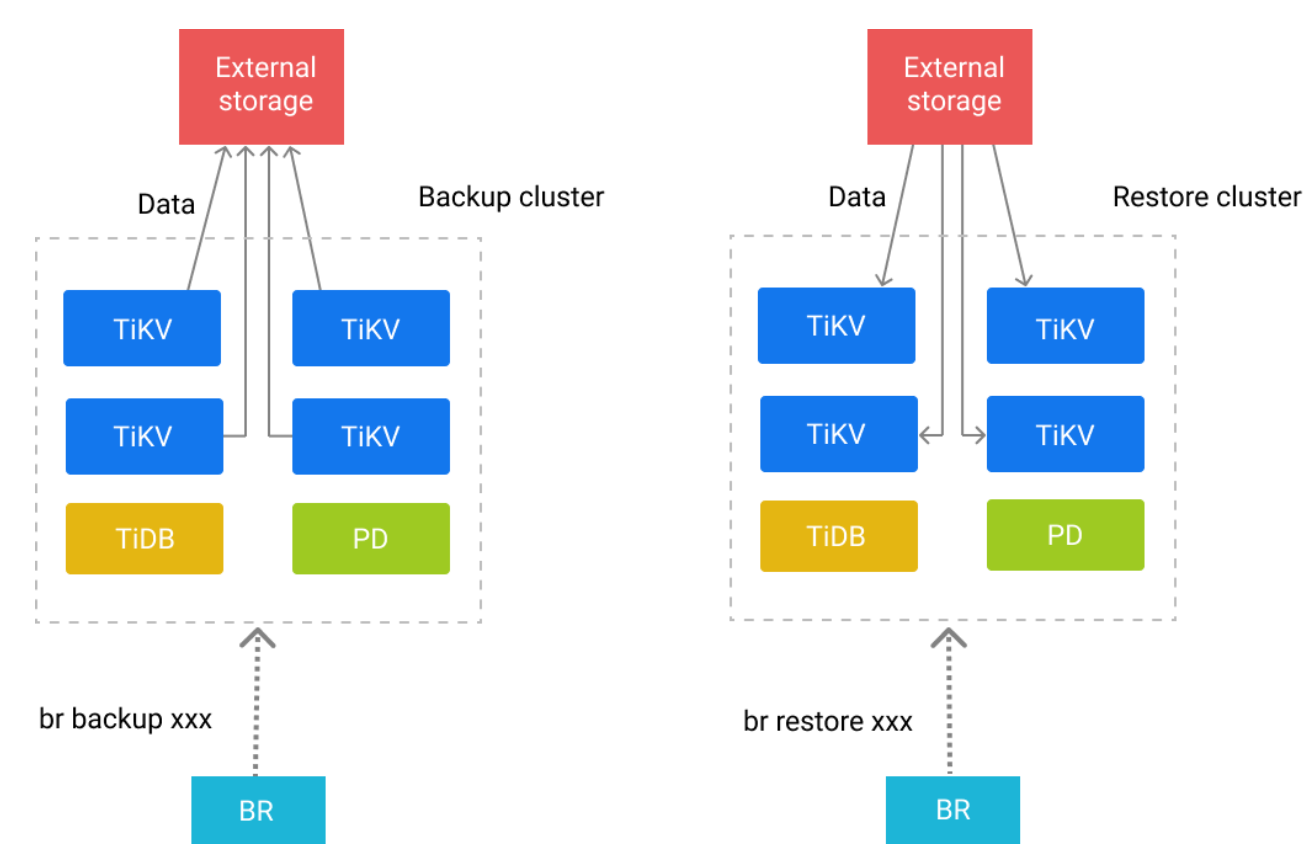
备份与恢复⼯具BR:https://docs.pingcap.com/zh/tidb/stable/backup-and-restore-tool
TiDB Binlog:https://docs.pingcap.com/zh/tidb/stable/tidb-binlog-overview
因TiDB拆分BR全量物理备份+binlog增量涉及周期⻓,我们分为4个阶段进⾏
第⼀阶段
1、清理现有TiDB集群⽆⽤数据
按⽉分表tidb库有⽆⽤的表,如3个⽉前的xxxx ⽇志表
2、升级GZ现有15套TiDB集群(12套TiDB集群需要1分为2)版本⾄5.1.2
趁这次拆分统⼀GZ tidb版本,解决挑战1
第⼆阶段
1、新机器部署好相同版本5.1.2TiDB集群
set @@global.tidb_analyze_version = 1;
2、⽬的端,源端所有tikv tiflash挂载好NFS,pd节点上安装好BR
Exteral storge采⽤腾讯云NFS⽹盘,保障tikv备份⽬的端和还原全量来源端都能在同⼀⽬录,NFS ⽹盘空间⾃动动态增加+限速备份以应对挑战2
3、独⽴3台机器部署好12套TiDB集群
pump收集binlog(端⼝区分不同TiDB集群) pump,drainer采⽤独⽴16C, 32G机器保障增量同步最⼤性能
注意:为保障tidb计算节点的可⽤性,需设置ignore-error binlog关键参数(https://docs.pingcap.com/zh/tidb/v5.1/tidb-binlog-deployment-topology)
server_configs:
tidb:
binlog.enable: true
binlog.ignore-error: true
4、修改pump组件 GC时间为7天
binlog保留7天保障全量备份->到增量同步过程能接上
pump_servers:
- host: xxxxx
config:
gc: 7
#需reload重启tidb节点使记录binlog⽣效
5、备份TiDB集群全量数据⾄NFS Backup & Restore 常⻅问题 (https://docs.pingcap.com/zh/tidb/v5.1/backup-and-restore-faq)
注意:每个TiDB集群在同⼀个NFS建不同备份⽬录
注意:源⽼TiDB集群分别限速(备份前后对读写延迟时间基本⽆影响)进⾏错峰全量备份(存在之前 多个TiDB集群同时备份把NFS 3Gbps⽹络带宽打满情况)以减轻对现有TiDB读写、NFS的压⼒以应 对挑战
mkdir -p /tidbbr/0110_dfp
chown -R tidb.tidb /tidbbr/0110_dfp
#限速进⾏全业务应⽤库备份
./br backup full \
--pd "xxxx:2379" \
--storage "local:///tidbbr/0110_dfp" \
--ratelimit 80 \
--log-file /data/dbatemp/0110_backupdfp.log
#限速进⾏指定库备份
./br backup db \
--pd "xxxx:2379" \
--db db_name \
--storage "local:///tidbbr/0110_dfp" \
--ratelimit 80 \
--log-file /data/dbatemp/0110_backupdfp.log
12.30号45T TiDB集群全量备份耗时19h,占⽤空间12T
[2021/12/30 09:33:23.768 +08:00] [INFO] [collector.go:66] ["Full backup succes s summary"] [total-ranges=1596156] [ranges-succeed=1596156] [ranges-failed=0] [backup-checksum=3h55m39.743147403s] [backup-fast-checksum=409.352223ms] [bac kup-total-ranges=3137] [total-take=19h12m22.227906678s] [total-kv-size=65.13T B] [average-speed=941.9MB/s] ["backup data size(after compressed)"=12.46TB] [B ackupTS=430115090997182553] [total-kv=337461300978]
6、每个新建TiDB集群单独同步⽼TiDB集群⽤⼾密码信息
注意:BR全量备份不备份tidb mysql系统库,应⽤、管理员⽤⼾密码信息可⽤开源pt-toolkit⼯具 包pt-show-grants导出
7、恢复NFS全量备份⾄新TiDB集群
注意:新TiDB集群磁盘空间需充裕,全量备份还原后新TiDB集群占⽤空间⽐⽼TiDB集群多⼏个 T,和官⽅⼈员沟通是由于还原时⽣成sst的算法是lz4,导致压缩率没有⽼TiDB集群⾼
注意:tidb_enable_clustered_index,sql_mode 新⽼TiDB集群这2参数必须⼀致
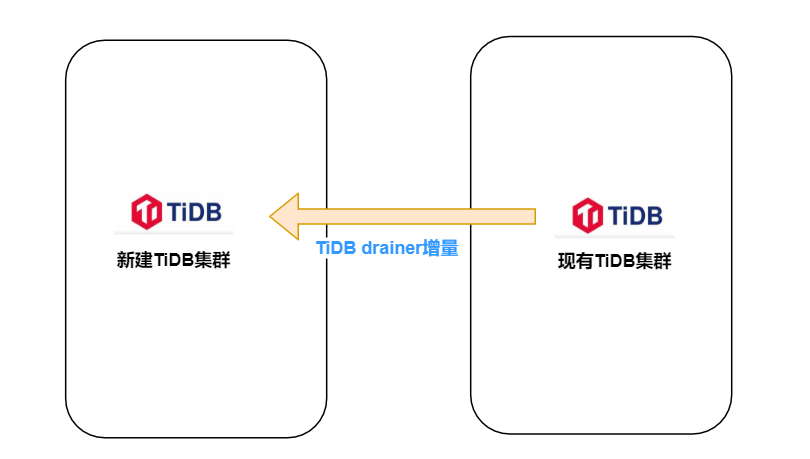
8、tiup扩容drainer进⾏增量同步
扩容前确认下游checkpoint信息不存在或已清理
如果下游之前接过drainer,相关位点在⽬标端tidb_binlog.checkpoint表中,重做的时候需要清理
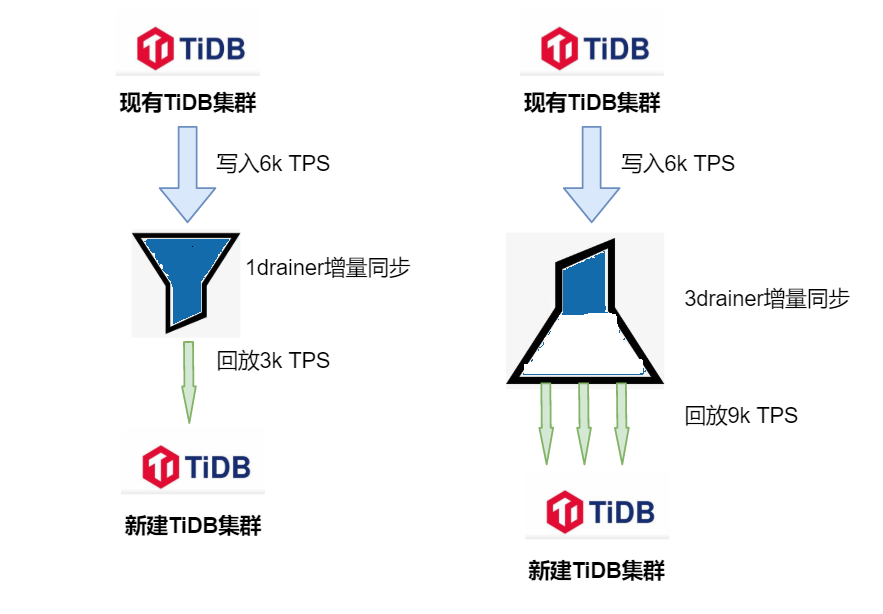
注意:因源最⼤TiDB集群⻓期平均写⼊TPS在6k左右,在增⼤worker-count回放线程数后,尽管 ⽬的端域名解析到3个tidb节点,单个drainer增量还是⽆法追上延迟(回放速度最⾼在3k TPS),后和TiDB官⽅沟通改成按3个drainer(不同drainer同步不同库名)并⾏增量同步延迟追上(3个 drainer增量让“漏⽃”没有堆积,源流⼊端数据能及时到达⽬标流出端)
注意:多个drainer并⾏增量必须指定⽬的端checkpoint.schema为不同库drainer配置说明
#从备份⽂件中获取全量备份开始时的位点TSO
grep "BackupTS=" /data/dbatemp/0110_backupdfp.log
430388153465177629
#第⼀次⼀个drainer进⾏增量同步关键配置
drainer_servers:
- host: xxxxxx
commit_ts: 430388153465177629
deploy_dir: "/data/tidb-deploy/drainer-8249"
config:
syncer.db-type: "tidb"
syncer.to.host: "xxxdmall.db.com"
syncer.worker-count: 550 1516
#第⼆次多个drainer进⾏并⾏增量同步
drainer_servers:
- host: xxxxxx
commit_ts: 430505424238936397 #该位点TSO为从第⼀次1个drainer增量停⽌后⽬的端ch eckpoint表中的Commit_Ts
config:
syncer.replicate-do-db: [db1,db2,....]
syncer.db-type: "tidb"
syncer.to.host: "xxxdmall.db.com"
syncer.worker-count: 550
syncer.to.checkpoint.schema: "tidb_binlog2"
1个drainer进⾏增量延迟越来越⼤
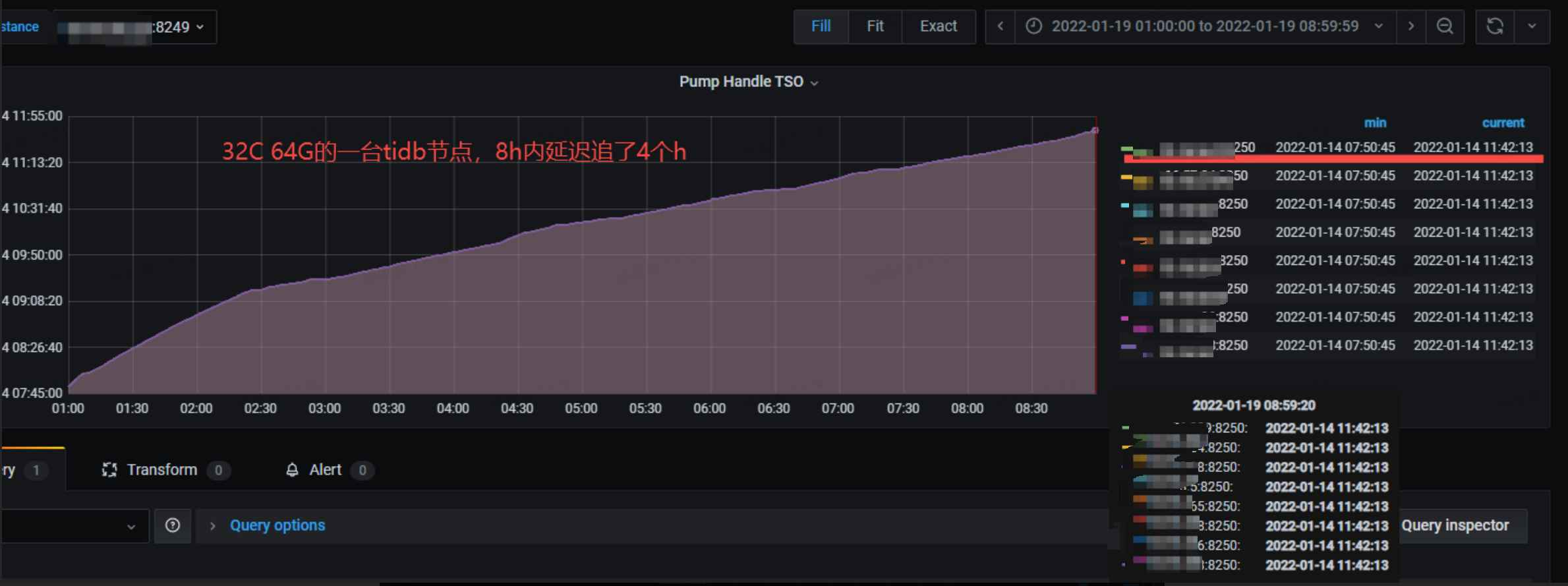
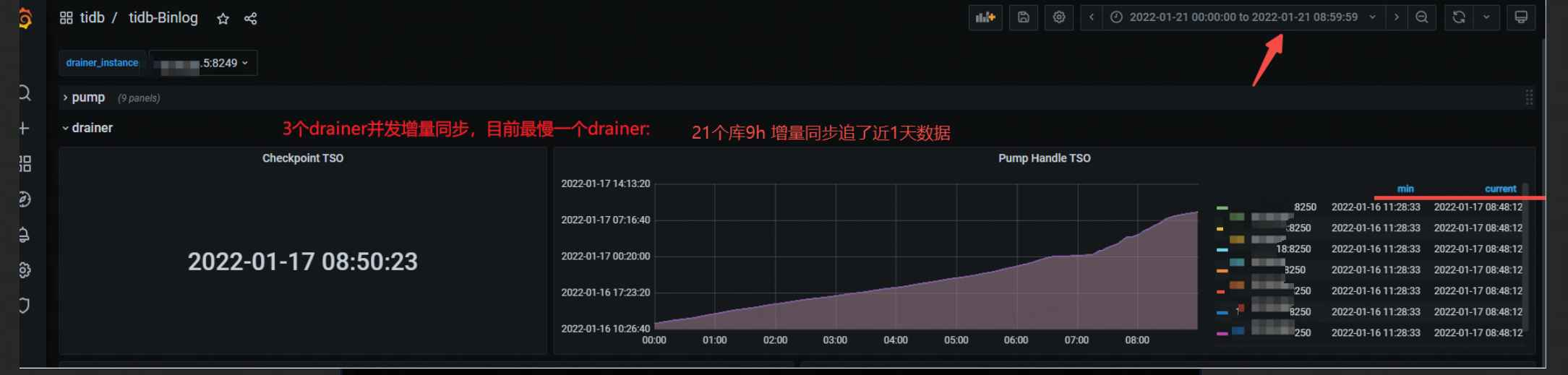
3个drainer进⾏并⾏增量同步最慢⼀条增量链路:9h追了近1天数据
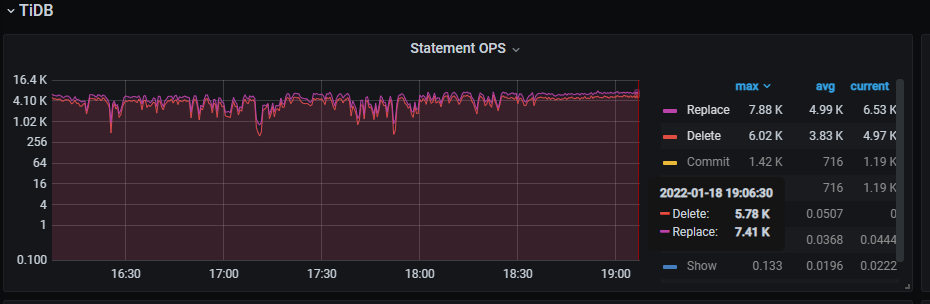
3个drainer并⾏同步⽬的端写⼊1.2w TPS > 源端6k写⼊TPS
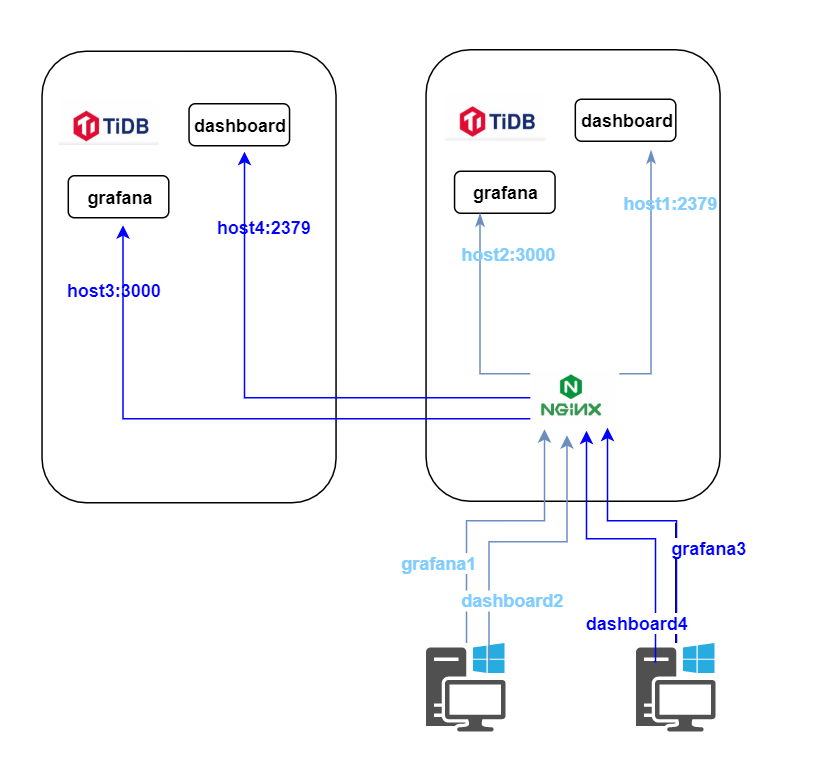
9、配置新建tidb grafana&dashboard域名
建grafana、dashboard的域名指向⽣产nginx代理,由nginx代理grafana 端⼝,dashboard 端⼝
第三阶段
1、check新⽼TiDB集群数据同步⼀致性情况
TiDB在全量和增量时会⾃⾏进⾏数据⼀致性校验,我们主要关注增量同步延迟情况,并随机 count(*)源⽬的端表
#延迟检查⽅法⼀:在源端TiDB drainer状态中获取最新已经回复TSO再通过pd获取延迟情况
mysql> show drainer status;
+-------------------+-------------------+--------+--------------------+------- --------------+
| NodeID | Address | State | Max_Commit_Ts | Update_Time |
+-------------------+-------------------+--------+--------------------+------- --------------+
| xxxxxx:8249 | xxxxxx:8249 | online | 430547587152216733 | 2022-01-21 16:50:58 |
tiup ctl:v5.1.2 pd -u http://xxxxxx:2379 -i
» tso 430547587152216733;
system: 2022-01-17 16:38:23.431 +0800 CST
logic: 669
#延迟检查⽅法⼆:在grafana drainer监控中观察
tidb-Binlog->drainer->Pump Handle TSO中current值和当前实际时间做延迟⽐较
曲线越陡,增量同步速率越快
2、tiflash表建⽴&CDC同步在新TiDB集群建⽴&新mysql->tidb汇总同步链路闭环(DRC-TIDB)
tiflash 源端tidb⽣成⽬的端 新建tiflash语句
SELECT * FROM information_schema.tiflash_replica WHERE TABLE_SCHEMA = '' and TABLE_NAME = ''
SELECT concat('alter table ',table_schema,'.',table_name,' set tiflash replica 1;') FROM information_schema.tiflash_replica where table_schema like 'dfp%';
CDC链路闭环 在⽼TiDB CDC同步中选取1个TSO位点在新TiDB中建⽴CDC⾄kafka topic同步
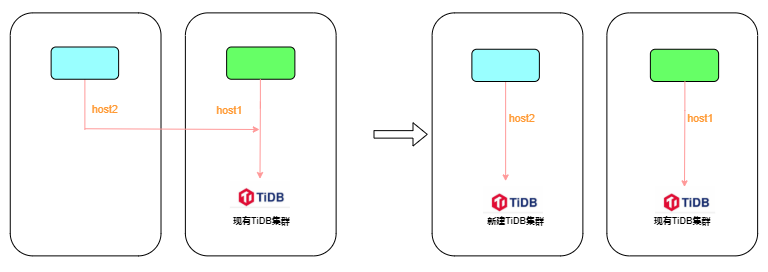
DRC-TIDB链路闭环(⾃研mysql->tidb合库合表同步⼯具)
上图左右为DRC-TIDB拆分前后状态1、左⽼drc-tidb同步规则copy到右新drc-tidb,不启动drc-tidb同步(记录当前时间T1)
2、drainer同步现有TiDB数据⾄新建TiDB链路启⽤安全模式replace(syncer.safe-mode: true)插⼊
3、修改左drc-tidb同步源⽬的地址为闭环,并启动drc-tidb(记录当前时间T2)
4、右tidb grafana drainer监控中check当前同步时间checkpoint是否>=T2(类似于tikv follower- read),若没有则等待延迟追上
5、右tidb集群增量同步修改edit-config drainer配置⽂件,去掉mysql-tidb同步的库名(所有库同 步增加指定库名同步)并reload drainer节点


commit_ts: 431809362388058219
config:
syncer.db-type: tidb
syncer.replicate-do-db:
- dmall_db1 该DB为直接读写
- dmall_db2 该DB为从mysql同步⽽来,需去掉
6、修改右drc-tidb同步源⽬的地址为闭环,并启动右drc-tidb(drc-tidb采⽤幂等同步,会重复消 费copy同步规则T1时间到现在的mysql binlog)
3、每个新TiDB集群ANALYZE TABLE更新表统计信息
不是必须,更新统计信息为最新可以避免查询sql索引选择⾛错
第四阶段
1、左tidb集群应⽤域名解析⾄新建tidb计算节点
2、批量kill右TiDB集群左应⽤的连接
存在脚本多次批量kill tidb pid;在右tidb节点依然有⼤量左应⽤的连接,因此左应⽤滚动重启后右
tidb节点左应⽤连接释放
3、移除⽼TiDB集群->新TiDB集群增量同步drainer链路
注意:因多个TiDB集群共⽤的1台⾼配drainer机器,node_exporter(采集机器监控agent)也是多 个TiDB集群共⽤,当A TiDB集群停⽌drainer链路,B C TiDB集群会报node_exporter不存活告警
总结
-
不同TiDB版本的升级统⼀版本很有必要,⼀是拆分⽅法的通⽤,减少拆分的复杂度,⼆是享受新 版本的特性,减低运维管理成本 -
⽬标TiDB集群磁盘空间需⾜够充裕 -
在源TiDB写⼊压⼒⼤时增量同步binlog到⽬的端的延迟保障需要drainer按库名进⾏并发增量同步 -
TiDB拆分涉及步骤多,能提前做的步骤就提前做,真正拆分的时间窗⼝很短 -
感谢TiDB官⽅社区对我们的技术⽀持,路漫漫其修远兮,我们将上下⽽求索