作者:任坤
现居珠海,先后担任专职 Oracle 和 MySQL DBA,现在主要负责 MySQL、mongoDB 和 Redis 维护工作。
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
1、背景
线上有套10节点clickhouse集群,5分片 * 2副本,版本19.7.3。
开发执行一个创建分布式表的操作,9个节点都成功返回,有个节点报错,返回信息如下:
Code: 159. DB::Exception: Received from 127.0.0.1:9000. DB::Exception: Wa
tching task /clickhouse/task_queue/ddl/query‐0003271440 is executing longer
than distributed_ddl_task_timeout (=180) seconds. There are 1 unfinished ho
sts (0 of them are currently active), they are going to execute the query i
n background.
2、诊断
登录该节点查看show processlist,正在执行1个分布式ddl,该ddl已经运行100多个小时,应该是卡住了。
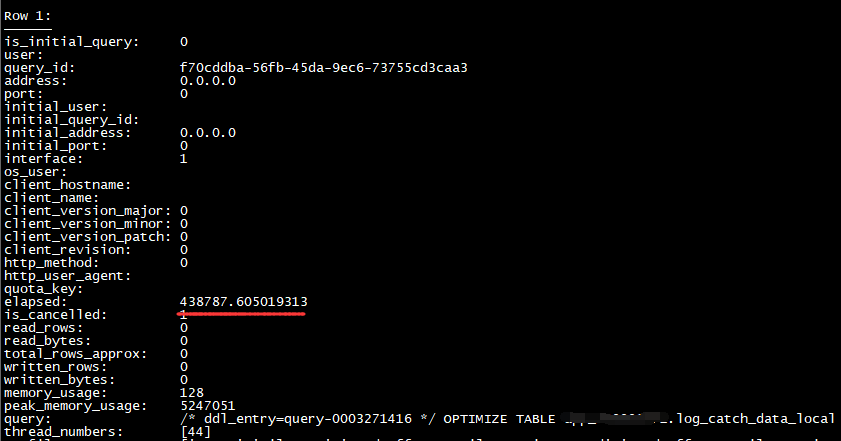
clickhouse的分布式ddl是串行执行的,每次将任务存储到zookeeper
的/clickhouse/task_queue/ddl目录,按照FIFO排列。
对于每个节点,只有当前的ddl执行完毕,后面的才能被调用。
select * from zookeeper where path='/clickhouse/task_queue/ddl' order by ctime desc\G
刚刚发起的创建分布式表ddl排在第一位,上述截图中的optimize table排在第23,说明被其阻塞的ddl有22条之多,开发也确认最近两天的ddl任务在该节点上都没有成功。
尝试将其kill,等待几个小时仍然没有效果。

加sync关键字,直接卡住。

尝试重启ck实例也卡住,最后只能Kill -9。
重启实例后该任务依然存在,而且执行了10多分钟没有要结束的意思,kill操作仍然无效。
既然这个ddl无法绕过,执行的时候又长时间不结束,只能曲线救国,重命名该表让其临时消失一会。
rename table log_catch_data_local to log_catch_data_local1;
optimize table当即返回,并且其后22个ddl也很快执行完毕,最后再将其重命名回原表。
此时再次执行optimize table,只需5s便成功返回,该问题解决。
3、总结
clickhouse的分布式ddl在每个节点是FIFO串行执行的,任意1个ddl卡住了都会阻塞后续任务。
本例中的卡住的ddl是optimize table,可以通过重命名表跳过;如果是增删列,可以在rename后手工对该表执行本地ddl。
如果上述方法都不行,可以在出问题的节点将本地表直接drop,等待所有阻塞ddl执行完毕后,重新创建1个空表,会自动从另一个副本中同步数据。
最后,19.x版本已经很旧了,我们在使用过程中遭遇了各种问题,要尽快升级到20.x系列