
引言
一般来说讲,提到数据拆分,可以归结为两个层面:一是垂直拆分,二是水平拆分。这里我们来讨论下垂直拆分。
垂直拆分是以数据库、表、列等为单位进行拆分的方法。
正文
MySQL里垂直拆分可以细分为:垂直拆库(实例级别)、垂直拆模(表级别)、垂直拆表(列级别)。
1、垂直拆库:
也即在业务层按照业务逻辑由大拆小,各个子业务之间无关联查询,仅查询单个子业务即可,类似微服务治理的思想。在 MySQL 里表现为将全部表按照业务关联紧密程度拆分后存储在不同的数据库,每个数据库为一台 MySQL 实例,查询仅查对应的数据库实例即可。
如图1所示:
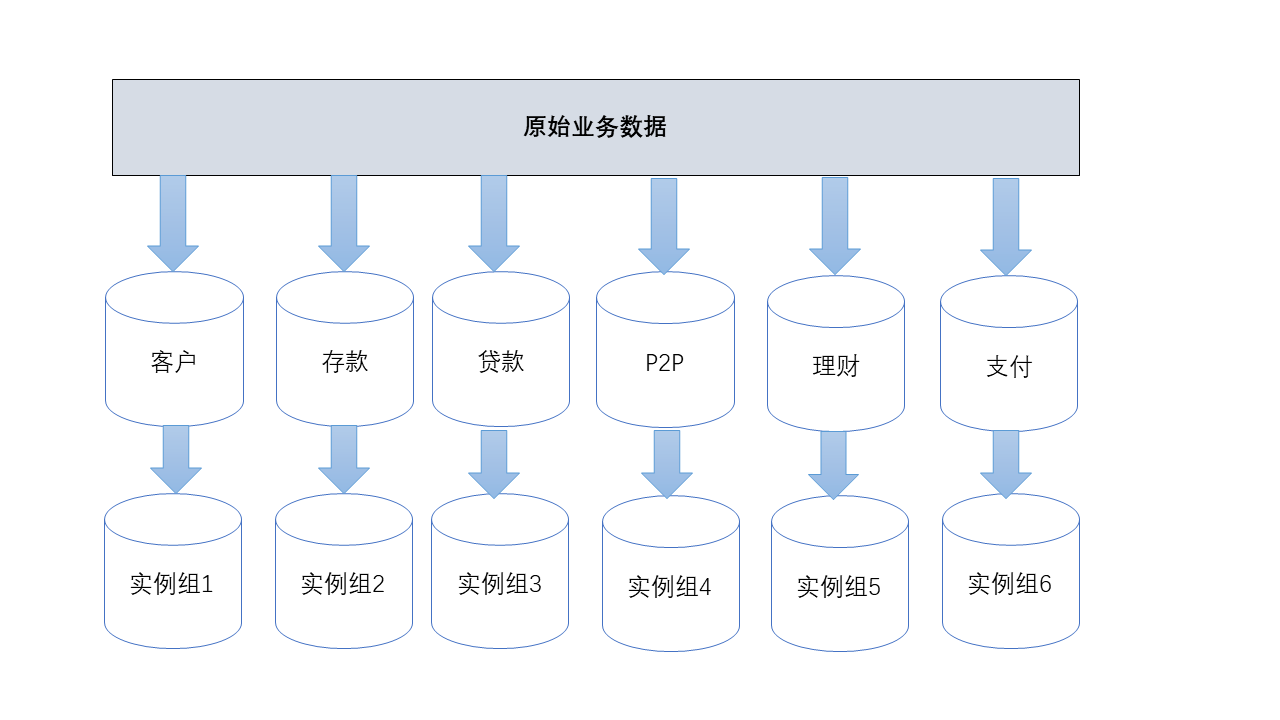
上图展示出原始业务数据的拆分示例,按照不同的业务逻辑分类划分为多个子业务,每个子业务对应一套 MySQL 实例组,每个 MySQL 实例组按照 MySQL 的 HA 架构部署(主从同步、组复制、MySQL CLUSTER等)
图1的优点很明显,原始业务的压力分散到各个小业务上,提升了整体的性能。但也不能忽略缺点:数据库对应用端不透明,应用端必须自己维护路由数据;当单个实例数据量以及请求再次到达上限时,后续拆分非常困难。
2、垂直拆模:
垂直拆模和垂直拆库大体类似,不过垂直拆模的最小单元是 schema ,而不是实例。大家知道,MySQL 的数据库等同于 schema , 一个数据库对应磁盘上的一个文件目录。这种拆分一般是为了解决文件系统中单个目录里文件个数过多导致的性能降低。
如图2所示:
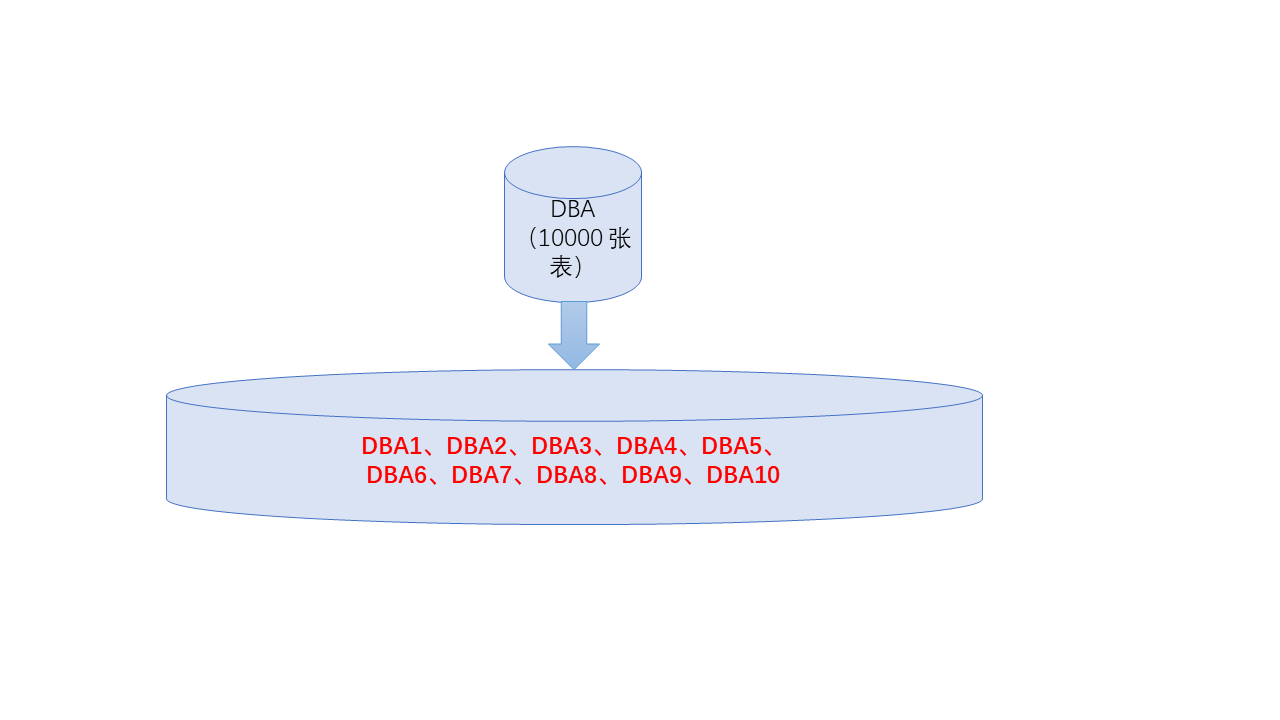
图2显式了比如一个数据库 dbA , 里面含有10000张表,每1000张表单独划分为一个数据库,比如dbA1,dbA2,…,db10;每个数据库的数据无论从物理还是逻辑上都独立的。
举个例子说明下在数据库端垂直拆模的步骤以及对写入和查询请求的影响:
数据库 ytta 下有10000张表,表名分别为t1到t10000.
(debian-ytt1:3500)|(ytta)>select count(*) from information_schema.tables where table_schema='ytta';
+----------+
| count(*) |
+----------+
| 10000 |
+----------+
1 row in set (0.04 sec)
此处把这10000张表平均垂直拆分到数据库 ytt1 到 ytt10 里。
先创建10个数据库 ytt1-ytt10 。
ytt@debian-ytt1:~/mysql-sandboxes/3500/sandboxdata$ for i in `seq 1 10`; \
> do mysql -S mysqld.sock -uroot -proot -e "create database ytt$i";done;
分别往这10个数据库中 COPY 原始数据库的表结构以及数据:
这里采用拷贝表空间的做法(前提是数据库 ytta 下的表都是单表空间,如果非单表空间建议提前转换为单表空间)
对这个10个数据库分别创建对应的表结构;完了删掉初始表空间文件。
root@debian-ytt1:/home/ytt# for i in `seq 0 9`; \
> do for j in `seq 1 1000`; \
> do x=$((j + i * 1000)); \
> mysql -uroot -proot -hdebian-ytt1 -P3500 \
> -e "use ytta;create table ytt$((i+1)).t$x like ytta.t$x;alter table ytt$((i+1)).t$x discard tablespace;"; \
> done; \
> done;
拷贝表空间需要原始表的表空间文件以及.cfg 配置文件。批量 flush 10000张表,导出对应的 .cfg 文件。
SESSION 1:
MySQL Py > conn1 = 'mysql://root:root@debian-ytt1:3500/ytta'
MySQL Py > rs = mysql.get_classic_session(conn1);
MySQL Py > tb_list = []
MySQL Py > for i in range(1,10001):tb_list.append('t' + str(i))
MySQL Py > tb_lists = ','.join(tb_list);
MySQL Py > rs.run_sql('flush tables ' + tb_lists + ' for export');
Query OK, 0 rows affected (46.0182 sec)
检验数据库 ytta 下所有表是否已经生成.cfg文件
root@debian-ytt1:/home/ytt/mysql-sandboxes/3500/sandboxdata/ytta# ls -l t* | wc -l
20000
开始拷贝表空间文件
root@debian-ytt1:/home/ytt/mysql-sandboxes/3500/sandboxdata/ytta# for i in `seq 0 9`; \
> do for j in `seq 1 1000`; \
> do x=$((j + i * 1000)); \
> cp -rfp t$x.cfg t$x.ibd ../ytt$((i + 1))/; \
> done; \
> done;
回到 SESSION 1 来解锁数据库 ytta 下的所有表
MySQL Py > rs.run_sql('unlock tables')
Query OK, 0 rows affected (4.5235 sec)
分别在各个数据库下导入表空间
MySQL Py > for i in range(1,11):
-> for j in range(1,1001):
-> x = j + (i - 1) * 1000
-> rs.run_sql('alter table ytt'+ str(i) +'.t' + str(x) + ' import tablespace')
->
Query OK, 0 rows affected, 0 warning (0.0973 sec)
以上即为在 MySQL 里垂直拆模的大致步骤。
垂直拆模的优点是没有动表结构和数据,只是把表结构和数据隔离到不同的数据库,在逻辑层面上可读性更强,代码改写量非常小。比如原来在数据库 ytta 的 SQL 如下:
select * from t1 join t1001 using(id) join t2001 using(id);
可以更改为:
select * from ytt1.t1 join ytt2.t1001 using(id) join ytt3.t2001 using(id);
跨库写入也一样,直接带入数据库名即可。
3、垂直拆表:
拆分的基本单元是表,而非实例或者数据库模式,将一张表按照字段的被访问频次拆分为不同的表。比如一张表有1000个字段, 按照字段被访问的频次来讲,前100个字段经常被访问,单独划分为一个分表;后面900 个字段不经常访问,划分为另外一个分表。
如图3所示:
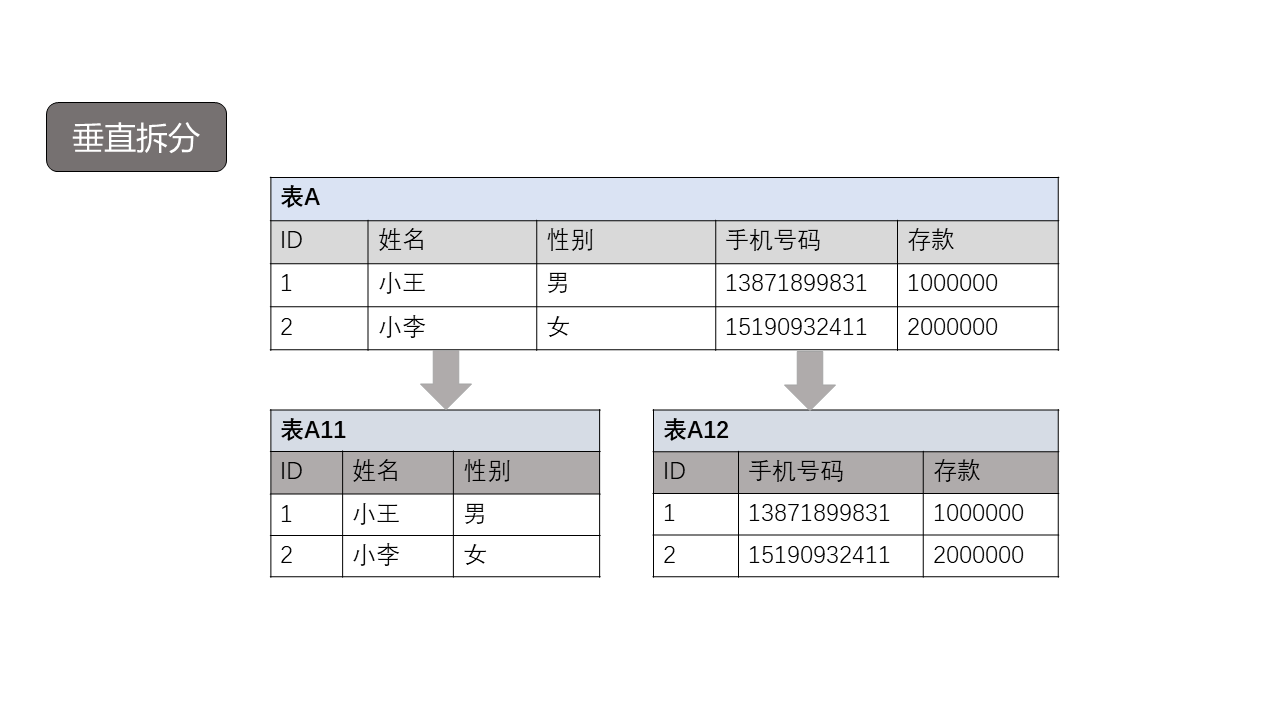
上图表A含有5个字段,其中1个主键字段,另外4个非主键字段;按照字段被访问频次不同拆分为两张表A11,A12,两张表拥有同样的主键字段,有点类似我们常说的热表与冷表。
来看看在 MySQL 里实现垂直拆表的简单示例:
建立一张1000个字段的表 t_large(包含主键ID,字段为1001个),并插入1W行记录:
MySQL Py > field_list=[]
MySQL Py > for i in range(1,1001):field_list.append('r' + str(i) + ' int');
MySQL Py > field_lists=','.join(field_list);
MySQL Py > rs.run_sql('create table t_large(id serial primary key,' + field_lists + ')');
Query OK, 0 rows affected (0.6012 sec)
MySQL Py > v_list=[]
MySQL Py > for i in range(1000,2000):v_list.append(str(i));
MySQL Py > v_lists=','.join(v_list)
MySQL Py > for i in range(1,10001):rs.run_sql('insert into t_large select null,'+ v_lists);
Query OK, 1 row affected (0.0109 sec)
Records: 1 Duplicates: 0 Warnings: 0
MySQL Py > rs.run_sql('select count(*) from t_large');
+----------+
| count(*) |
+----------+
| 10000 |
+----------+
1 row in set (0.0671 sec)
按照字段个数,把这表拆成100张小表,每张表字段数为11个(包含主键字段),并且从原表 t_large 里抽取相应的记录。
MySQL Py > for i in range(1,101):
-> f_list1 = []
-> f_list2 = []
-> for j in range(1,11):
-> f_list1.append('r' + str(j + (i-1)*10) + ' int')
-> f_list2.append('r' + str(j + (i-1)*10))
-> rs.run_sql('create table t_large' + str(i) +'( id serial primary key,'+ ','.join(f_list1) + ')')
-> rs.run_sql('insert into t_large' + str(i) +' select id,' + ','.join(f_list2) + ' from t_large')
->
Query OK, 10000 rows affected (1.0415 sec)
Records: 10000 Duplicates: 0 Warnings: 0
假设表 t_large 原先10个字段频繁的被读取,那之后值需要读取表 t_large1 即可,写法上也简洁许多。
原 SQL :
select id,r1,r2,r3,r4,r5,r6,r7,r8,r9,r10 from t_large;
可以替换为:
select * from t_large1;
表更新的性能也有一定提升。原表更新:
MySQL Py > rs.run_sql('update t_large set r1 = ceil(rand()*10000)');
Query OK, 10000 rows affected (8.4471 sec)
Rows matched: 10000 Changed: 10000 Warnings: 0
仅更新字段r1,只需更新对应的拆分表即可。时间上比更新原表要快几十倍。
MySQL Py > rs.run_sql('update t_large1 set r1 = ceil(rand()*10000)');
Query OK, 10000 rows affected (0.5160 sec)
Rows matched: 10000 Changed: 10000 Warnings: 0
总结:
垂直拆分方法基本上分为三类: 垂直拆库(MySQL 里可以叫垂直拆实例)、垂直拆模(MySQL 里的垂直拆库)、垂直拆表。总体来说,垂直拆分的优缺点大致如下:
优点:
-
逻辑上业务更清晰,更容易梳理。 -
对 IO 以及连接数在一定程度上能够得到改善。
缺点:
-
单个分片性能如果到达瓶颈,很难进行更细粒度的切分。 -
拆分很难做到足够彻底,各个分片避免不了低频次的表关联。
关于 MySQL 的技术内容,你们还有什么想知道的吗?赶紧留言告诉小编吧!
