““

问
MySQL 中在运行一个 DDL , 此时我们对这个 DDL 进行 kill , 那这个 DDL 多久会被 kill 掉?
要讨论这个问题, 我们需要拆分问题: DDL 多久会被 kill 掉 = DDL 多久会开始 kill + DD L的回滚收尾操作进行了多久
本实验只讨论如何观察: DDL 多久会开始 kill
实验
参考第16问, 我们起一个数据库, 并让其在调试模式运行.
首先宽油起一个数据库实例:

改一下 start 脚本, 配置成调试模式:
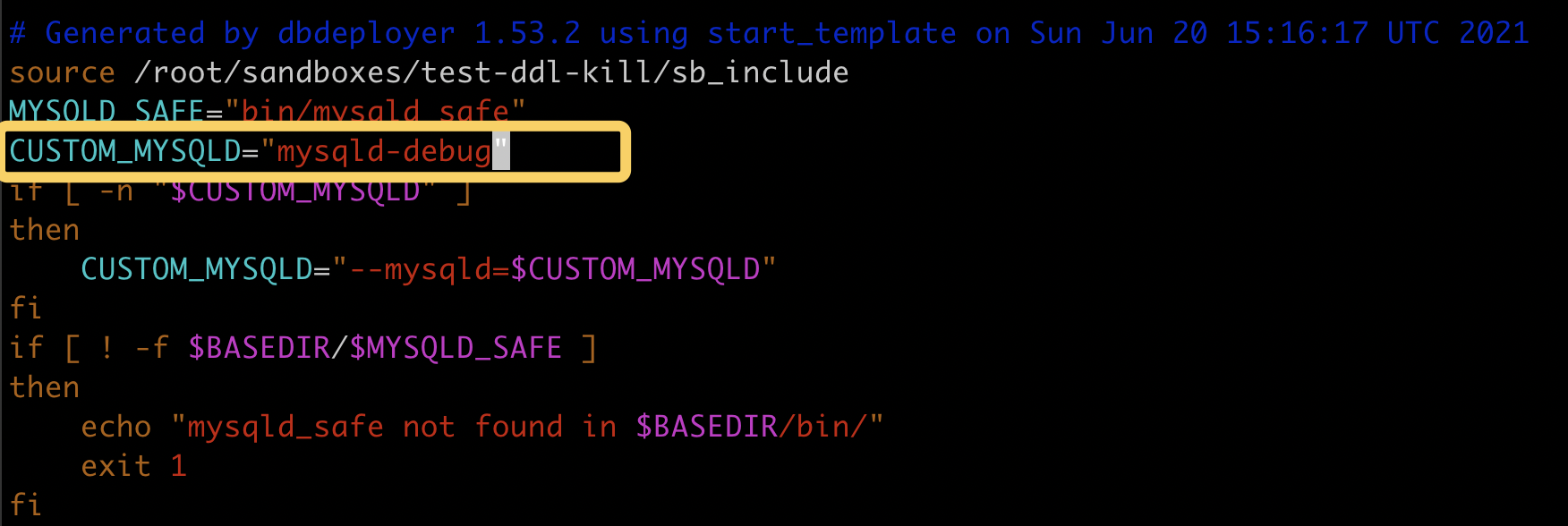
重启数据库, 启动的时候增加 –debug 参数:

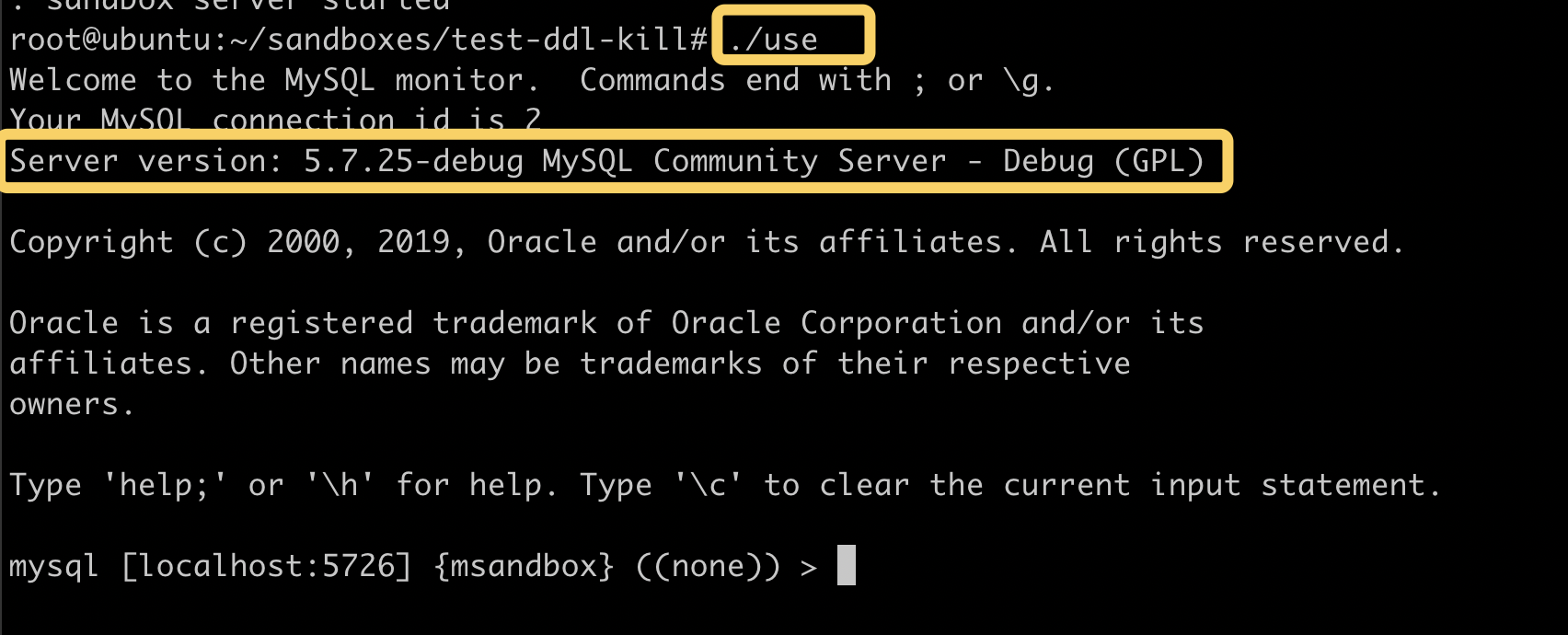
访问数据库, 确认是调试版本:
创建一张简单的表, 塞 4 行数据进去:

现在写一个简单的 gdb 脚本:
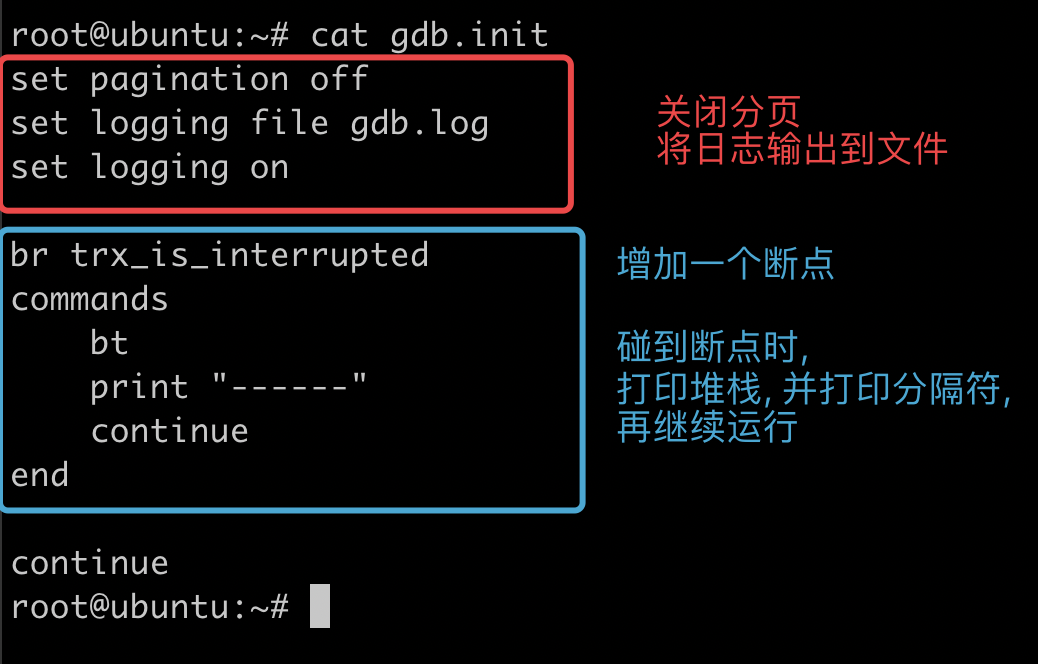
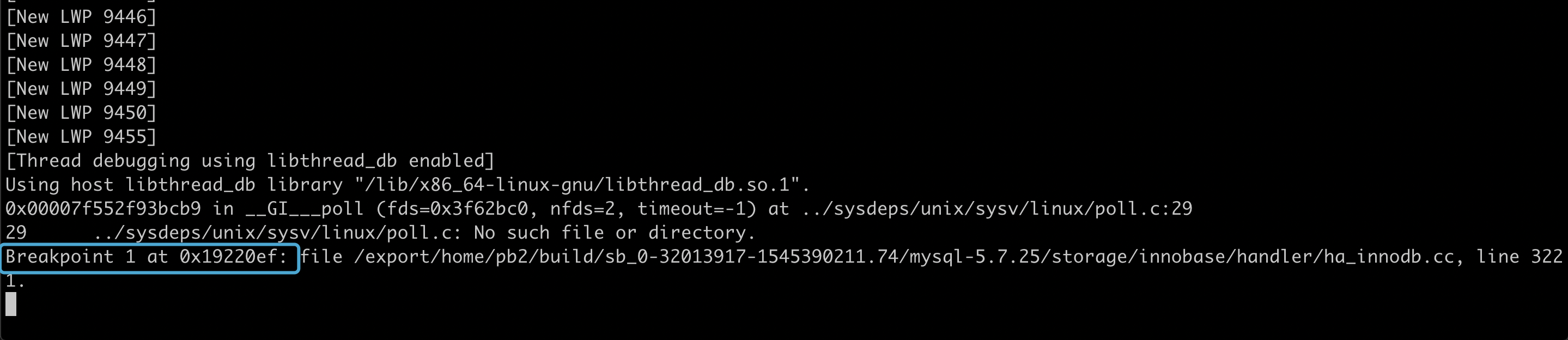
这个脚本里, 我们在 trx_is_interrupted 函数上设置了一个断点.
trx_is_interrupted 函数是 InnoDB 检查当前线程是否被 kill 的函数, 当调用这个函数时,InnoDB 才会检查当前是否有 kill 操作, 如果有, 则进行相应的处理.
(想知道应该在哪个函数打断点, 可以寻求开发同学的帮助)
当 gdb 运行到这个断点时, 我们让 gdb 打印当时的堆栈, 以及一条分割线, 这样我们就能看到是哪个流程调用了这个函数
然后开启 gdb , 这里使用了我们之前写的脚本:
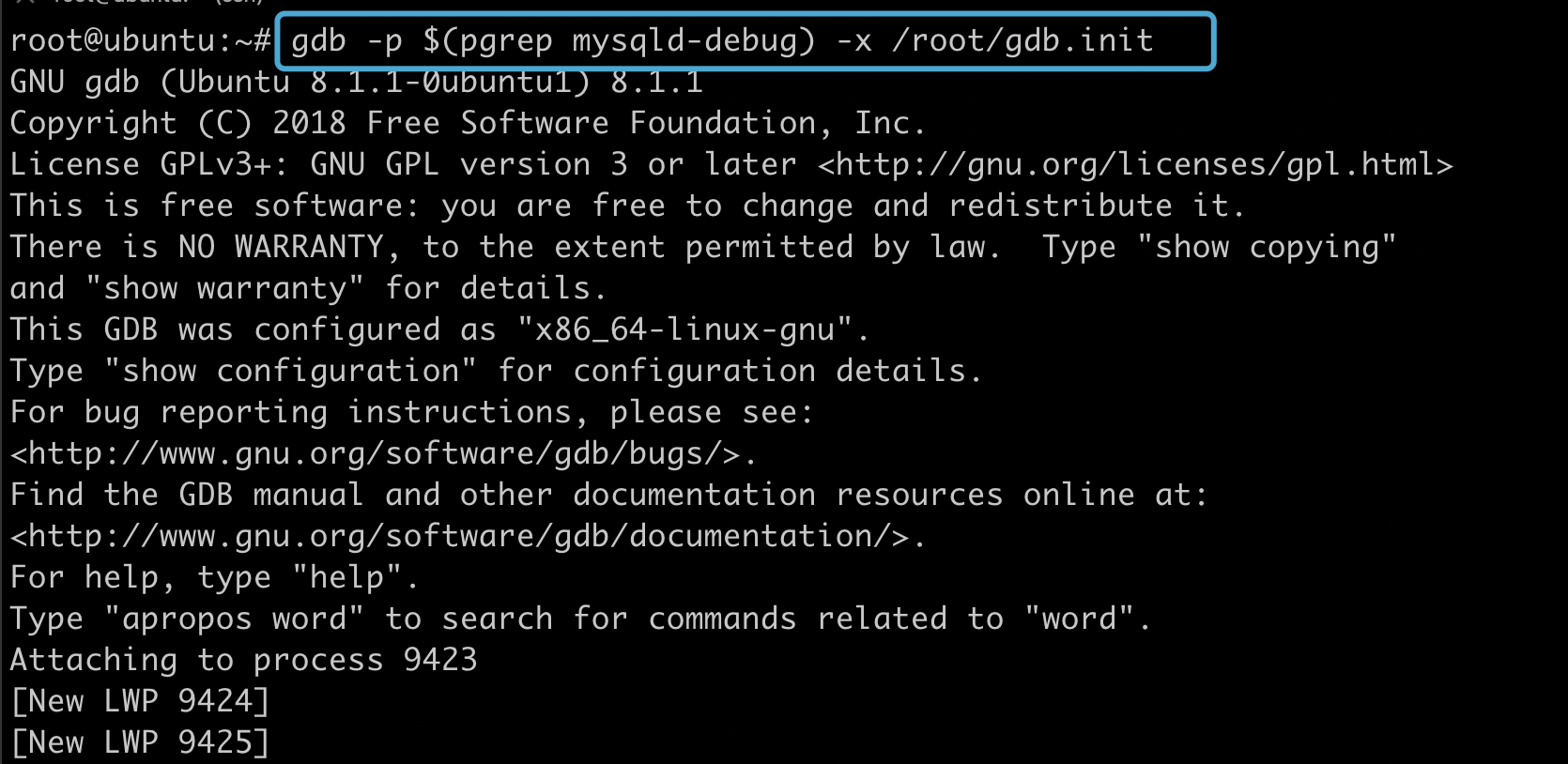
不需任何操作, 断点已经按我们的脚本添加好了
现在在 MySQL 中触发一个 alter :

找到我们指定的 gdb 日志文件:
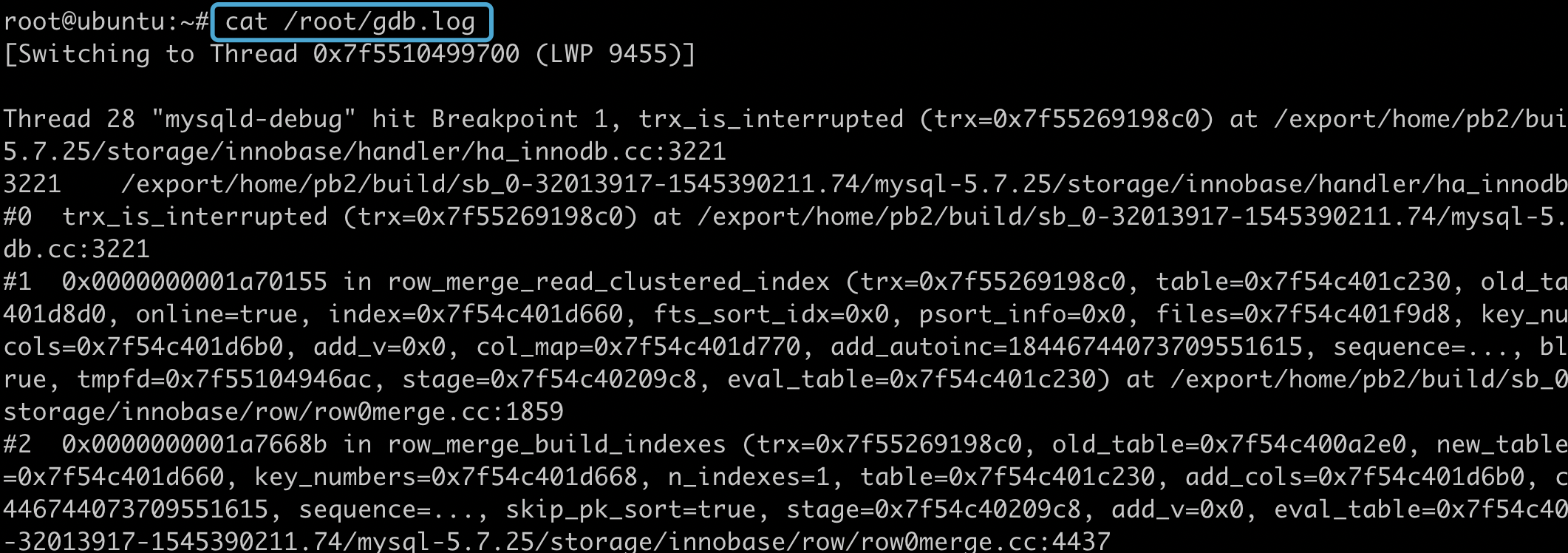
可以看到里面密密麻麻的写满了堆栈信息, 此时不要慌, 我们将其复制到文本编辑器里, 一点一点来分析:
第一个堆栈:
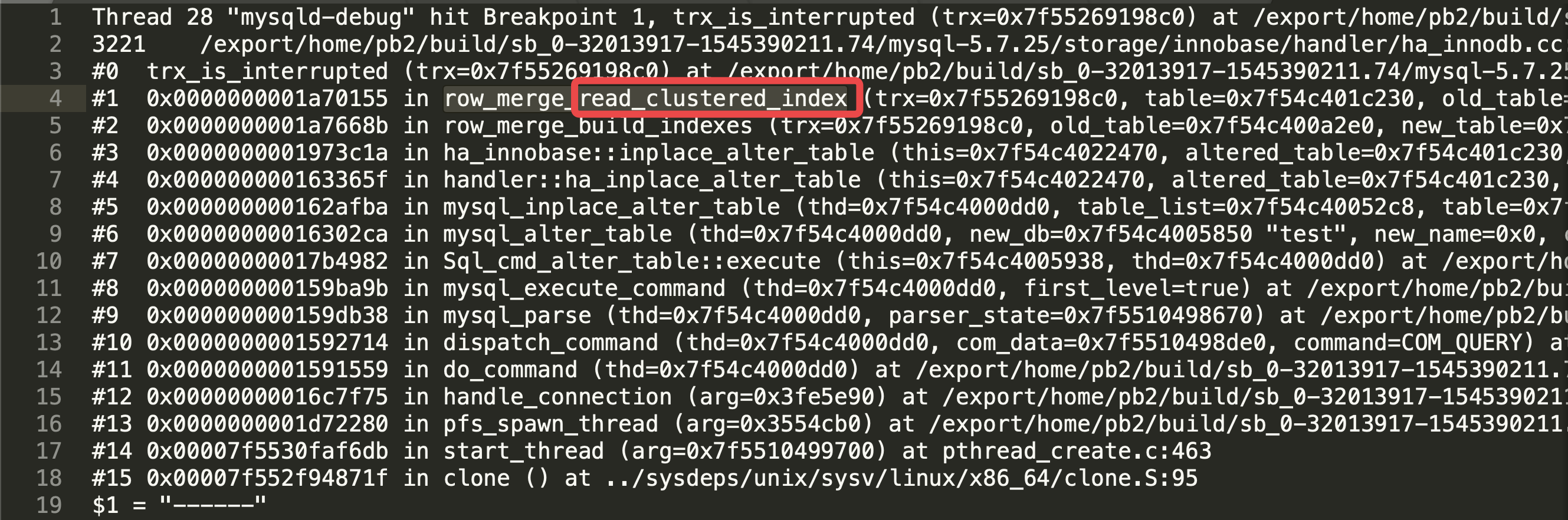
我们认出了一个 read clustered index , 也就是读取聚簇索引的过程中, MySQL 会检查当前线程是否被 kill
第二个堆栈:
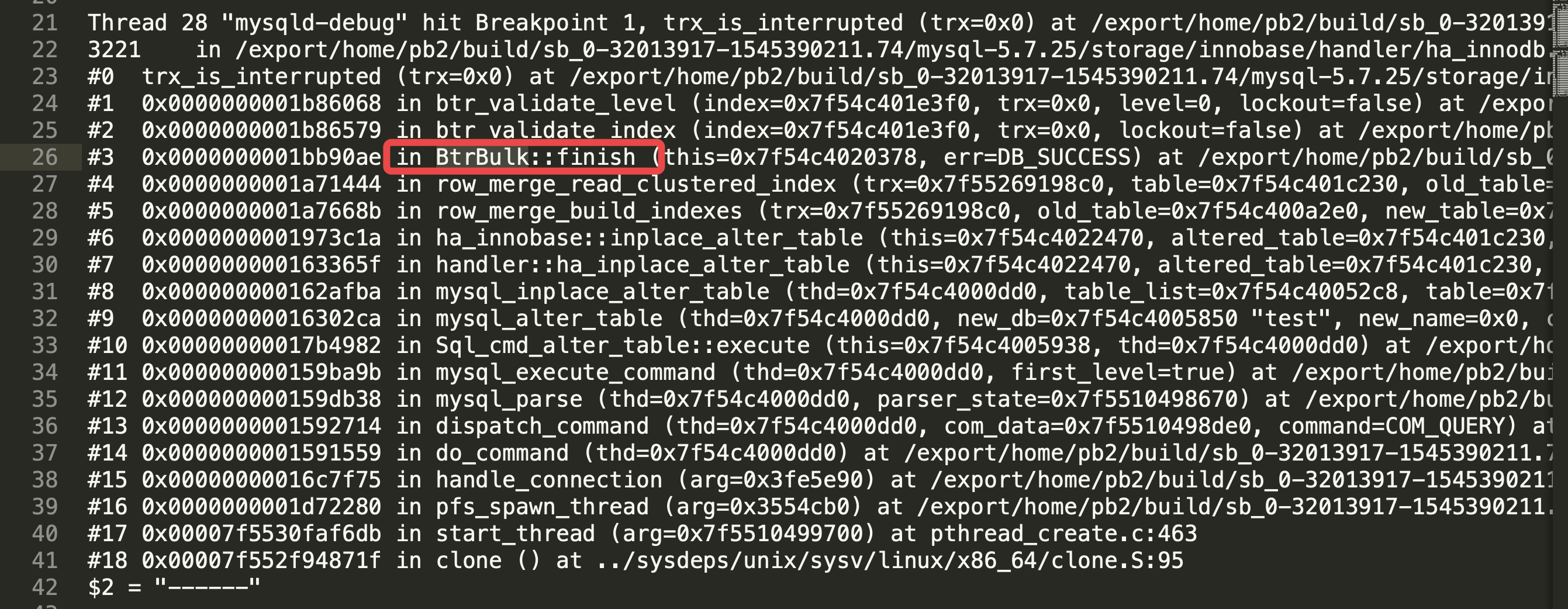
我们认出了 BtrBulk , Btr 是 B-tree 的缩写, 也就是在对 B-tree 进行批量插入的过程中, MySQL 会检查当前线程是否被 kill
第三个堆栈:
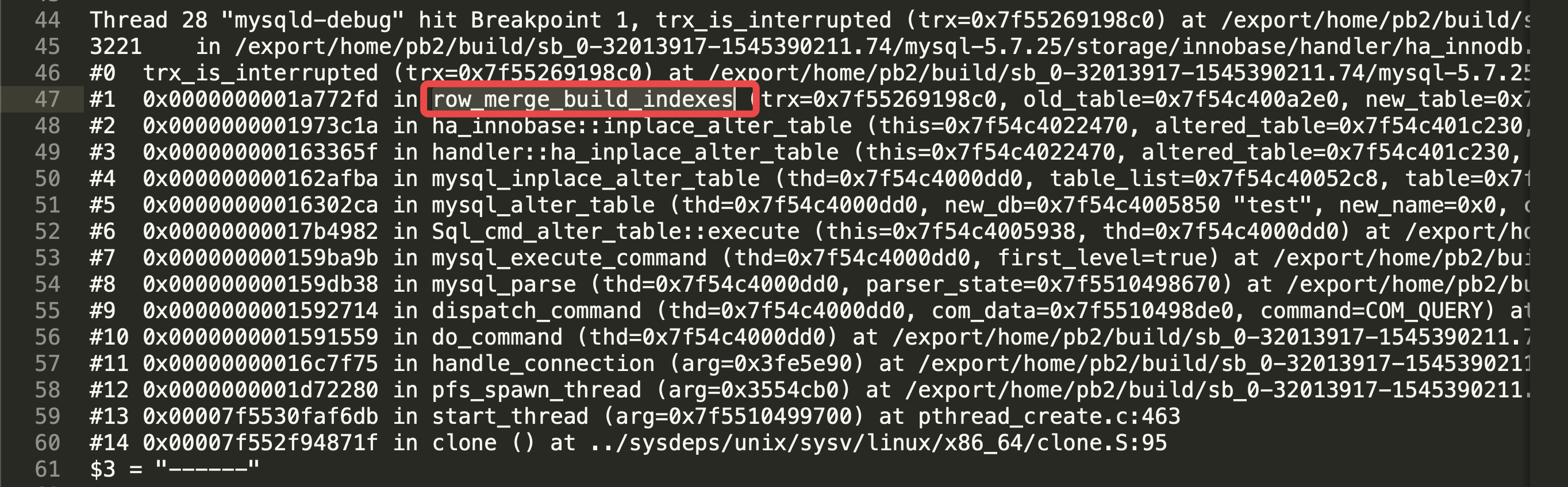
这个堆栈不太容易识别: 这是整个 DDL 的外层操作, 只知道是重建索引 (之前两个堆栈也都是重建索引里的步骤)
找到该行最后, 标记了其代码位置为: row0merge.cc:4668 , 查看一下代码:
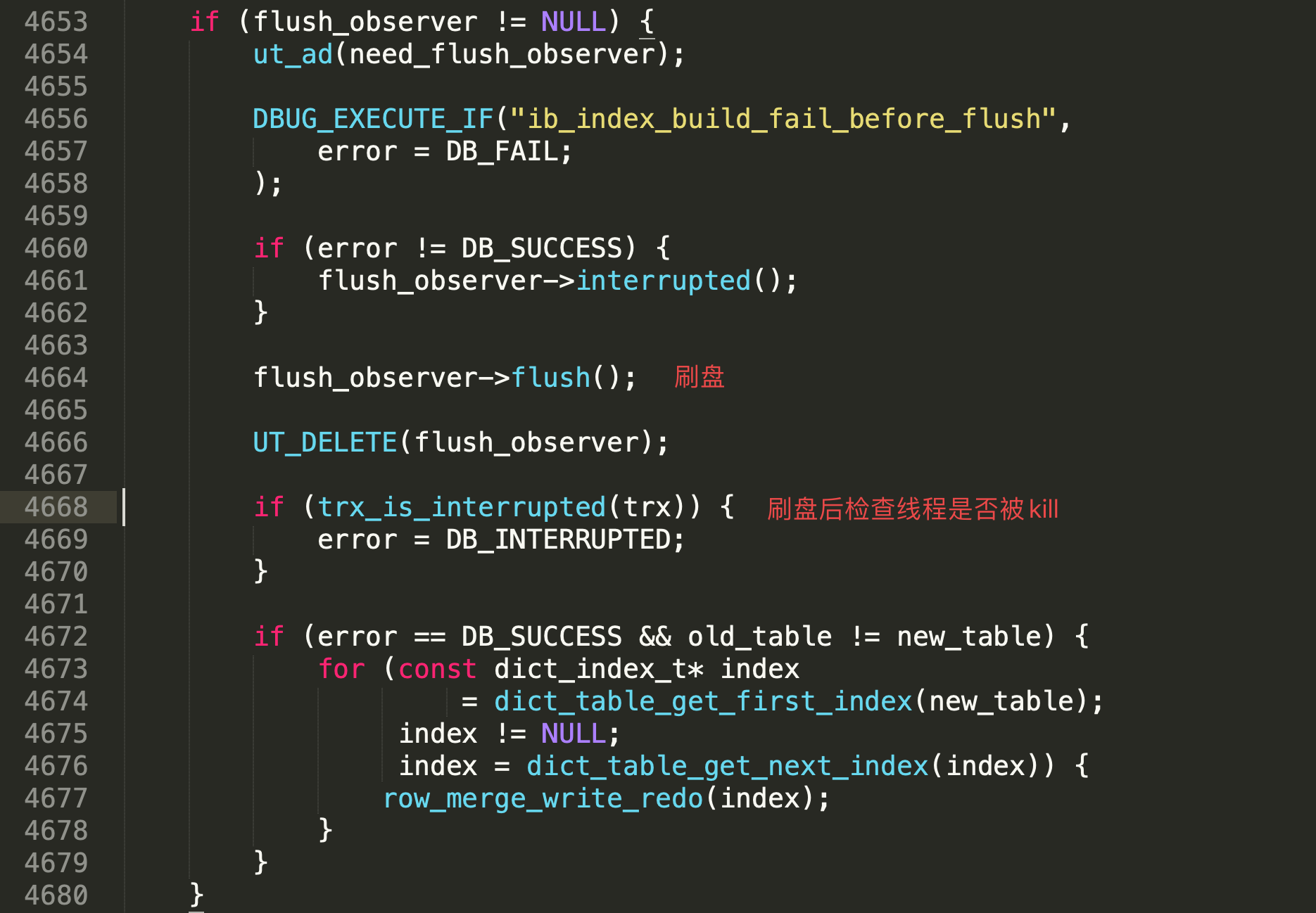
别怂, 我们只认识 flush 就行了, 此处是重建索引最后的刷盘操作, 刷盘后检查当前线程是否被 kill
第四个和第五个堆栈:
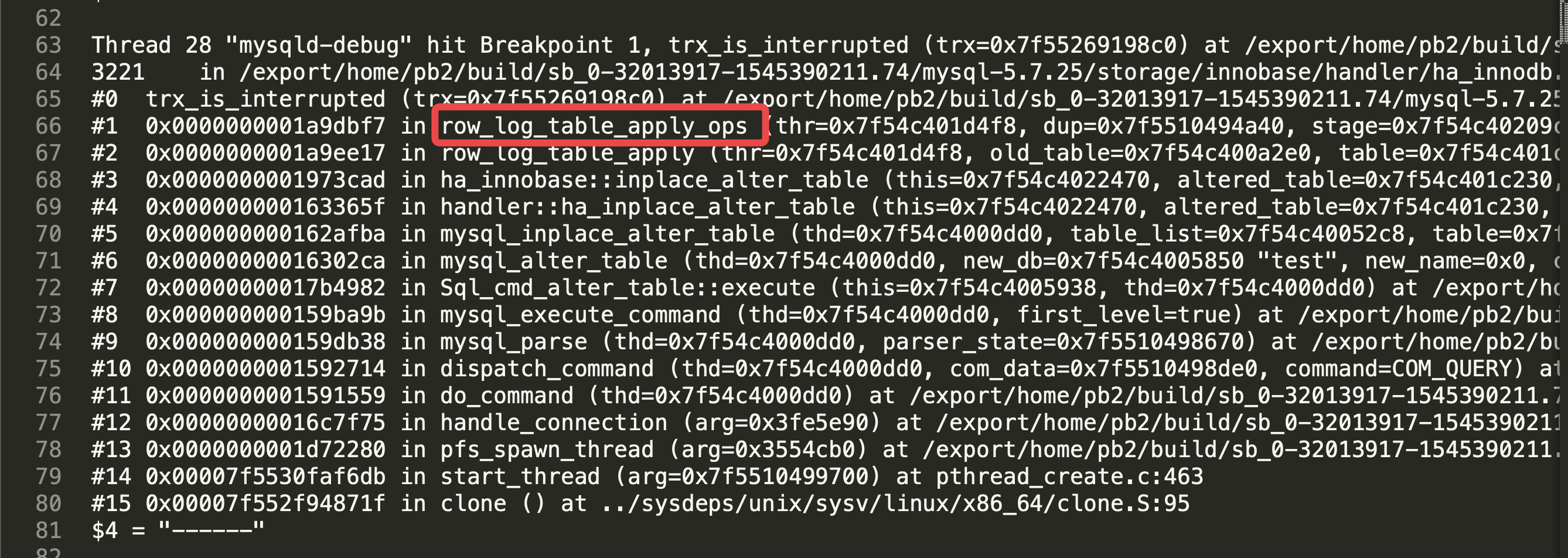
最后两个堆栈类似, 都是将online DDL log回放到新表中时, 进行检查
综合以上实验, 我们得出初步结论:
对于本实验中的 DDL , MySQL 在以下几处检查了当前线程是否被 kill:
-
从旧表中 读取聚簇索引的过程 -
向新表中 写入索引的过程 -
重建索引时, 刷盘后进行检查 -
将 online DDL log 回放到新表的过程 -
如果在这四个过程中, 发生了 kill , 那 DDL 操作很快就会开始回滚.
但这个结论仍然不能满足我们, 究竟是一个过程中哪个步骤才会检查 kill 呢?
翻一下官方文档, 对 kill 行为的描述如下:
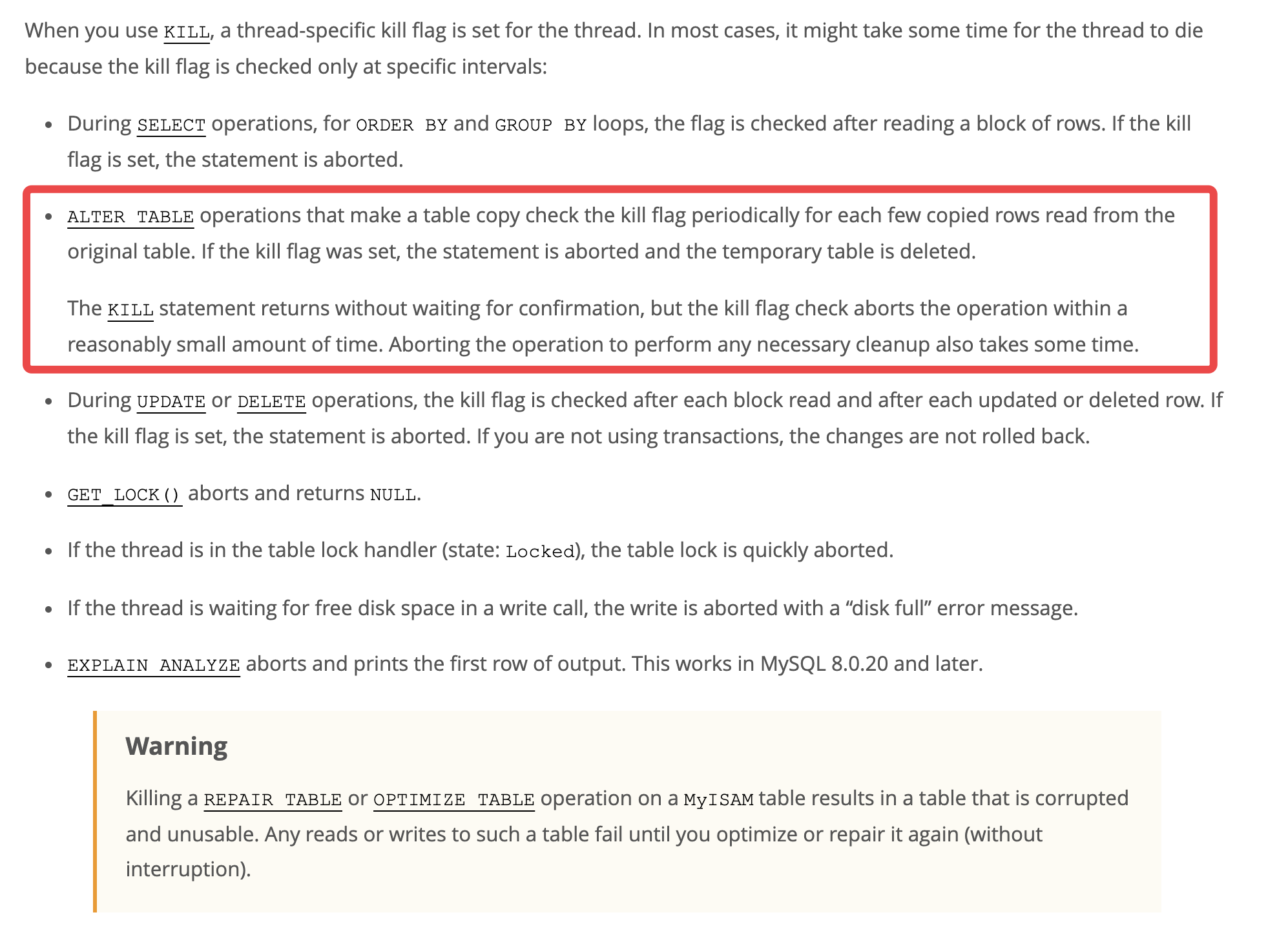
可以看到 对于大批数据操作, MySQL 会在一部分数据处理后检查线程是否被 kill
我们的实验结论中, 1/2/4三个过程都涉及了大量数据的操作, MySQL 将其分为若干部分, 在处理每一部分后进行检查也十分合理
需要注意的是: 对 DDL 进行 kill , 并不总能在合理的时间内触发: 比如对数据的处理变慢, 或者在堆栈3中 flush 变慢, 此时只能等到检查点才会进行检查
小贴士
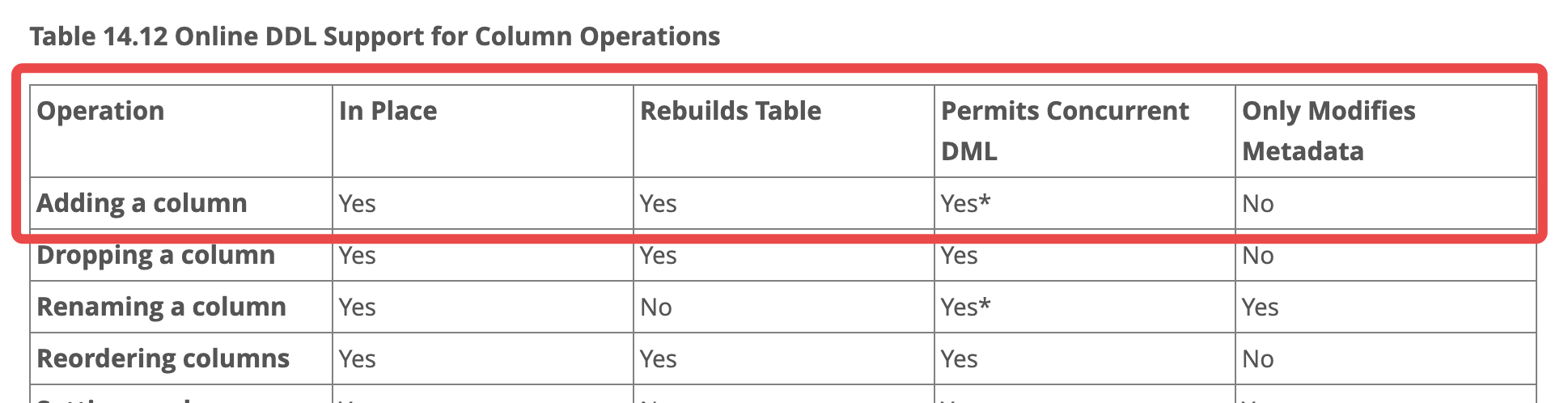
本实验中, 进行的 DDL 操作, 其操作类型如图:
对于其他类型的 DDL , 大家可通过实验自行探索.
关于 MySQL 的技术内容,你们还有什么想知道的吗?赶紧留言告诉小编吧!