作者:任坤
现居珠海,先后担任专职 Oracle 和 MySQL DBA,现在主要负责 MySQL、mongoDB 和 Redis 维护工作。
本文来源:原创投稿
*爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
1 背景
6月5号22:30左右收到几条报警短信,线上某 mongo 集群的 shard2 出现了主从延迟,过了几分钟自动恢复。 本来想假装没看见,可是过了一会又报警主从延迟,虽然这次也是自动恢复,但是不上去看一下心里有点不踏实。 这套环境为3.4集群,3 * mongos + 4 * shard(1主2从),主节点 priority=2 ,其余节点 priority=1 ,当网络畅通时确保主库永远在1节点。
2 排查
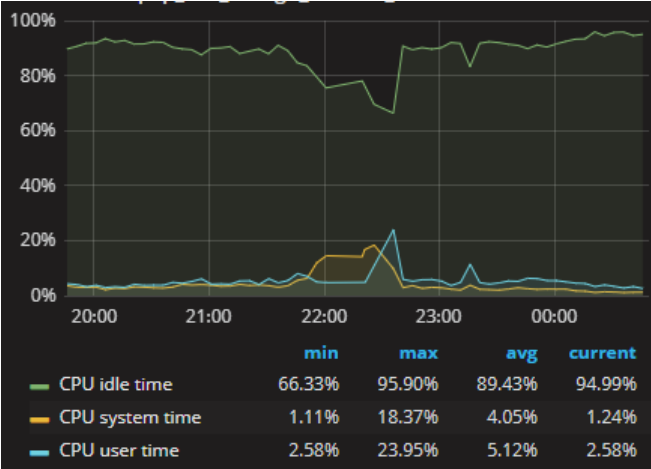
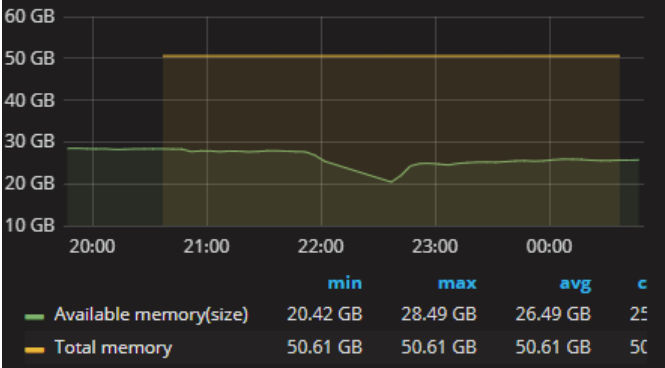
登录grafana查看主库的监控信息,这一时间段cpu和内存使用率明显上升
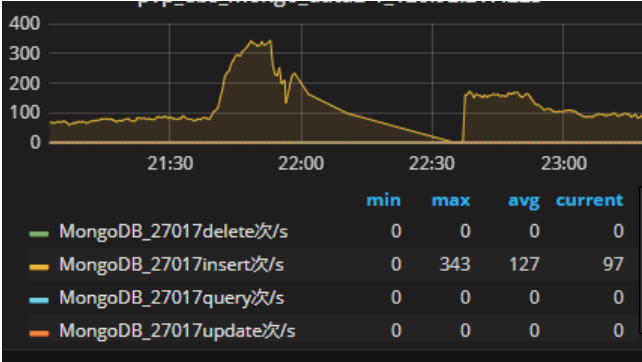
qps 在22:30附近线性下降为 0
连接数却持续暴涨
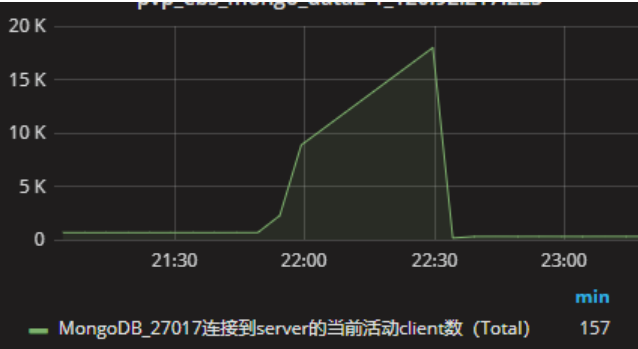
由此可以大致推断是连接风暴导致主库压力过大进而引发主从复制延迟,具体信息需要查看 mongod.log 。mongo 日志文件的好处是记录信息非常详细,坏处是记录信息太多导致文件占用空间很大。为此 mongo 提供了专门的切换日志指令,但该指令只负责切换不负责清理历史日志文件,并且 mongo 自身不能设置 job 以实现定期自动切换,为此需要单独编写脚本。
创建1个具有 hostManager 角色的 mongo 账号 backup ,编写如下一个 shell 脚本,每小时执行1次。
[root@ mongod]# more logrotate_mongo.sh
#!/bin/sh
MONGO_CMD=/usr/local/mongodb/bin/mongo
KEEP_DAY=7
#flush mongod log
datadir=/data/mongodb
port=27017
role=mongod
destdir=/data/backup/mongolog/${role}
if [ ! ‐d "${destdir}" ]; then
mkdir ‐p ${destdir}
fi
$MONGO_CMD ‐‐authenticationDatabase admin admin ‐ubackup ‐p"*****" ‐‐eval
"db.runCommand({logRotate:1})" ‐‐port $port
mv ${datadir}/mongod.log.????‐??‐??T??‐??‐?? ${destdir}/
find $destdir ‐name "mongod.log.*" ‐mtime +${KEEP_DAY} ‐exec rm ‐rf {} \;
归档的日志文件如下,22:00-23:00时间段生成的日志量比平时多出1个量级,由此也可以反向推断出 mongo 在这段时间压力有异常。
‐rw‐r‐‐r‐‐ 1 root root 11647760 Jun 5 18:00 mongod.log.2021‐06‐05T10‐00‐02
‐rw‐r‐‐r‐‐ 1 root root 12869316 Jun 5 19:00 mongod.log.2021‐06‐05T11‐00‐01
‐rw‐r‐‐r‐‐ 1 root root 15625361 Jun 5 20:00 mongod.log.2021‐06‐05T12‐00‐03
‐rw‐r‐‐r‐‐ 1 root root 10993819 Jun 5 21:00 mongod.log.2021‐06‐05T13‐00‐02
‐rw‐r‐‐r‐‐ 1 root root 71500070 Jun 5 22:00 mongod.log.2021‐06‐05T14‐00‐40
‐rw‐r‐‐r‐‐ 1 root root 215216326 Jun 5 23:00 mongod.log.2021‐06‐05T15‐00‐02
查询对应时间点的日志,出现大量创建工作线程失败的信息
2021‐06‐05T22:28:00.821+0800 I ‐ [thread2] failed to create service entry worker
thread for 172.31.0.65:39890
2021‐06‐05T22:28:00.821+0800 I NETWORK [thread2] connection accepted from
172.31.0.66:45090 #4051839 (32622 connections now open)
2021‐06‐05T22:28:00.821+0800 I ‐ [thread2] pthread_create failed: Resource
temporarily unavailable
2021‐06‐05T22:28:00.821+0800 I ‐ [thread2] failed to create service entry worker
thread for 172.31.0.66:45090
2021‐06‐05T22:28:00.821+0800 I NETWORK [thread2] connection accepted from
172.31.0.65:39892 #4051840 (32622 connections now open)
2021‐06‐05T22:28:00.821+0800 I ‐ [thread2] pthread_create failed: Resource
temporarily unavailable
同一时间段从库的日志:
2021‐06‐05T22:30:07.325+0800 I REPL [ReplicationExecutor] Error in heartbeat request
to 172.31.0.183:27017; ExceededTimeLimit: Couldn't get a connection within the time limit
2021‐06‐05T22:30:07.425+0800 I SHARDING [migrateThread] Waiting for replication to catch
up before entering critical section
主库几乎失去了响应能力,从库定时心跳发起的连接都无法创建,进而触发主从选举,当前从库临时被选为主库。 等老主库恢复响应并重新加入集群后,又重新夺回控制权。
采用mtools解析日志,输出结果也验证了这一点,正常情形下183为主库114为从库,
[root@vm172‐31‐0‐183 mongod]# mloginfo mongod.log.2021‐06‐05T15‐00‐02 ‐‐rsstate
.....
RSSTATE
date host state/message
Jun 05 22:28:05 172.31.0.114:27017 PRIMARY #114被选举为主库
Jun 05 22:36:41 172.31.0.114:27017 SECONDARY #114被降级为从库
[root@vm172‐31‐0‐114 mongod]# mloginfo mongod.log.2021‐06‐05T14‐48‐24 ‐‐rsstate......
RSSTATE
date host state/message
Jun 05 22:31:50 172.31.0.183:27017 ROLLBACK #183以从库身份加入集群,执行rollback和recover流程,
Jun 05 22:34:48 172.31.0.183:27017 RECOVERING
Jun 05 22:35:52 172.31.0.183:27017 SECONDARY #183的状态变为secondary后,因为priority更高因此触发了新一轮选举
Jun 05 22:36:43 172.31.0.183:27017 PRIMARY #183重新变成了主库
接下来的问题是确认是哪些应用服务器发起的连接风暴,shard节点的连接都是由mongos发起的,只能去查看mongos实例的日志。 还是采用mtools工具,输出如下: 这个是21:00-22:00时间段的连接创建信息
[root@ mongos]# mloginfo mongod.log.2021‐06‐05T14‐00‐01 ‐‐connections
......
CONNECTIONS
total opened: 8904
total closed: 5645
no unique IPs: 6
socket exceptions: 649
127.0.0.1 opened: 2683 closed: 2683
172.31.0.21 opened: 1531 closed: 733
172.31.0.28 opened: 1525 closed: 676
172.31.0.81 opened: 1520 closed: 704
172.31.0.78 opened: 1495 closed: 699
172.31.0.134 opened: 150 closed: 150
这个是22:00-23:00时间段的连接创建信息,很明显这个时间段有问题
[root@ mongos]# mloginfo mongod.log.2021‐06‐05T15‐00‐01 ‐‐connections
......
CONNECTIONS
total opened: 58261
total closed: 58868
no unique IPs: 7
socket exceptions: 3708
172.31.0.78 opened: 14041 closed: 14576
172.31.0.21 opened: 13898 closed: 14284
172.31.0.28 opened: 13835 closed: 13617
172.31.0.81 opened: 13633 closed: 13535
127.0.0.1 opened: 2681 closed: 2680
172.31.0.134 opened: 170 closed: 176
172.31.0.4 opened: 3 closed: 0
由此确认这次事件是由应用服务器连接异动造成,剩下的就是将这些信息交给开发人员进一步审核。
3 总结
这个案例总体比较好诊断,只是需要用到2个工具,1个是定期切换日志的shell脚本,1个是由 mongo 官方工程师编写的 mtools 。 它们可以帮助我们快速查看日志并从中提取出诊断所需的关键信息,极大的提升了工作效率。