
在讲全文索引之前,可以看看如下很常见的一类 SQL 语句:
select count(*) from fx where s1 like '%cluster%'
这条语句从表 fx 中检索字段 s1,过滤条件为 ‘%cluster%’,这样的模糊查找语句性能很差,即使在字段 s1 上有索引也因无法找到切入点从而对表 fx 进行全表扫描,特别是对于一张大表,这类 SQL 的性能无疑致命。
全文索引则很好地解决了这类低效 SQL 的性能问题。全文索引的理念和普通 B 树索引的理念刚好相反,B 树索引的构建是基于某个字段值的全部或者一部分;全文索引是把某个字段值的全部数据按照一定的分隔符(停止词)与字符长度(也叫分词长度)一起组成各种排列,进而在索引中记录这些字符出现的位置,次数等静态信息。我简单画了张图,如下:
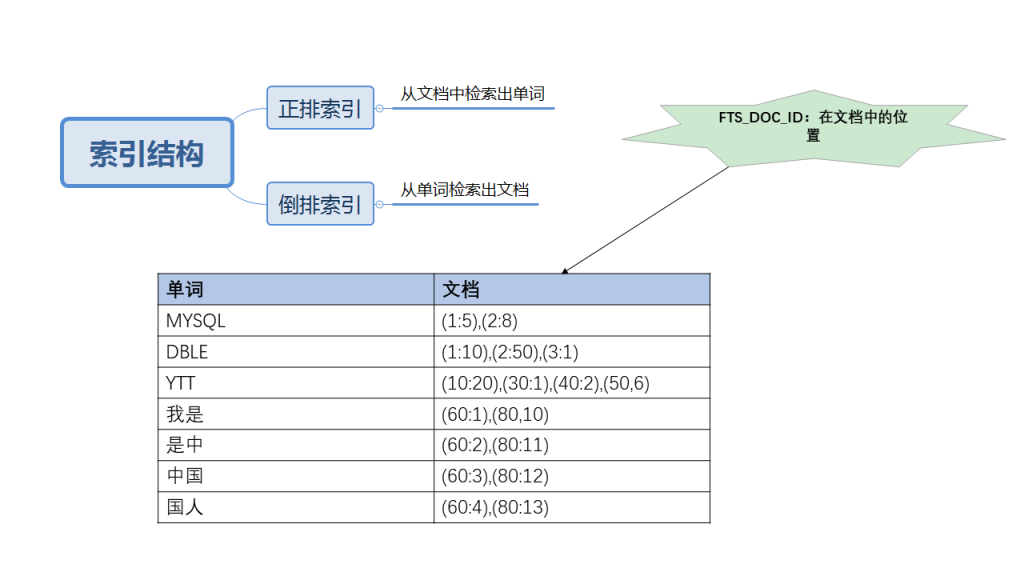
从这张图可以看到,全文索引(也叫倒排索引)有点类似于 HASH 索引的存储,只不过 KEY 为单词,VALUE 为关键词所属的文档 ID 与对应位置信息。比如 “YTT” 一词出现在 4 个文档里的某个位置,也就是 4 行记录里某个位置,FTS_DOC_ID 指的是文档的 ID,每条记录对应一个 ID,类似于表的主键。
接下来,从几个方面来详细阐述全文索引,本篇所示例子基于以下表:
CREATE TABLE ft_sample (
id INT PRIMARY KEY,
s1 VARCHAR(200),
log_time DATETIME,
s2 TEXT,
KEY idx_log_time (log_time)
);辅助表
先给表 ft_sample 添加全文索引
mysql> alter table ft_sample add fulltext ft_s1(s1);
Query OK, 0 rows affected (0.35 sec)
Records: 0 Duplicates: 0 Warnings: 0
对表建立全文索引后,MySQL 用一些辅助表来保存全文索引字段的相关数据指向。如果表 ft_sample 不属于共享表空间,那对应磁盘目录上也能看到这些表。如下:
mysql> SELECT table_id, name, space from INFORMATION_SCHEMA.INNODB_TABLES WHERE name LIKE 'ytt/fts%';
+----------+---------------------------------------------------+-------+
| table_id | name | space |
+----------+---------------------------------------------------+-------+
| 1219 | ytt/fts_00000000000004c2_being_deleted | 162 |
| 1220 | ytt/fts_00000000000004c2_being_deleted_cache | 163 |
| 1221 | ytt/fts_00000000000004c2_config | 164 |
| 1222 | ytt/fts_00000000000004c2_deleted | 165 |
| 1223 | ytt/fts_00000000000004c2_deleted_cache | 166 |
| 1230 | ytt/fts_00000000000004c2_00000000000001ba_index_1 | 173 |
| 1231 | ytt/fts_00000000000004c2_00000000000001ba_index_2 | 174 |
| 1232 | ytt/fts_00000000000004c2_00000000000001ba_index_3 | 175 |
| 1233 | ytt/fts_00000000000004c2_00000000000001ba_index_4 | 176 |
| 1234 | ytt/fts_00000000000004c2_00000000000001ba_index_5 | 177 |
| 1235 | ytt/fts_00000000000004c2_00000000000001ba_index_6 | 178 |
+----------+---------------------------------------------------+-------+
11 rows in set (0.00 sec)
下面来详细介绍下这些表:
以 _index_1-6 为后缀的被称为辅助表,里面顺序存放倒排索引的真实数据。至于分了六张表的原因,可以理解为对字段添加全文索引并且对数据分词的并行化。参考参数 innodb_ft_sort_pll_degree,可以控制并发数量。
例如表名为:ytt/fts_00000000000004c2_00000000000001ba_index_1,其中 ytt 代表数据库名,fts_ 开头和 _index_1 结尾表示辅助表,00000000000004c2 代表对应的表 ID 的十六进制值,00000000000001ba 代表加 fulltext 索引字段 ID 对应的十六进制值。
查看表 ft_sample 对应的 ID,
mysql> SELECT
a.table_id,
HEX(a.table_id),
a.index_id,
HEX(a.index_id),
a.name
FROM
information_schema.innodb_indexes a,
information_schema.innodb_tables b
WHERE
a.table_id = b.table_id
AND b.name = 'ytt/ft_sample'
AND a.name = 'ft_s1';
+----------+-----------------+----------+-----------------+-------+
| table_id | hex(a.table_id) | index_id | hex(a.index_id) | name |
+----------+-----------------+----------+-----------------+-------+
| 1218 | 4C2 | 442 | 1BA | ft_s1 |
+----------+-----------------+----------+-----------------+-------+
1 row in set (0.00 sec)
剩下的不包含全文索引字段 ID 的表为通用辅助表,记录索引表的配置信息、以及有关索引删除的信息。
ytt/fts_00000000000004c2_deleted
ytt/fts_00000000000004c2_deleted_cache
这两表内容一样,都包含了标记为删除,但是实际上还没有从之前的六张索引表里删除的文档 ID(DOC_ID) 列表;不同的是 ytt/fts_00000000000004c2_deleted_cache 是 ytt/fts_00000000000004c2_deleted 在内存中的一个拷贝。
ytt/fts_00000000000004c2_being_deleted
ytt/fts_00000000000004c2_being_deleted_cache
这两表的内容也一样,也都包含了标记为删除,并且正在从之前的六张索引表里删除对应的 DOC_ID。同样表 tt/fts_00000000000004c2_being_deleted_cache 是表 ytt/fts_00000000000004c2_being_deleted 的内存拷贝。
上面这四张表存在的意义在于可以避免在全文索引字段频繁的写入操作导致对应的六张磁盘索引表成为热点。由此带来的问题是删除的记录被保存多份,没有及时的删除,占用额外的磁盘空间。不过可以用 MySQL 语句 “optimize table” 来手动提前释放这些空间,optimize table 语句默认只对 B+ 树聚簇索引进行整理,不会对全文索引做整理。这里MySQL 提供了一个参数 innodb_optimize_fulltext_only,默认关闭,打开这个参数后,语句 optimize table 只会对全文索引整理磁盘空间。
ytt/fts_00000000000004c2_config
这张表包含了全文索引的内部状态信息,字段 FTS_SYNCED_DOC_ID 不同于 FTS_DOC_ID,表示已经被解析完并且刷盘的索引记录。
全文索引缓冲池
全文索引有一个缓冲池:information_schema.innodb_ft_index_cache。用来缓存全文索引字段的写入操作(insert/update),标记分词以及其他相关信息,和 MySQL 其他的缓存一样,目的是把多次频繁刷盘变为按照定义的缓冲池大小写满后合并一次性刷盘(刷新到之前的六张辅助表)。刷盘后表 information_schema.innodb_ft_index_cache 被清空,下次根据全文索引字段来过滤时,直接查询对应的磁盘索引表;如果此时对全文索引字段值有更新但是还没有触发刷盘,MySQL 会把缓冲池的数据和磁盘索引表的数据一起返回给客户端。
其中控制单表缓冲池大小的变量为:innodb_ft_cache_size,默认8MB,最小 1.6MB,最大 80MB。
控制整个 MySQL 实例缓冲池大小的变量为:innodb_ft_total_cache_size,默认 640M,最小 32MB,最大 1.6GB。
文档 ID,DOC_ID
DOC_ID 是关键词映射的索引表记录 ID,每条记录被当作一个文档, 映射为 MySQL 全文索引表的一个字段 FTS_DOC_ID。如果全文索引表没有显式指定这个字段,MySQL 默认建立一个隐藏字段。为了避免后期加列的开销,这个字段不会随着全文索引的销毁而删除。也就是说这个字段会一直存在,除非这张表被删掉。
本篇开始的示例表 ft_sample ,用 show extended columns 语句查看隐藏字段:
mysql> show extended columns from fx;
+-------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+---------+----------------+
| id | int | NO | PRI | NULL | auto_increment |
| s1 | varchar(200) | YES | MUL | NULL | |
| log_time | datetime | YES | MUL | NULL | |
| s2 | varchar(200) | YES | | NULL | |
| s3 | text | YES | | NULL | |
| FTS_DOC_ID | | NO | | NULL | |
| DB_TRX_ID | | NO | | NULL | |
| DB_ROLL_PTR | | NO | | NULL | |
+-------------+--------------+------+-----+---------+----------------+
8 rows in set (0.01 sec)
如果想显式自定义这个字段,并且手动维护值的唯一性,在建表的时候,或者是在全文索引没有建立之前,可以指定一个名字为 FTS_DOC_ID 字段,类型为无符号 INT64(注意,这个字段必须为大写)。比如:
mysql> alter table ft_sample add FTS_DOC_ID bigint unsigned not null, add unique key idx_FTS_DOC_ID (FTS_DOC_ID);
Query OK, 0 rows affected (0.13 sec)
Records: 0 Duplicates: 0 Warnings: 0全文索引事务处理
全文索引的事务处理这块有点特殊,和 INNODB 的事务处理这块有点不一样。比如对全文索引表的 INSERT/UPDATE 操作,必须等待全部 COMMIT 后,才能检索刚才更新的数据,就算在一个事务里也看不到刚才更新但是还没有 COMMIT 的数据。举个例子:
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into ft_sample values (1,'mysql oracle postgresql','2020-01-16 09:32:58','');
Query OK, 1 row affected (0.00 sec)
mysql> insert into ft_sample values (2,'mysql oracle postgresql','2020-04-20 09:32:58','');
Query OK, 1 row affected (0.00 sec)
mysql> insert into ft_sample values (3,'mysql oracle postgresql','2020-09-30 09:32:58','');
Query OK, 1 row affected (0.01 sec)
mysql> insert into ft_sample values (4,'xfs ntfs','2020-10-30 09:32:58','');
Query OK, 1 row affected (0.00 sec)
mysql> select * from ft_sample where match (s1) against ('mysql');
Empty set (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.02 sec)
mysql> select * from ft_sample where match (s1) against ('mysql');
+----+-------------------------+---------------------+------+
| id | s1 | log_time | s2 |
+----+-------------------------+---------------------+------+
| 1 | mysql oracle postgresql | 2020-01-16 09:32:58 | |
| 2 | mysql oracle postgresql | 2020-04-20 09:32:58 | |
| 3 | mysql oracle postgresql | 2020-09-30 09:32:58 | |
+----+-------------------------+---------------------+------+
3 rows in set (0.00 sec)
从上面例子可以看到,在 commit 之前,查询关键词 ‘mysql’ 的记录不存在,commit 后,就可以正常查询。
通过本篇介绍,我把全文索引的结构以及在 MySQL 中的表现形式做一个大概的介绍,下一篇接着讲如何更好的使用全文索引。