3. import_table 特定功能
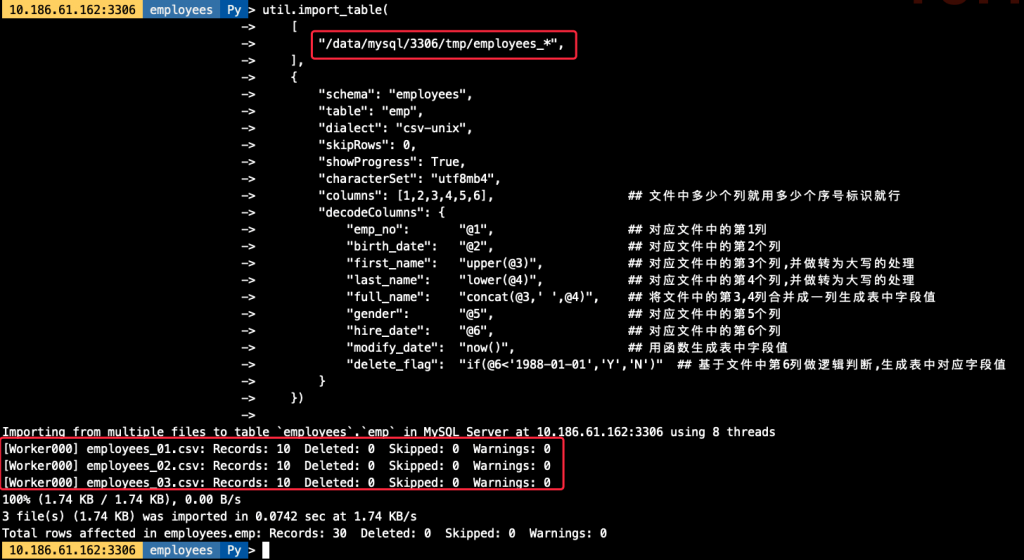
3.1 多文件导入(模糊匹配)
## 在导入前我生成好了3份单独的employees文件,导出的结构一致
[root@10-186-61-162 tmp]# ls -lh
总用量 1.9G
-rw-r----- 1 mysql mysql 579 3月 24 19:07 employees_01.csv
-rw-r----- 1 mysql mysql 584 3月 24 18:48 employees_02.csv
-rw-r----- 1 mysql mysql 576 3月 24 18:48 employees_03.csv
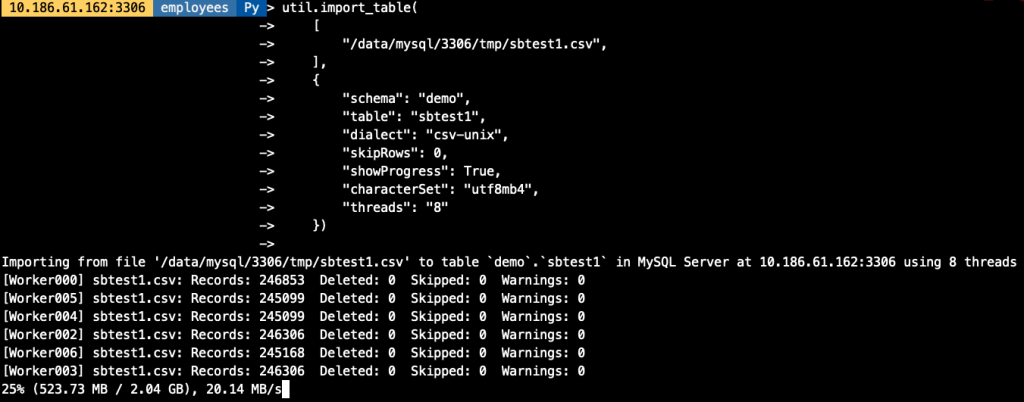
-rw-r----- 1 mysql mysql 1.9G 3月 26 17:15 sbtest1.csv
## 导入命令,其中针对文件用employees_*做模糊匹配
util.import_table(
[
"/data/mysql/3306/tmp/employees_*",
],
{
"schema": "employees",
"table": "emp",
"dialect": "csv-unix",
"skipRows": 0,
"showProgress": True,
"characterSet": "utf8mb4",
"columns": [1,2,3,4,5,6], ## 文件中多少个列就用多少个序号标识就行
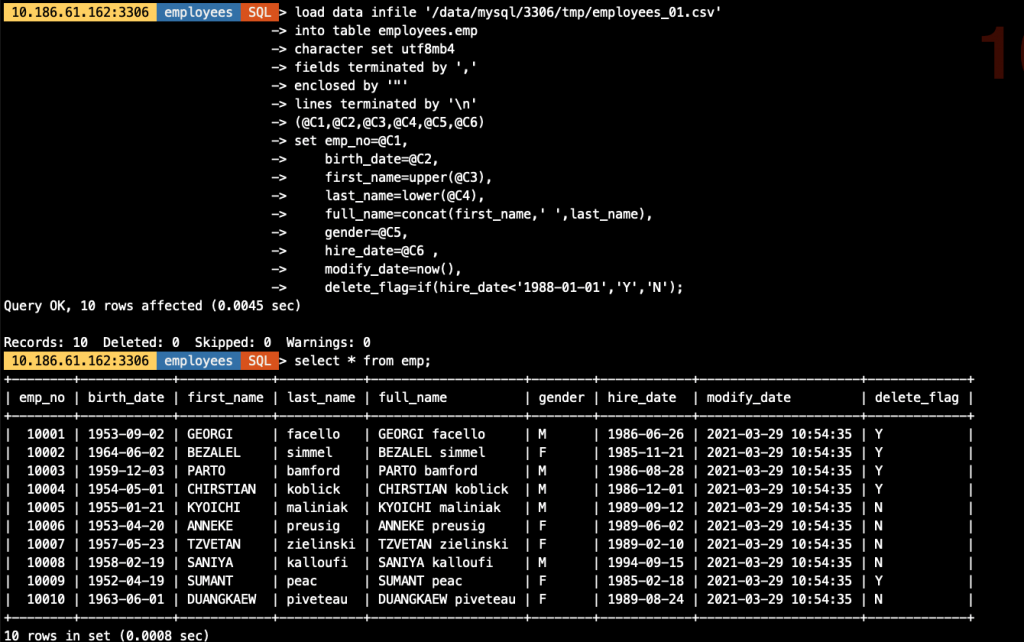
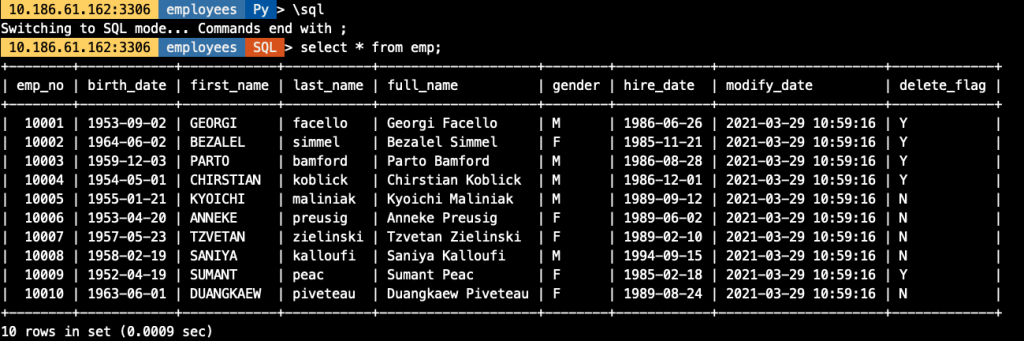
"decodeColumns": {
"emp_no": "@1", ## 对应文件中的第1列
"birth_date": "@2", ## 对应文件中的第2个列
"first_name": "upper(@3)", ## 对应文件中的第3个列,并做转为大写的处理
"last_name": "lower(@4)", ## 对应文件中的第4个列,并做转为大写的处理
"full_name": "concat(@3,' ',@4)", ## 将文件中的第3,4列合并成一列生成表中字段值
"gender": "@5", ## 对应文件中的第5个列
"hire_date": "@6", ## 对应文件中的第6个列
"modify_date": "now()", ## 用函数生成表中字段值
"delete_flag": "if(@6<'1988-01-01','Y','N')" ## 基于文件中第6列做逻辑判断,生成表中对应字段值
}
})
## 导入命令,其中对要导入的文件均明确指定其路径
util.import_table(
[
"/data/mysql/3306/tmp/employees_01.csv",
"/data/mysql/3306/tmp/employees_02.csv",
"/data/mysql/3306/tmp/employees_03.csv"
],
{
"schema": "employees",
"table": "emp",
"dialect": "csv-unix",
"skipRows": 0,
"showProgress": True,
"characterSet": "utf8mb4",
"columns": [1,2,3,4,5,6], ## 文件中多少个列就用多少个序号标识就行
"decodeColumns": {
"emp_no": "@1", ## 对应文件中的第1列
"birth_date": "@2", ## 对应文件中的第2个列
"first_name": "upper(@3)", ## 对应文件中的第3个列,并做转为大写的处理
"last_name": "lower(@4)", ## 对应文件中的第4个列,并做转为大写的处理
"full_name": "concat(@3,' ',@4)", ## 将文件中的第3,4列合并成一列生成表中字段值
"gender": "@5", ## 对应文件中的第5个列
"hire_date": "@6", ## 对应文件中的第6个列
"modify_date": "now()", ## 用函数生成表中字段值
"delete_flag": "if(@6<'1988-01-01','Y','N')" ## 基于文件中第6列做逻辑判断,生成表中对应字段值
}
})