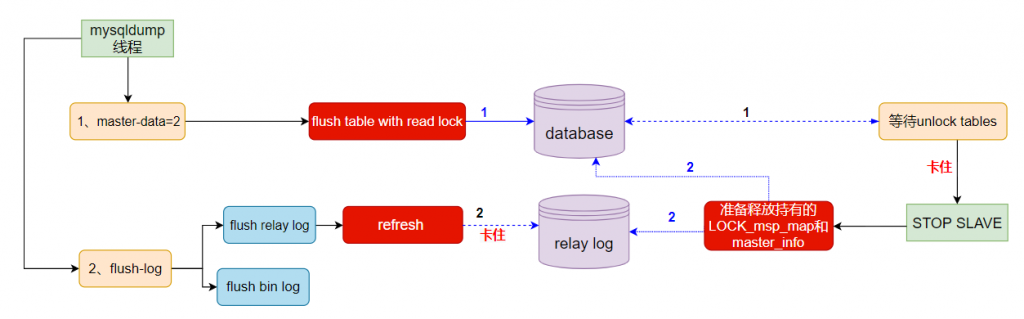
(图片建议点开放大看)
[root@localhost ~]# gdb -ex "set pagination 0" -ex "thread apply all bt" --batch -p 13192 # 打印对应MySQL进程堆栈——找到stop slave卡住的线程后处理输出
······
Thread 23 (Thread 0x7f98f027e700 (LWP 19446)):
#0 pthread_cond_timedwait@@GLIBC_2.3.2 ()
#1 native_cond_timedwait
#2 my_cond_timedwait
#3 inline_mysql_cond_timedwait
#4 terminate_slave_thread (thd=0x7f98740008c0, term_lock=0x7f9884022908, term_cond=0x7f9884022a08, slave_running=0x7f9884022ac4, stop_wait_timeout=0x7f98f027c448, need_lock_term=false) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/sql/rpl_slave.cc:1861
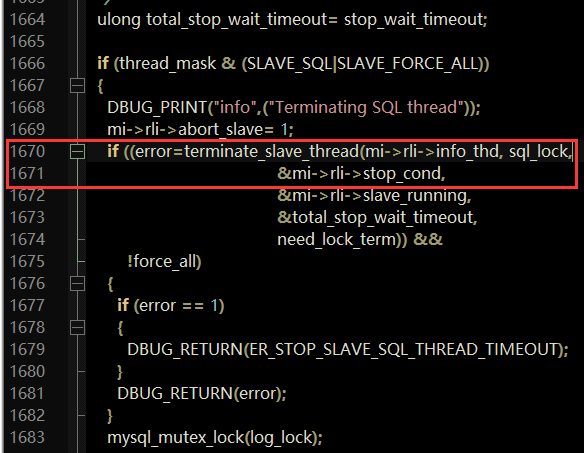
#5 terminate_slave_threads (mi=0x7f988401c500, thread_mask=3, stop_wait_timeout=<optimized out>, need_lock_term=false) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/sql/rpl_slave.cc:1671
#6 stop_slave (thd=0x7f987c00f650, mi=0x7f988401c500, net_report=true, for_one_channel=false, push_temp_tables_warning=0x7f98f027c52f) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/sql/rpl_slave.cc:10261
#7 stop_slave (thd=0x7f987c00f650) at /export/home/pb2/build/sb_0-33648028-1555164244.06/mysql-5.7.26/sql/rpl_slave.cc:615
#8 stop_slave_cmd
#9 mysql_execute_command
#10 mysql_parse
#11 dispatch_command
#12 do_command
#13 handle_connection
#14 pfs_spawn_thread
#15 start_thread ()
#16n clone ()
# 可以看到# 5 stop_wait_timeout,获取更多相关信息
(gdb) thread 34
[Switching to thread 34 (Thread 0x7f58d661f700 (LWP 13240))]
#0 0x00007f592d8e0d42 in pthread_cond_timedwait@@GLIBC_2.3.2 () from /lib64/libpthread.so.0
(gdb) f 5
#5 0x0000000000f0ed57 in terminate_slave_threads (mi=0x7f587801f050, thread_mask=3, stop_wait_timeout=<optimized out>, need_lock_term=false)
at /export/home/pb2/build/sb_0-32013917-1545390211.74/mysql-5.7.26/sql/rpl_slave.cc:1671
warning: Source file is more recent than executable.
1671 if ((error=terminate_slave_thread(mi->rli->info_thd, sql_lock,
(gdb) print mi->rli->info_thd
$1 = (THD *) 0x7f58700008c0
Thread 21 (Thread 0x7f58c05a6700 (LWP 14238)):
#9 apply_event_and_update_pos (ptr_ev=0x7f58c05a56c8, thd=0x7f58700008c0, rli=0x7f5878024b30)
#10 exec_relay_log_event (thd=0x7f58700008c0, rli=0x7f5878024b30)
# 通过gdb输出看到stop slave持有mi->rli->info_thd,在等待当前会话地址为0x7f58700008c0,定位到线程21的apply_event_and_update_pos 和exec_relay_log_event函数执行
apply_event_and_update_pos:应用给定事件并提高relay log的位置。
exec_relay_log_event:这是从SQL线程调用于执行relay log中下一个事件的顶级功能。
mi=master info, rli=relay log info