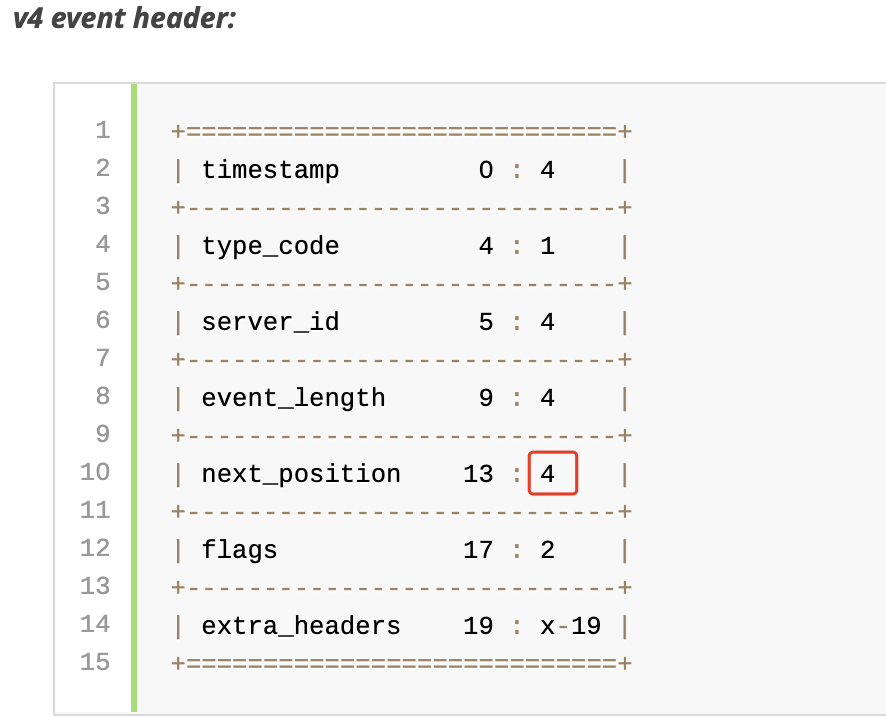
因为文章比较长,我们对逻辑进行一下复盘:
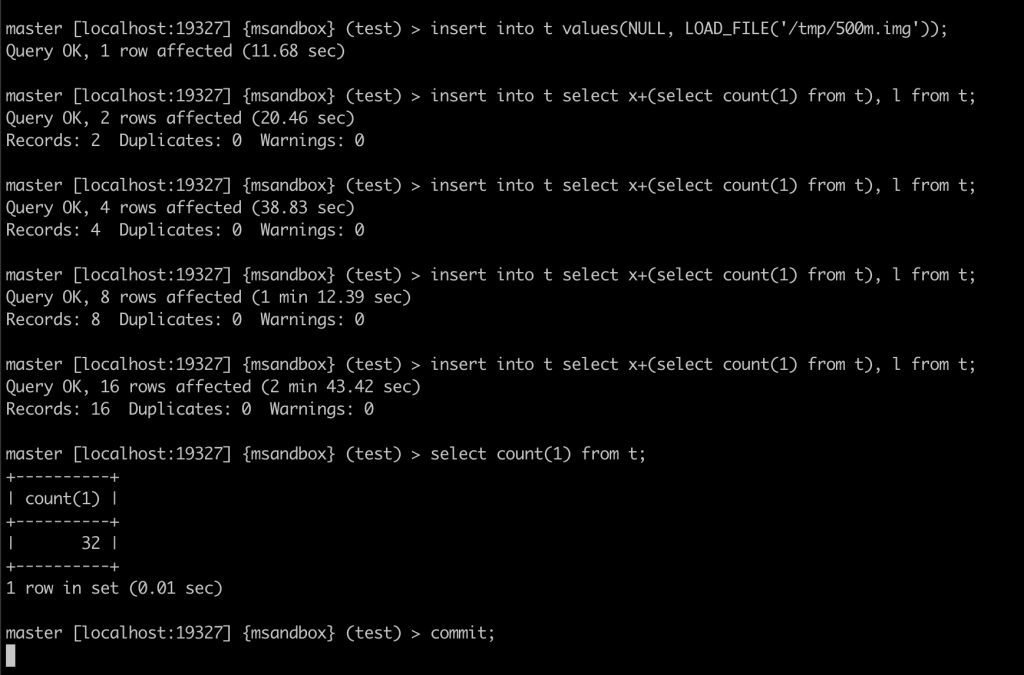
1. 我们通过抓包分析,知道 binlog 传输的网络包里,next_position 只有 4 个字节,最大数值为 4G。
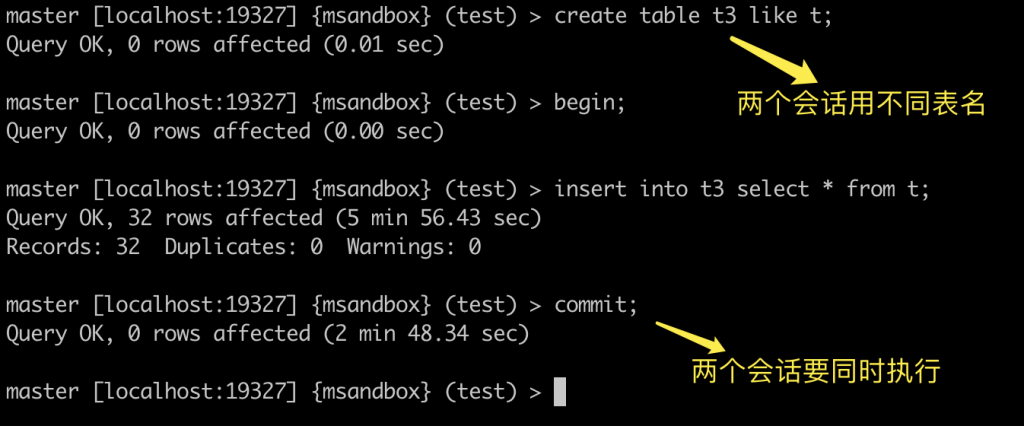
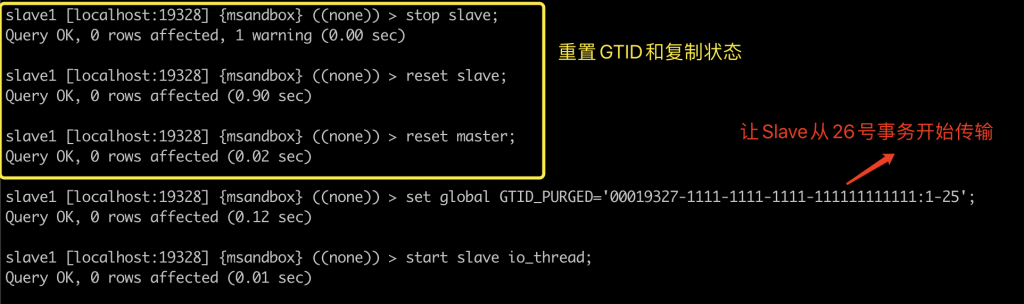
2. 我们在 master 上做了一个超过 4G 的大事务,让 slave 从这个大事务后开始传输。此时 master 会发送一个心跳包。
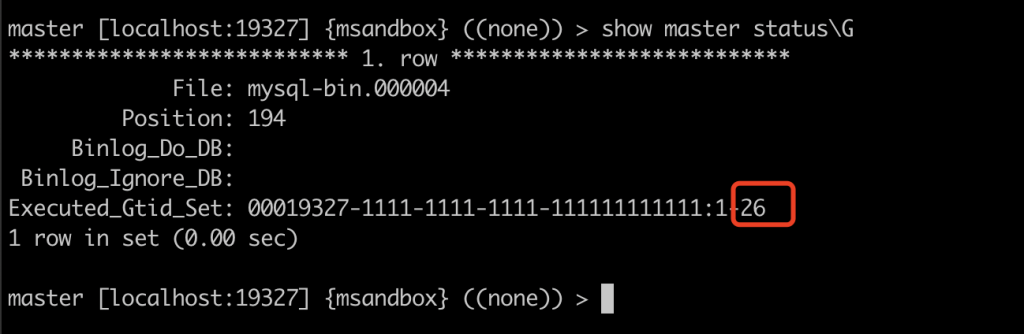
3. 心跳包中的 next_position 是 log event 在 binlog 位置,由于这个位置大于 4G,会被截断,导致 next_position 比实际的小。
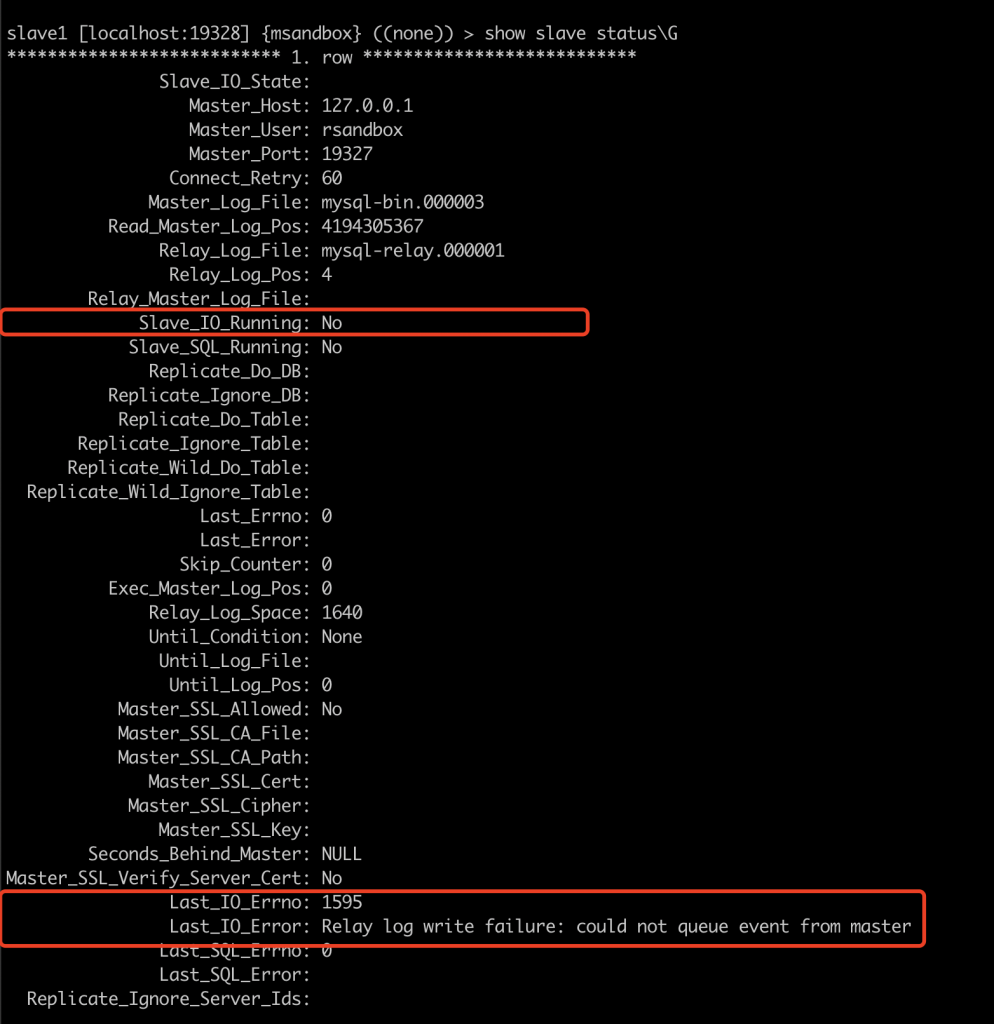
slave 收到心跳包,进行检测时发现 next_position 比实际的小,进行报错。
以上只是一种容易复现问题的场景。实际使用中,master 在一段时间不发送数据包后,或者特殊触发条件,都会发送心跳包。
对于一主多从的环境,每条复制链路的心跳是单独发送的,也就会导致多个 slave 的表现会有所不同,有的 slave 会触发报错,有的 slave 由于 master 没发送心跳包而不会触发报错。
最后送上几个小贴士:
1)我们如何快速找到有问题的包?
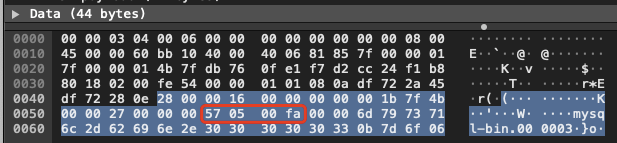
报错信息里已经标志了出错的 log position 是 423626115,转换成 16 进制为:0x19400583,找到由此数据的包即可。
2)一位一位读包太麻烦了,怎么办?
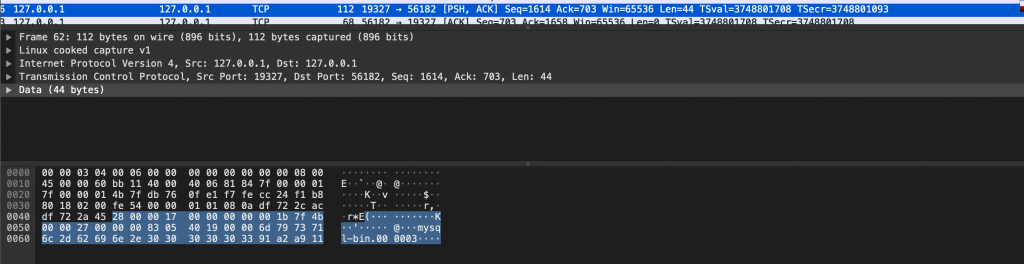
好办,先找到 server_id 的十六进制形式,以此为基准往后推定位数就可以。
比如我们的 server_id 是 19327,很容易找到基准位置。
3)报错里有一段乱码是啥?
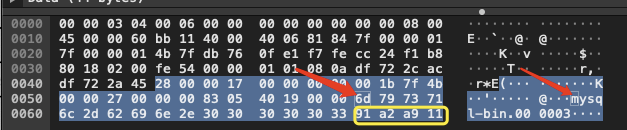
最后这四位,是 MySQL 程序有缺陷,将包中的 checksum 作为文件名输出了,对程序逻辑没有影响。
0x11 是 17,对应 ASCII 码 “device control 1 character”,键盘表达形式是 “ctrl + Q”,打印形式就是 “^Q”。
本文相关的 MySQL 的 bug 列表:
https://bugs.mysql.com/bug.php?id=101948
https://bugs.mysql.com/bug.php?id=101955