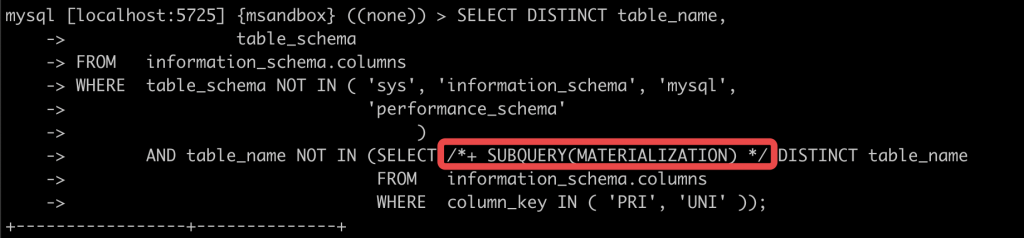
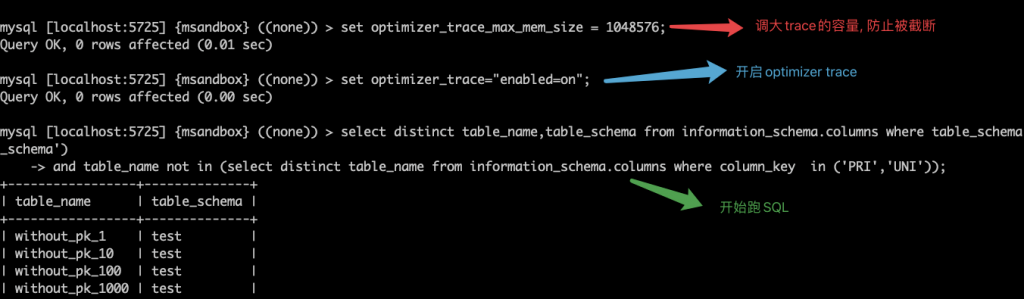
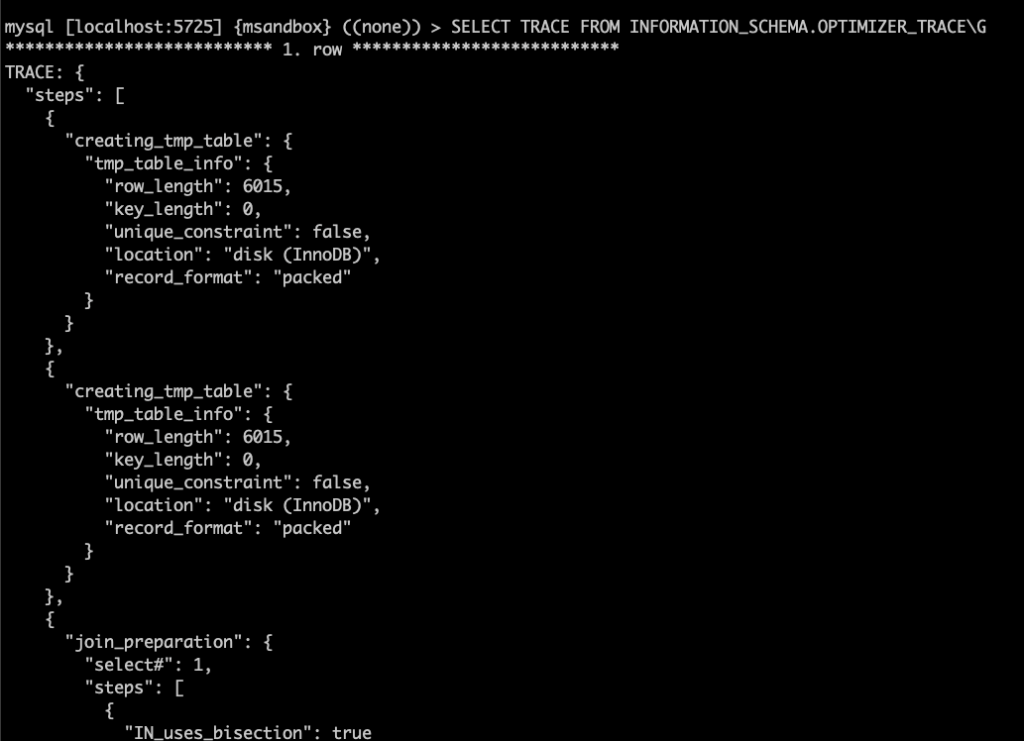
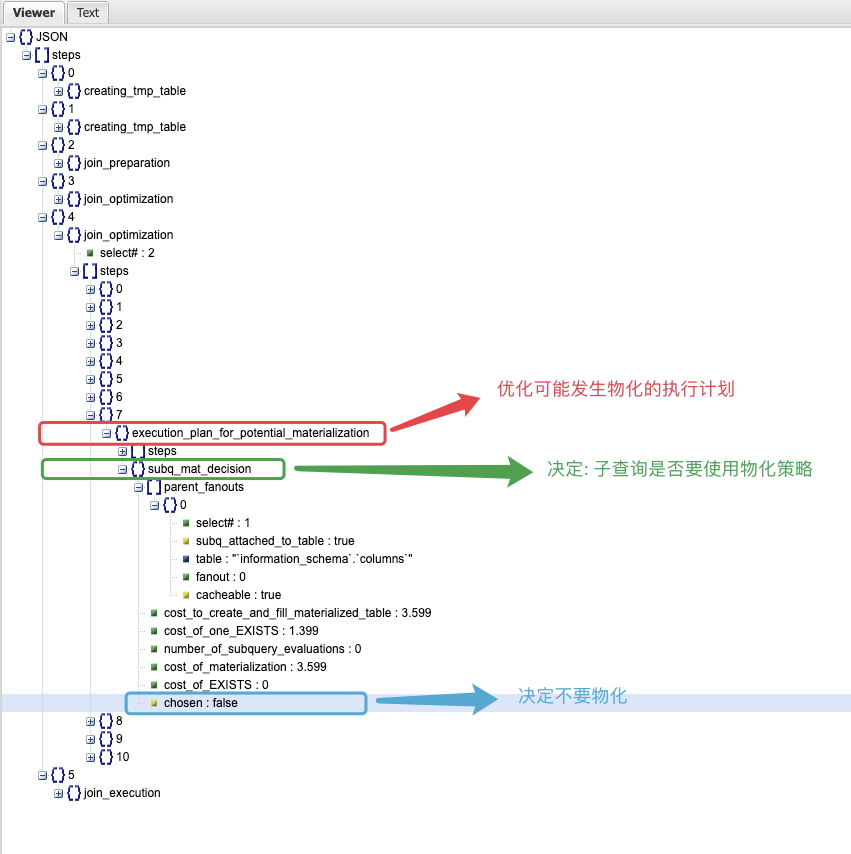
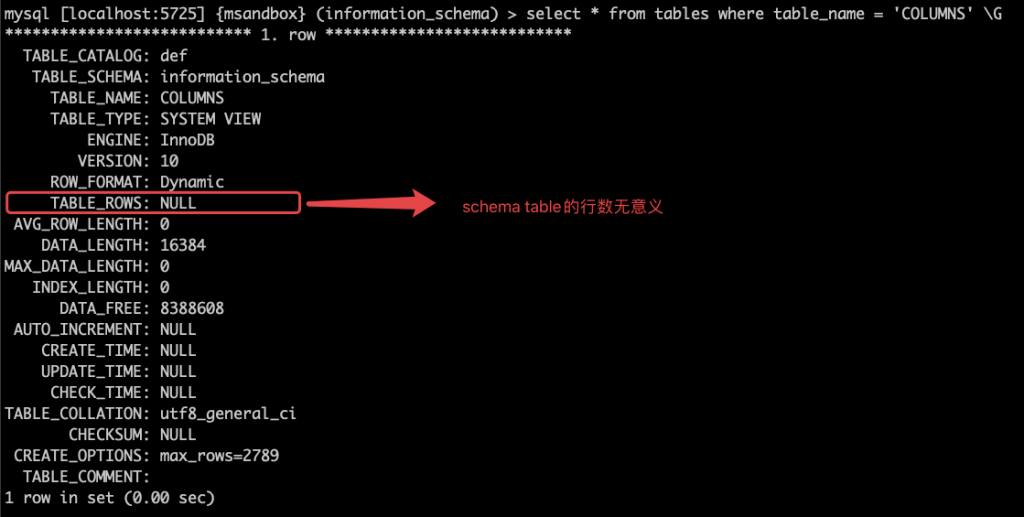
问题 在 26 问 中,我们看到了如下 SQL 在 MySQL 5.7 中跑得很慢: 我们还分析了执行计划改写后的 SQL,通过猜测,增加了 hint 来解决问题: 实验 我们接着使用 26 问中的环境,使用 optimizer trace 工具,观察 MySQL 对 SQL 的优化处理过程。 我们先调大 optimizer trace 的内存容量(否则 trace 的输出会被截断),然后开启了optimizer trace 功能。 跑完 SQL 后,可以在 INFORMATION_SCHEMA.OPTIMIZER_TRACE 看到 SQL 的优化处理过程: 这会是个巨大的 json,我们将其复制出来,找个 json 的可视化编辑器来分析一下。 小贴士如果 MySQL 启动时有配置 –secure-file-priv,那可以用,SELECT TRACE INTO DUMPFILE <filename> FROM INFORMATION_SCHEMA.OPTIMIZER_TRACE;将 trace 导出到文件里,会更方便一些。 这里我们选择了一个在线的 json 编辑器,使用起来会方便一点: 可以看到整个优化过程分为 6 个步骤,前两步都跟创建临时表相关,然后是 join 的准备工作,再是两步 join 优化,最后是 join 的执行。 回忆一下 26 问中,我们的子查询应使用物化方式,但实际使用了 exists 子句方式,我们猜测这个选择是在 join 的优化阶段做出的。 仔细翻一翻,就会找到可疑的部分: 上图中的中文,是从英文翻译过来的。看上去我们找对了位置。 接下来我们逐步看看这个决策的依据是什么: 显然不物化的代价更小,那么优化器选择不物化是正确的选择。 但使用 exists 子句进行子查询的代价,显然不可能为 0,MySQL 对这个代价的计算可能有误。 我们得来看看 MySQL 是如何计算这个代价的: 执行 exists 子查询的代价 = 执行一次子查询的代价 * 子查询需要执行的次数 显然这个子查询不可能只需要执行 0 次 这里需要做一个额外的思考:在这个场景下,子查询需要执行的次数,与父查询的行数相同。 也就是红框内需要执行的次数,取决于红框外的 SQL 的结果集条数。 这里 MySQL 将父表的结果集条数 称为 “扇出度”(fanout) 显然,这里父表 information_schema.columns 的扇出度为 0,直接导致了优化器放弃了物化的策略 那 information_schema.columns 的扇出度为什么是 0 呢? 查看 information_schema.tables 中对于 COLUMNS 表的描述,我们看到 MySQL 将 information_schema 中的元数据表做了特殊对待,其行数估计是没有意义的。 到此我们找到了问题所在:MySQL 5.7 对元数据表使用了区别设计,与普通表的行数估算方式不同。 以后大家在 MySQL 5.7 中使用 information_schema 中的元数据表做复杂查询时,需要额外注意执行计划,可能需要使用 hint 指导优化器工作。 小贴士MySQL 8.0 中进行了数据字典的改造,information_schema 中的元数据表大部分都变成了视图,其真实的数据源是 mysql 库中的隐藏元数据表。对 MySQL 8.0 的元数据表进行复杂查询,执行计划会比 MySQL 5.7 更加合理。 相关推荐: 第26问:information_schema.columns 表上做查询慢,怎么办? 第25问:MySQL 崩溃了,打印了一些堆栈信息,怎么读? 第24问:一主多从的半同步复制,到底是哪个 slave 拖慢了性能? 关于 MySQL 的技术内容,你们还有什么想知道的吗?赶紧留言告诉小编吧! 分类: 一问一实验(ChatDBA) 标签:hintinformation_schema优化器