在优化业务 sql 的过程中,经常发现开发将 order by 的字段添加到组合索引里面,但是依然有 file sort 产生,导致慢查。这是为什么呢?
索引本身是有序的,之所以产生 file sort 说明组合索引中存在字段在索引中存储的顺序和order by 字段的顺序不一致,不是严格正相关导致 MySQL 根据结果重新排序。
order by 语句利用索引的有序性是有比较高要求的,组合索引中 order by 之前的字段必须是等值查询,不能是 in、between、<、> 等范围查询,explain 的 type 是 range 的 sql 都会导致 order by 不能正常利用索引的有序性。
动手实践一下,初始化一张表 x
createtable x(idintnotnull auto_increment primary key, a int ,b int,key idx(a,b));insertinto x(a,b) values(1,8),(1,6),(1,3),(2,1),(2,2),(2,4),(3,7),(3,9);
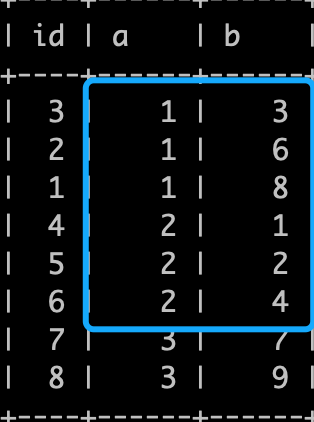
索引中存储的 (a,b) 顺序如下
mysql> select * from x order by a, b; +----+------+------+| id | a | b |+----+------+------+| 3 |1| 3 || 2 |1| 6 || 1 |1| 8 || 4 |2| 1 || 5 |2| 2 || 6 |2| 4 || 7 |3| 7 || 8 |3| 9 |+----+------+------+8 rows in set (0.00 sec)
对于组合索引 (a,b) 在 where 条件中 a=2使用等值查询,explain 的 extra 字段中提示 using index ,并无额外的排序。
mysql> select * from x where a=2 order by b;+----+------+------+| id | a | b |+----+------+------+| 4 | 2 | 1 || 5 | 2 | 2 || 6 | 2 | 4 |+----+------+------+3rows inset (0.00 sec) mysql> desc select * from x where a=2 order by b \G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: x partitions: NULL type: refpossible_keys: idx key: idx key_len: 5ref: const rows: 3 filtered: 100.00 Extra: Using index1 row inset, 1 warning (0.00 sec)
对于组合索引 (a,b) 在 where 条件中 a 使用范围查询,执行计划中出现 using filesort 排序。说明 order by b 并未利用索引的有序性,进行了额外的排序。
mysql> select * from x where a>=1and a<3 order by b;+----+------+------+| id | a | b |+----+------+------+| 4 |2| 1 || 5 |2| 2 || 3 |1| 3 || 6 |2| 4 || 2 |1| 6 || 1 |1| 8 |+----+------+------+6 rows in set (0.00 sec) mysql> desc select * from x where a>=1and a<3 order by b \G*************************** 1. row ***************************id:1select_type: SIMPLEtable: xpartitions: NULLtype: rangepossible_keys: idxkey: idxkey_len:5ref: NULLrows:6filtered:100.00Extra: Using where; Using index; Using filesort1 row in set, 1 warning (0.01 sec)
数据 a b 在索引中的顺序和实际访问的结果顺序不一致,需要额外的排序就产生了 file sort 。