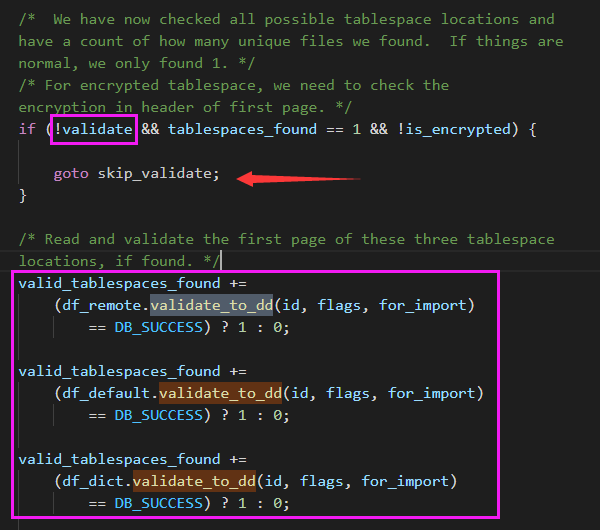
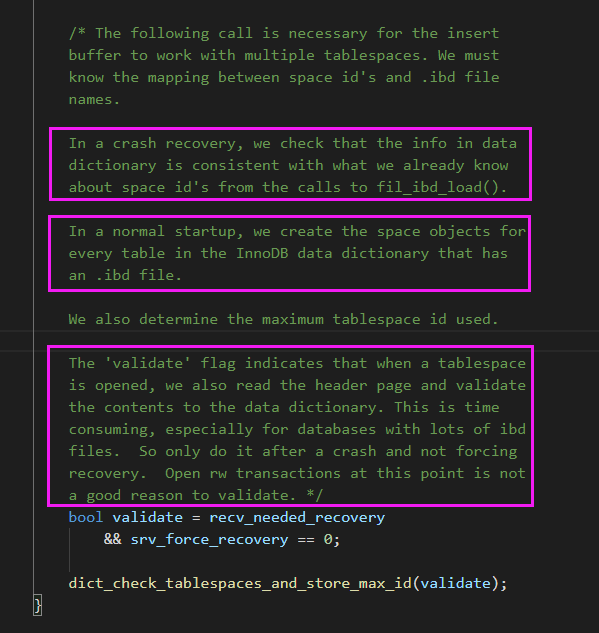
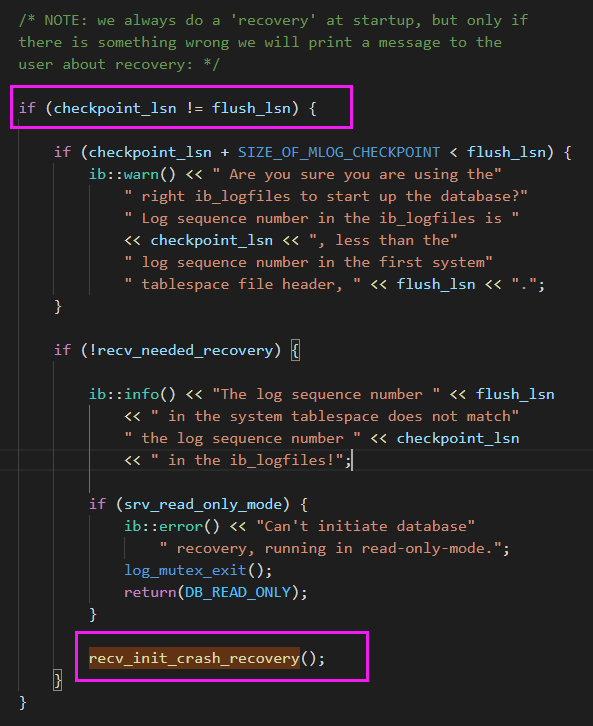
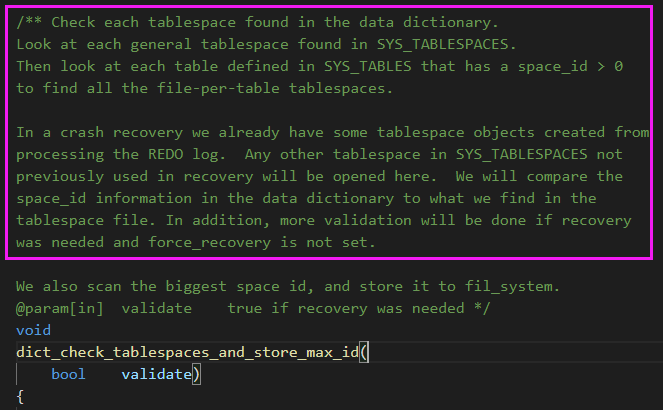
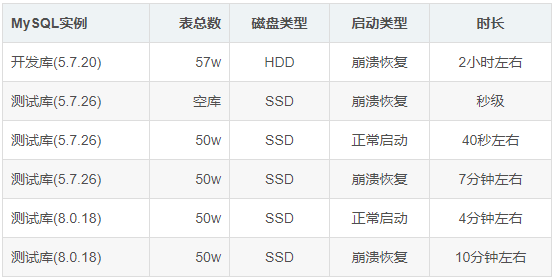
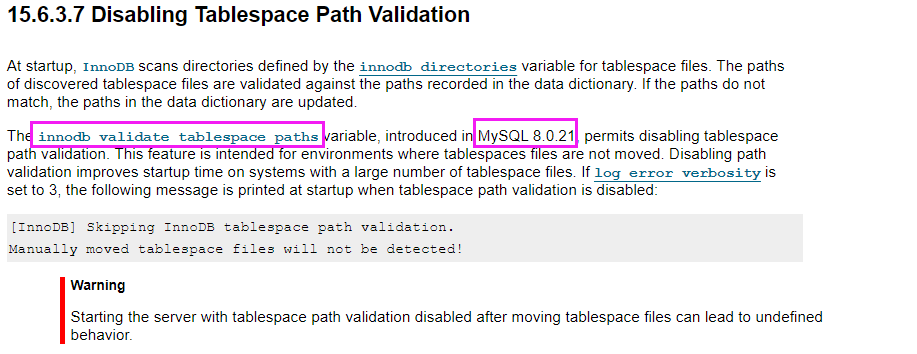
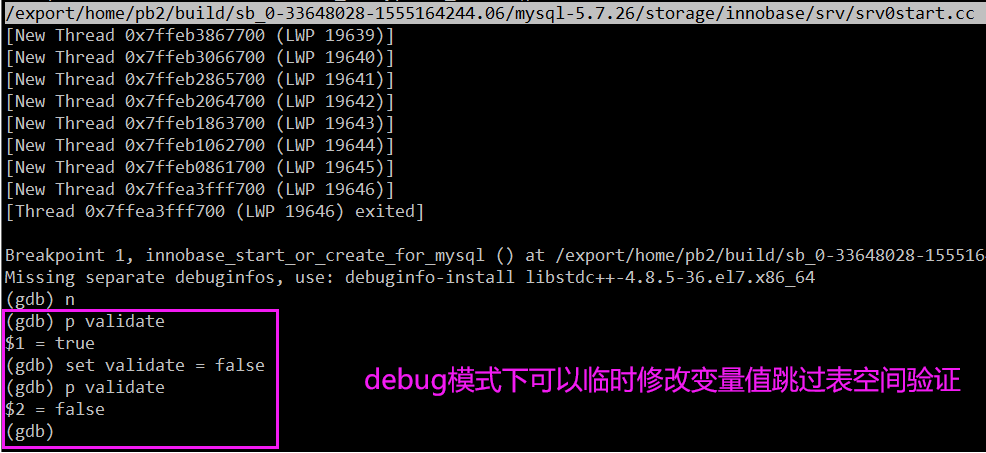
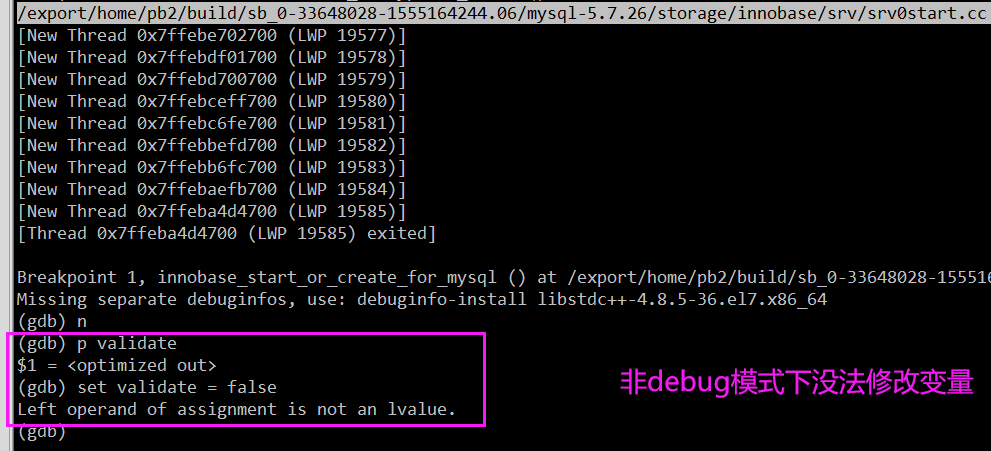
在 MySQL 崩溃恢复时,用 pstack 打了栈帧,再用 pt-pmp 工具分析栈帧后显示如下:pread64(libpthread.so.0),os_file_io(os0file.cc:5435),os_file_pread(os0file.cc:5612),os_file_read_page(os0file.cc:5612),os_file_read_no_error_handling_func(os0file.cc:6069),pfs_os_file_read_no_error_handling_func(os0file.ic:341),Datafile::read_first_page(os0file.ic:341),Datafile::validate_first_page(fsp0file.cc:551),Datafile::validate_to_dd(fsp0file.cc:404),fil_ibd_open(fil0fil.cc:3969),dict_check_sys_tables(dict0load.cc:1465),dict_check_tablespaces_and_store_max_id(dict0load.cc:1525),innobase_start_or_create_for_mysql(srv0start.cc:2329),innobase_init(ha_innodb.cc:4048),ha_initialize_handlerton(handler.cc:838),plugin_initialize(sql_plugin.cc:1197),plugin_init(sql_plugin.cc:1538),init_server_components(mysqld.cc:4033),mysqld_main(mysqld.cc:4673),__libc_start_main(libc.so.6),_start
根据函数名字,感觉像是在遍历校验每个表空间文件的有效性?,难道 MySQL 崩溃恢复时会额外进行校验操作?貌似和表数量扯上点关系了。