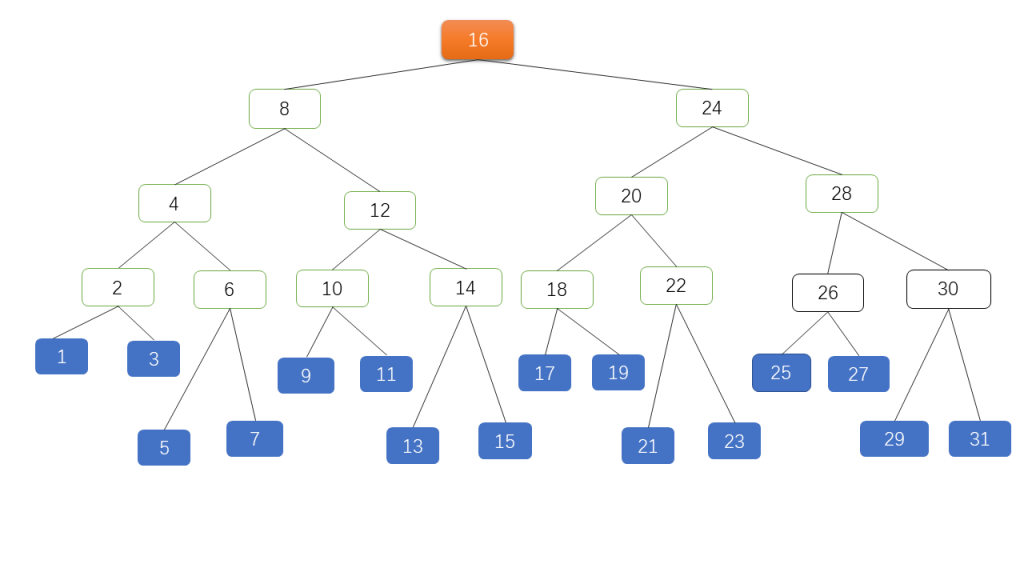
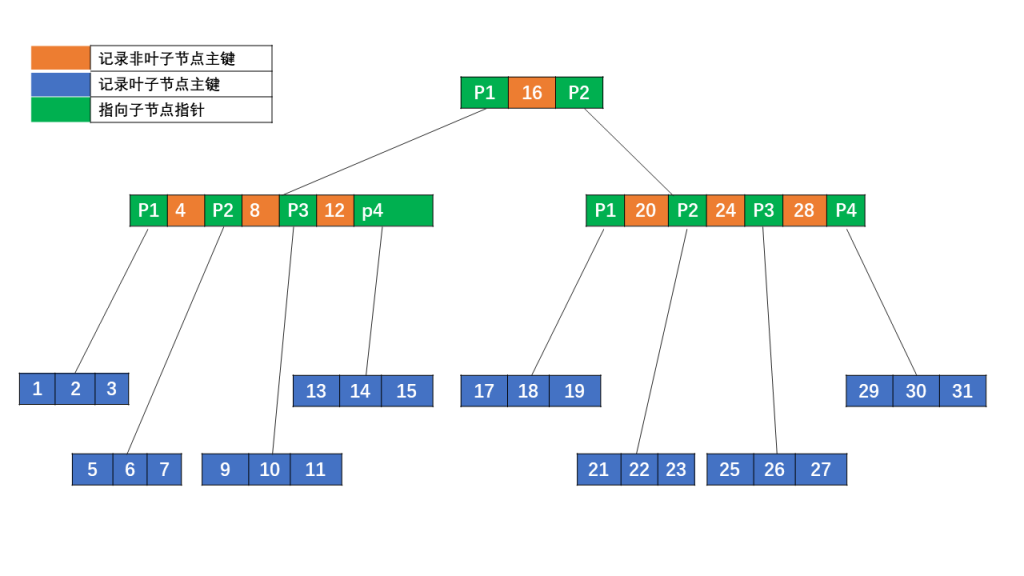
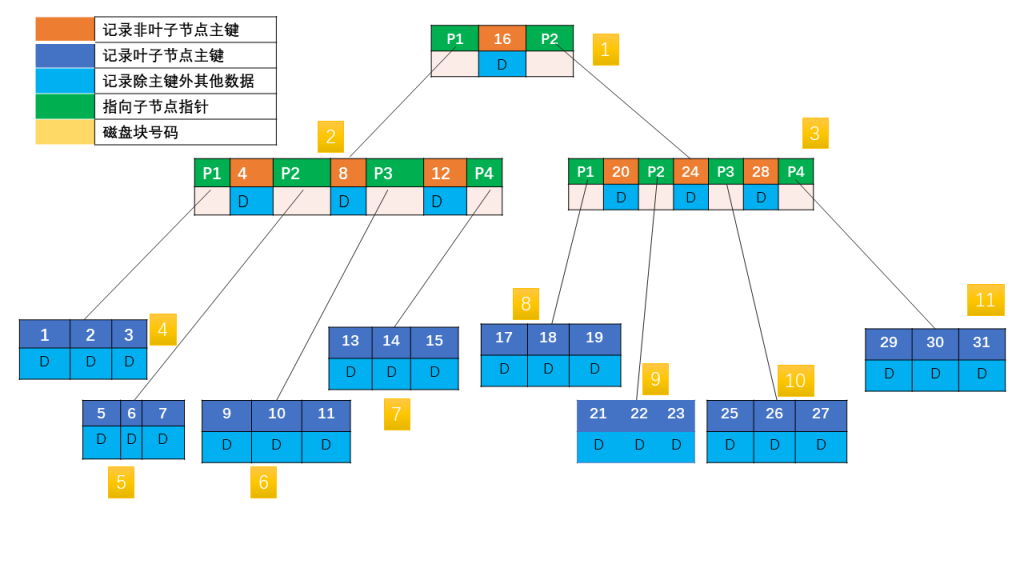
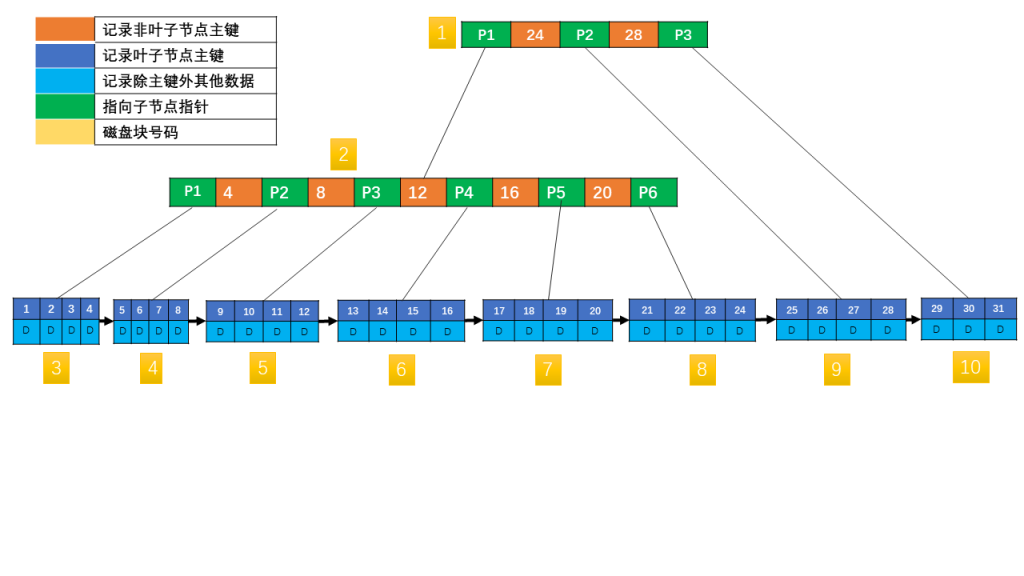
B 树的特性:(m 为阶数:结点的孩子个数最大值)
1. 树中每个节点最多含有 m 个孩子节点 (m>=2);
2. 除根节点和叶子结点外,其他节点的孩子数量 >=ceil(m / 2);
3. 若根节点不是叶子结点,最少有两个孩子
4. 每个非叶子结点中包含有 n 个关键字信息:(n,P0,K1,P1,K2,P2,……,Kn,Pn) 其中:
- Ki (i=1…n) 为关键字,且关键字按顺序升序排序 K(i-1)< Ki
- Pi 为指向儿子节点的指针,且指针 P(i-1) 指向的儿子节点里所有关键字均小于 Ki,但都大于 K(i-1)
- 关键字的个数 n 必须满足:[ceil(m / 2)-1]<= n <= m-1
- 如果一个结点有 n 个关键字,那么该结点有 n+1 个分支。这 n+1 个关键字按照递增顺序排列