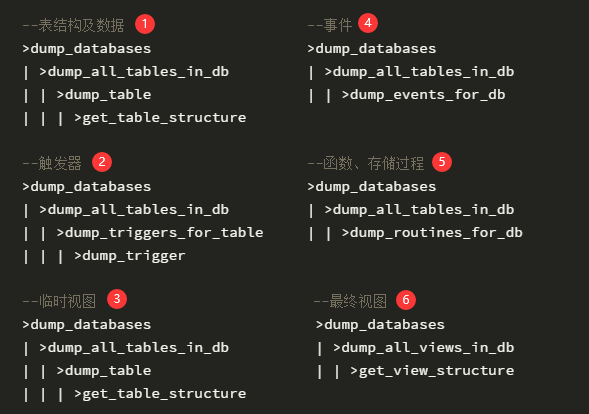
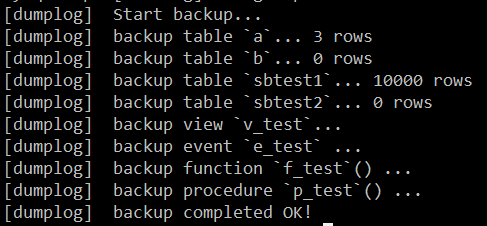
通过 sysbench 造测试数据后,分别使用改写后的 mysqldump 与原生的 mysqldump 进行多次远程备份,查看平均耗时。
这里选择远程备份测试是因为很多实际使用场景也是远程备份,而且远程备份更能体现出频繁打印信息对备份性能的影响。
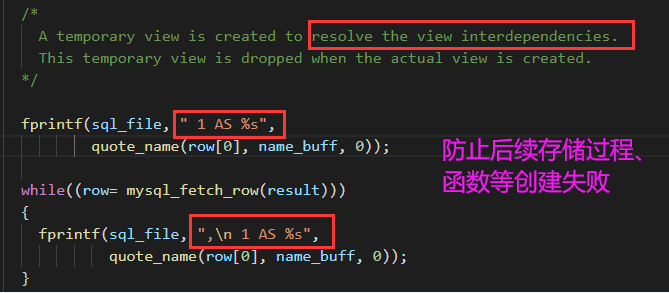
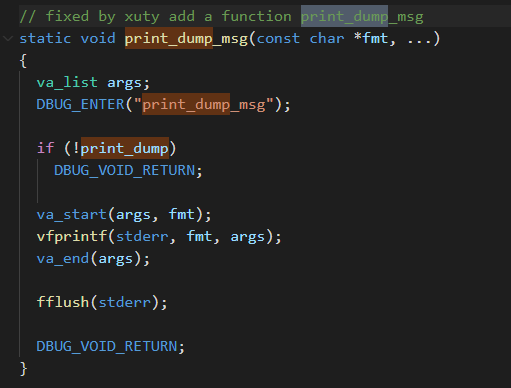
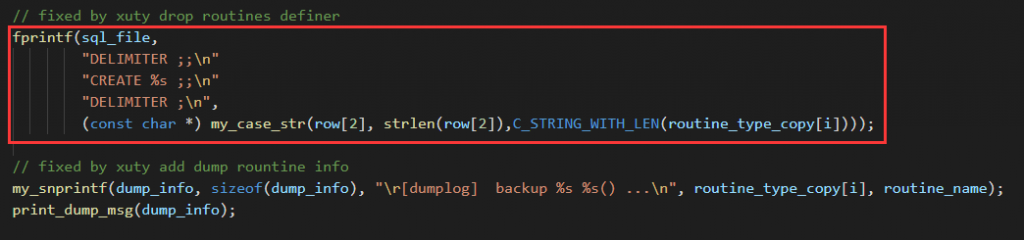
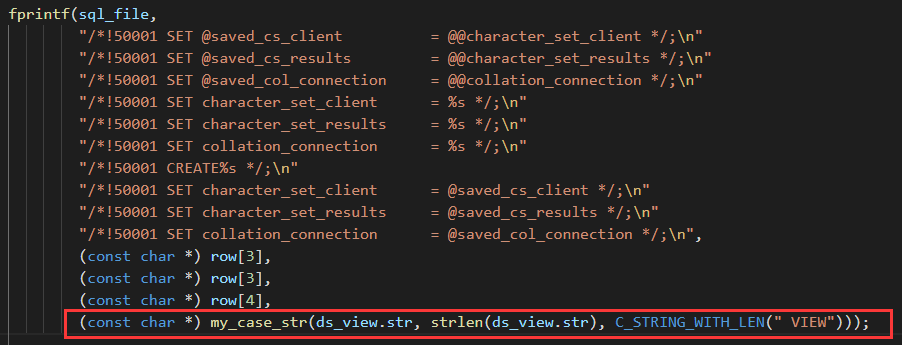
实际压测发现,如果每一行都打印一次,会严重影响性能,所以改成 1W 行打印一次,影响会比较小。
另外踩了个坑,一开始测试的时候是使用开启 debug 编译的 mysqldump,所以会执行很多多余的 debug 代码,备份速度非常慢,关闭 debug 重新编译后,速度就比较正常了。