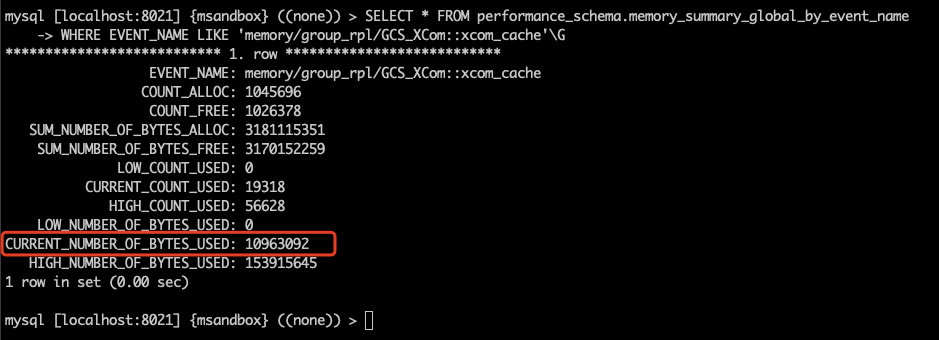
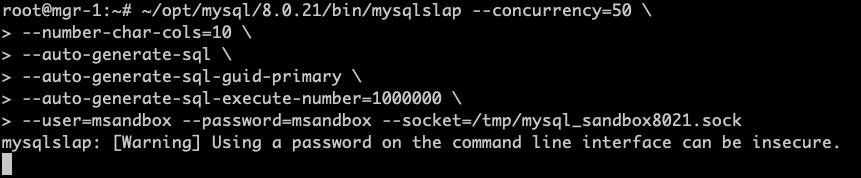
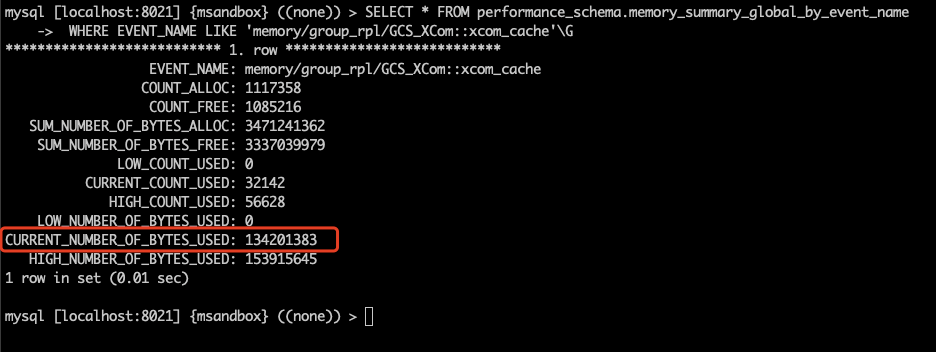
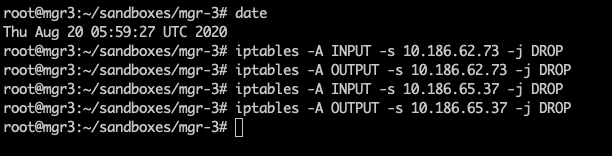
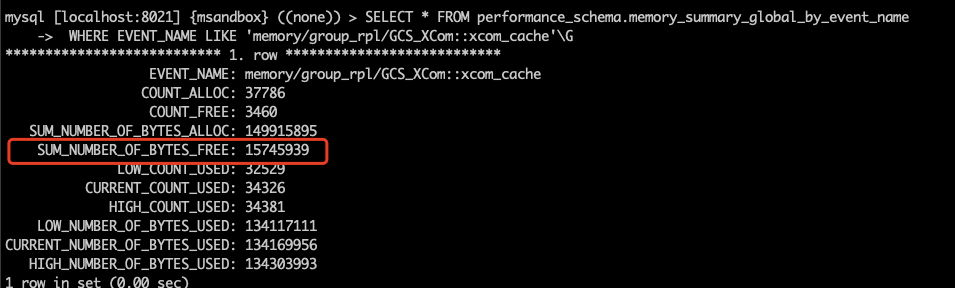
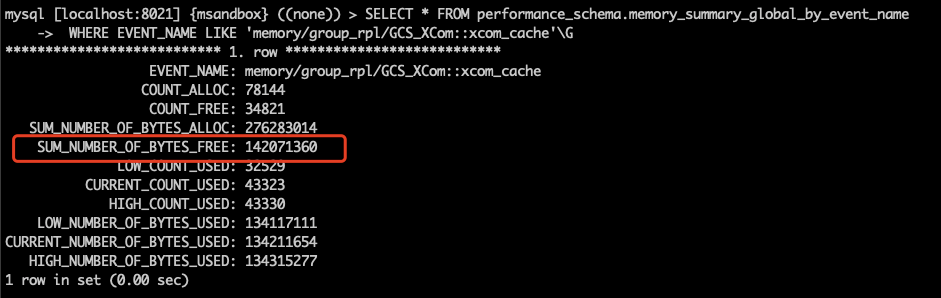
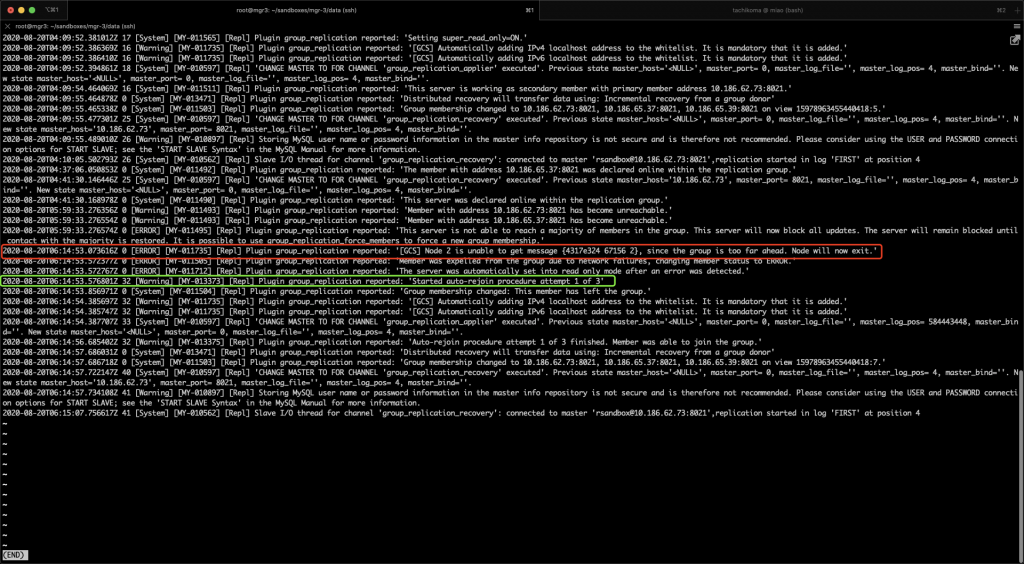
问题 已知情况如下:1. MySQL 版本为 8.0.21(随 8.0 的小版本升级,MGR 参数和行为变更频繁,需要特别注意版本号)。2. MGR 架构,一个节点 C 网络不稳时,与其他节点的通讯断开。3. 通讯断开后,一定时间内(5 秒 + group_replication_member_expel_timeout 秒)其他节点开始质疑节点 C 可能掉线。在其他节点上,节点 C 的状态为 UNREACHABLE。其他节点仍然能协商并提交新事务,其协商的信息会保存在消息缓存中。4. 通讯恢复后,节点 C 会从其他节点的消息缓存中获取漏掉的信息,并跟上进度。那么,消息缓存会被撑满么?撑满以后会造成什么影响? 实验 我们先建三节点的 MGR,此处忽略步骤,大家按照官方文档进行就行。来看一下三节点的状态: 我们知道 MGR 的消息缓存大小由 group_replication_message_cache_size 参数控,我们在三个节点上都将参数设置为最小值(128M),这样比较容易撑满: 我们还需要将 group_replication_member_expel_timeout 调大,使得之后通讯故障的节点 C 不会被集群踢出。 我们需要知道消息缓存已经用了多少,可以使用下面的命令: 现在我们上一些数据库压力,让 MGR 发送消息,将缓存填满: 看一下填满后的缓存状况: 下面,我们将 mgr-3 节点的网络通讯断开: 在其他节点查询状态,可以看到故障节点被质疑,但没有踢出: 同时,我们可以看到数据库压力仍然在继续进行。现在,在 primary 节点上,我们将内存统计表重置: 然后观察内存统计,查看缓存的释放量: 等待一段时间,可以看到缓存的释放量已经超过缓存大小,意味着整个缓存的内容已经完全换过一轮: 接下来,我们恢复故障节点的通讯。 通讯恢复后,故障节点应当从其他节点的缓存中,获取故障阶段的消息,但这些消息已经从缓存中被清掉了,我们看看故障节点的 error log: 可以看到,故障节点因为无法接上消息,报错退出集群。而后由于 auto-rejoin 机制,故障节点尝试重新加入集群,并通过 binlog 接续数据。 一些结论 本文涉及到两个 MGR 相关的参数:1. group_replication_member_expel_timeout行为:当某节点意外离线达到(5 秒 + group_replication_member_expel_timeout 秒)后,MGR 将其踢出集群。如果节点意外离线时间较短,MGR 可以自动接续消息,仿佛节点从未离开。优点:网络等发生意外时,该参数越大,越不需要人工参与,集群可自动恢复。成本:该参数越大,就需要更多的消息缓存。成本:节点未被踢出集群时,可以从该节点读到过期数据。该参数越大,读到过期数据的概率越大。2. group_replication_message_cache_size优点:该参数越大,可缓存的消息越多,故障节点恢复后自动接续的概率越大,不需要人工参与运维。成本:消耗内存。小贴士大家在选择 MGR 参数时,建议从以下几个方向考虑,达成平衡:对环境不稳定的容忍程度自动化程度(是否需要人工参与)读过期数据的概率物理资源消耗 相关推荐: 第18问:MySQL CPU 高了,怎么办? 第17问:如何评估 alter table 的进度? 分类: 一问一实验(ChatDBA) 标签:参数变更消息缓存组复制