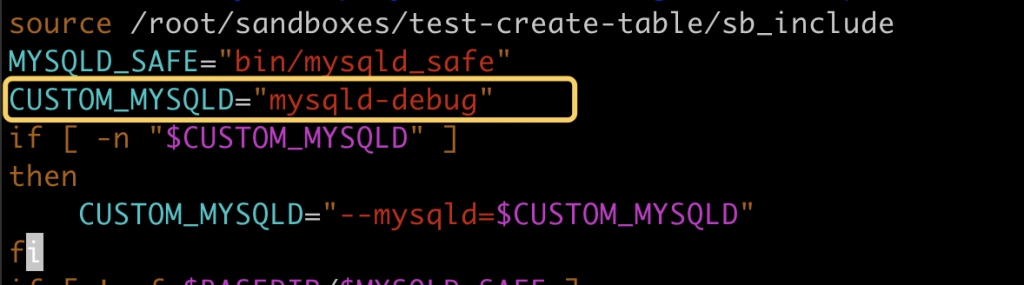
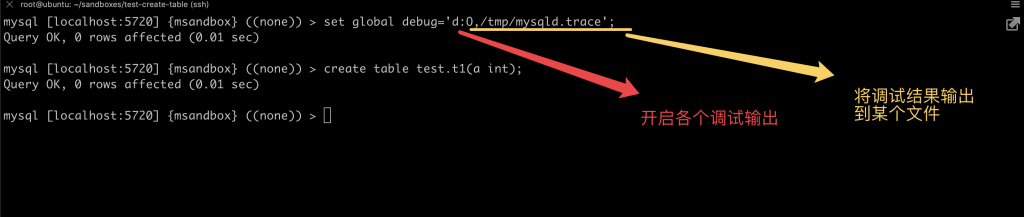
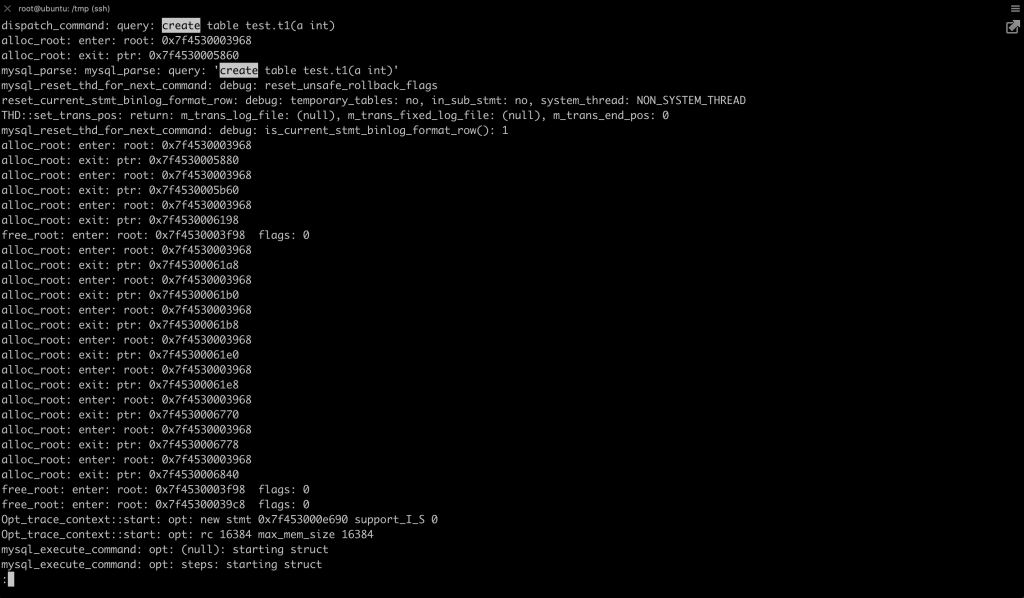
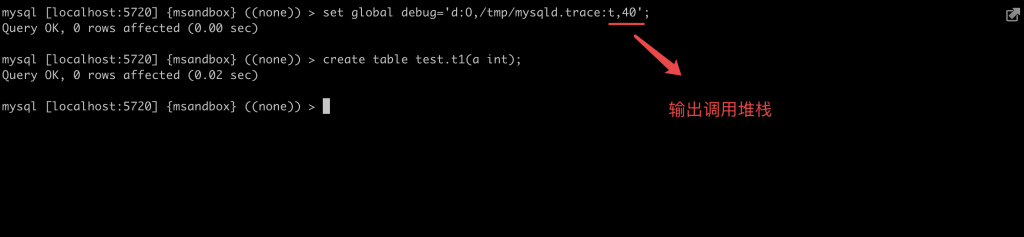
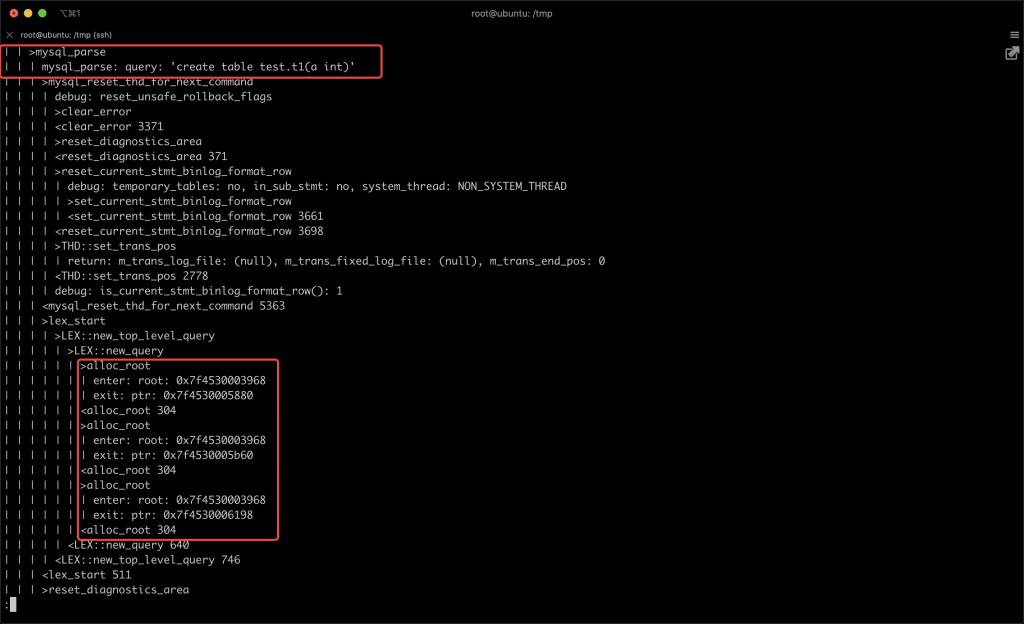
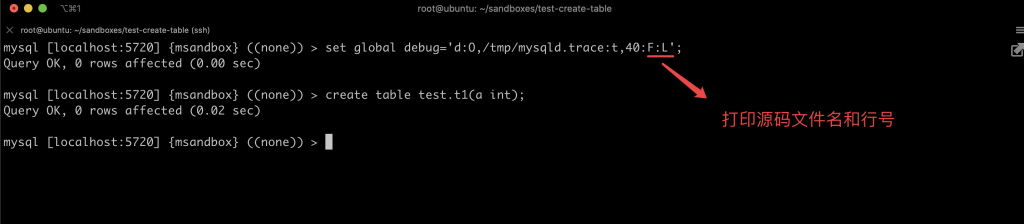
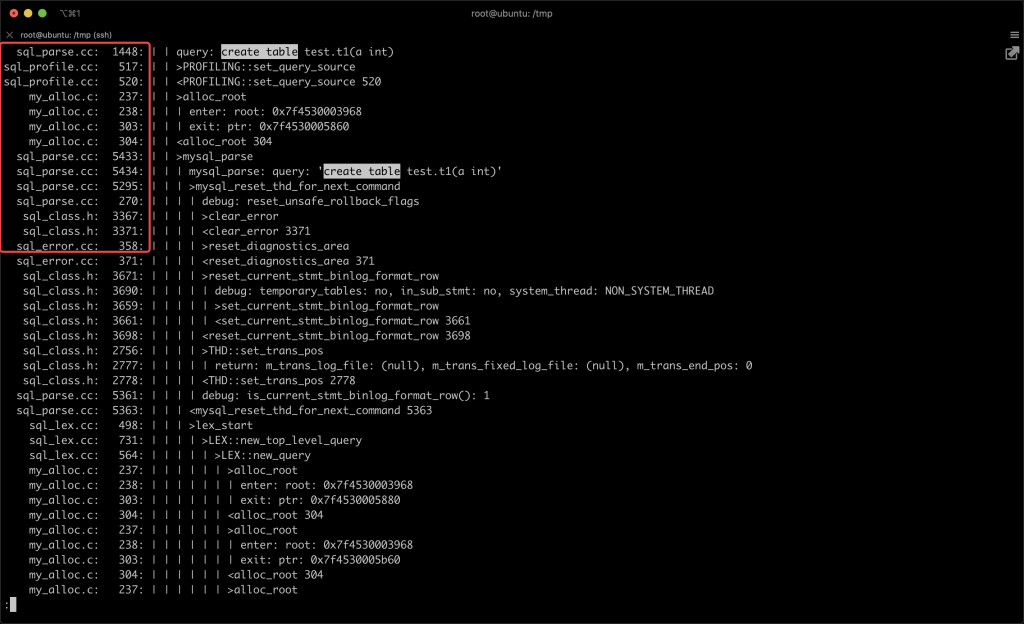
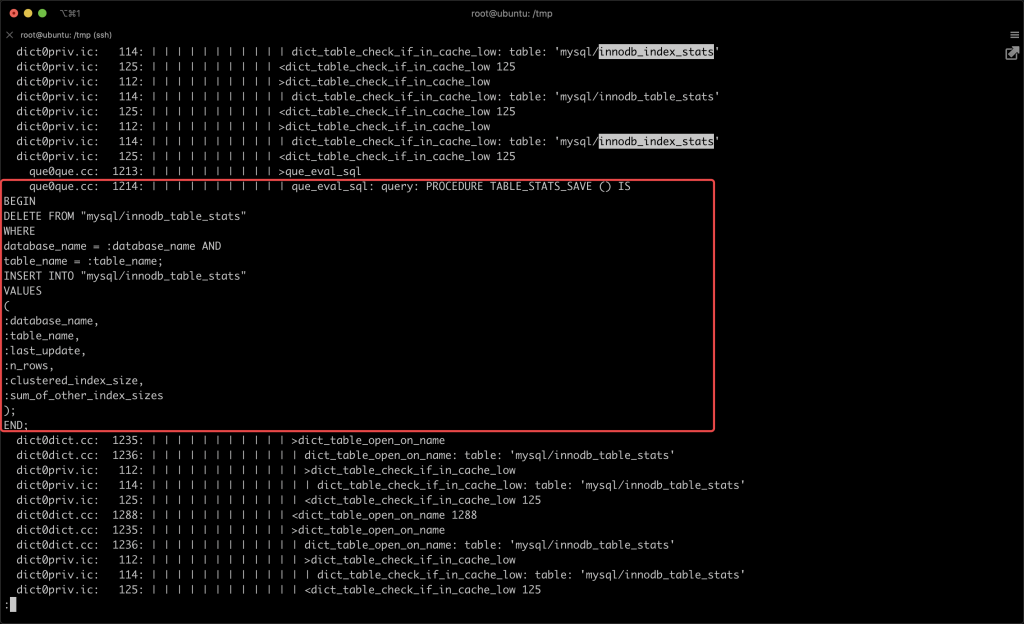
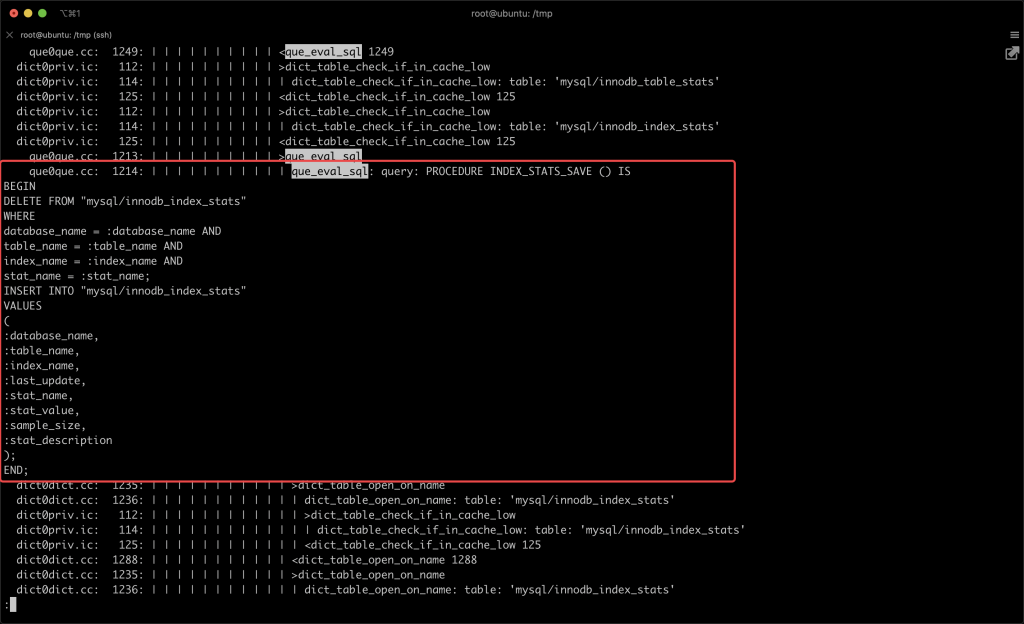
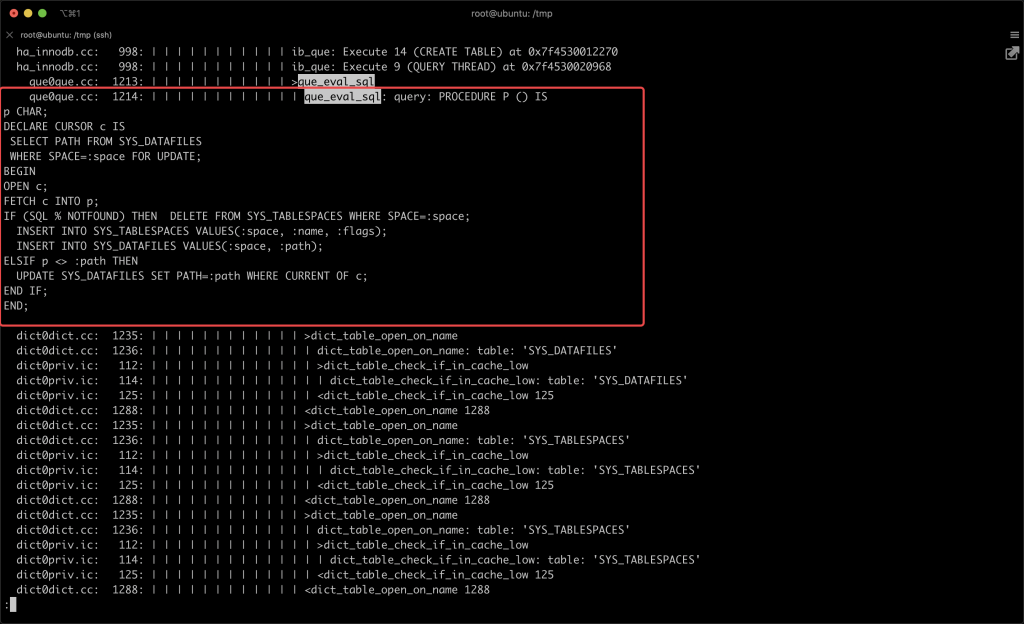
本文关键字: 统计表,debug 问题 我们知道在 MySQL 中创建一张表时,一些统计表会发生变化,比如:mysql/innodb_index_stats,会多出几行对新表的描述。 那么会变更几张表?这些统计表是如何变化的? 实验 本期我们用 MySQL 提供的 DBUG 工具来研究 MySQL 的 SQL 处理流程。 起手先造个实例 这里得稍微改一下实例的启动文件 start,将 CUSTOM_MYSQLD 改为 mysqld-debug: 重启一下实例,加上 debug 参数: 我们来做一两个实验,说明 DBUG 包的作用:先设置一个简单的调试规则,我们设置了两个调试选项:d:开启各个调试点的输出O,/tmp/mysqld.trace:将调试结果输出到指定文件 然后我们创建了一张表,来看一下调试的输出结果: 可以看到 create table 的过程中,MySQL 的一些细节操作,比如分配内存 alloc_root 等 这样看还不够直观,我们增加一些信息: 来看看效果: 可以看到输出变成了调用树的形式,现在就可以分辨出 alloc_root 分配的内存,是为了解析 SQL 时用的(mysql_parse) 我们再增加一些有用的信息: 可以看到结果中增加了文件名和行号: 现在我们可以在输出中找一下统计表相关的信息: 可以看到 MySQL 在这里非常机智,直接执行了一个内置的存储过程来更新统计表。 沿着 que_eval_sql,可以找到其他类似的统计表,比如下面这些: 本次实验中,我们借助了 MySQL 的 DBUG 包,来让 MySQL 将处理过程暴露出来。MySQL 中类似的技术还有不少,比如 performance_schema,OPTIMIZER_TRACE 等等。 这些技术将 MySQL 的不同方向的信息暴露出来,方便大家理解其中机制。 关于 MySQL 的技术内容,你们还有什么想知道的吗?赶紧留言告诉小编吧! 分类: 一问一实验(ChatDBA) 标签:debug统计表