3. set names 语句
SET NAMES {'charset_name'[COLLATE 'collation_name'] | DEFAULT}
set names latin1 collate latin1_bin;
执行后会默认执行一系列语句,也就是把非服务端的相关参数给重新设定了。set session character_set_results = latin1;
set session character_set_client = latin1;
set session character_set_connection=latin1;
set session collation_connection = latin1_bin;
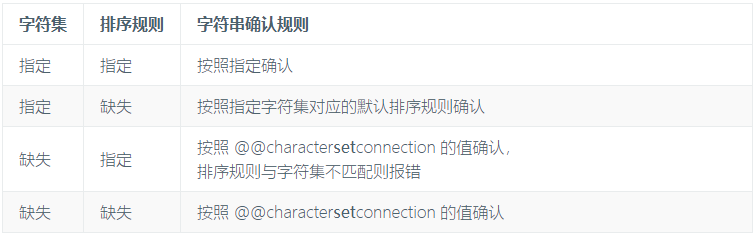
那现在重新执行确认一下,跟 introducer 一样,没有指定 collate 语句,默认为字符集对应的排序规则。mysql> set names latin1 ;Query OK, 0 rows affected (0.00 sec)
-- 那这里看到相关参数值全部被改了。
mysql> select * from performance_schema.session_variables where variable_name in ('character_set_connection','collation_connection','character_set_results','character_set_client');+--------------------------+-------------------+| VARIABLE_NAME | VARIABLE_VALUE |+--------------------------+-------------------+| character_set_client | latin1 || character_set_connection | latin1 || character_set_results | latin1 || collation_connection | latin1_swedish_ci |+----------------------------------------------+
mysql> set names default;Query OK, 0 rows affected (0.00 sec)
mysql> select * from performance_schema.session_variables where variable_name in ('character_set_connection','collation_connection','character_set_results','character_set_client');+--------------------------+--------------------+| VARIABLE_NAME | VARIABLE_VALUE |+--------------------------+--------------------+| character_set_client | utf8mb4 || character_set_connection | utf8mb4 || character_set_results | utf8mb4 || collation_connection | utf8mb4_0900_ai_ci |+--------------------------+--------------------+4 rows in set (0.00 sec)
不过有一点要注意的是,并不是所有字符集都适用于这条语句,比如定长字符集 utf32,设置就会报错。因为变量 @@character_set_client 不支持这个字符集。mysql> set names utf32;ERROR 1231 (42000): Variable 'character_set_client' can't be set to the value of 'utf32'