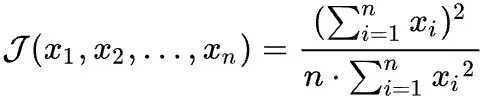参考:
https://www.percona.com/blog/2016/02/10/estimating-potential-for-mysql-5-7-parallel-replication/
https://www.slideshare.net/JeanFranoisGagn/fosdem-2018-premysql-day-mysql-parallel-replication
https://jfg-mysql.blogspot.hk/2017/02/metric-for-tuning-parallel-replication-mysql-5-7.html
https://jfg-mysql.blogspot.com/2018/01/write-set-in-mysql-5-7-group-replication.html?m=1
http://mysqlhighavailability.com/improving-the-parallel-applier-with-writeset-based-dependency-tracking/