

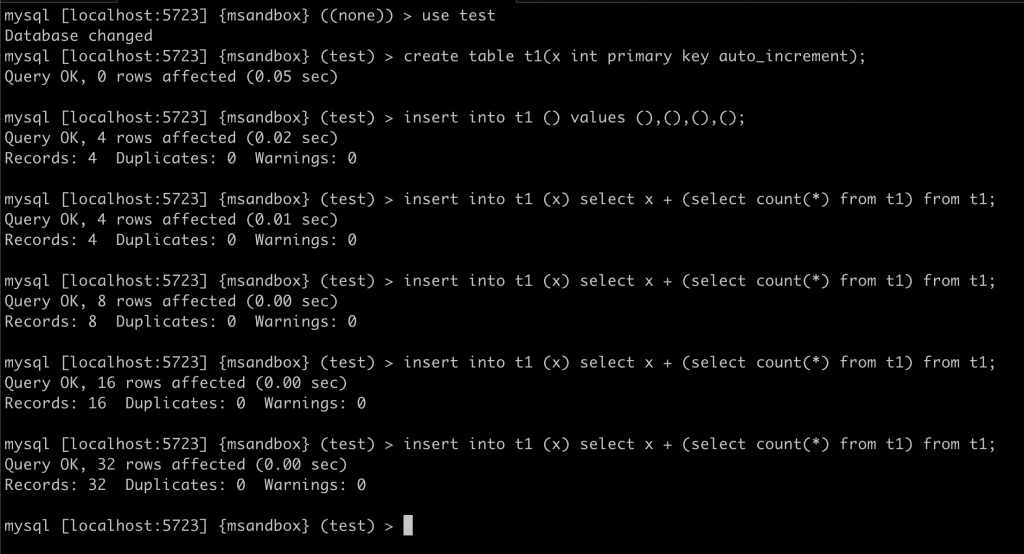
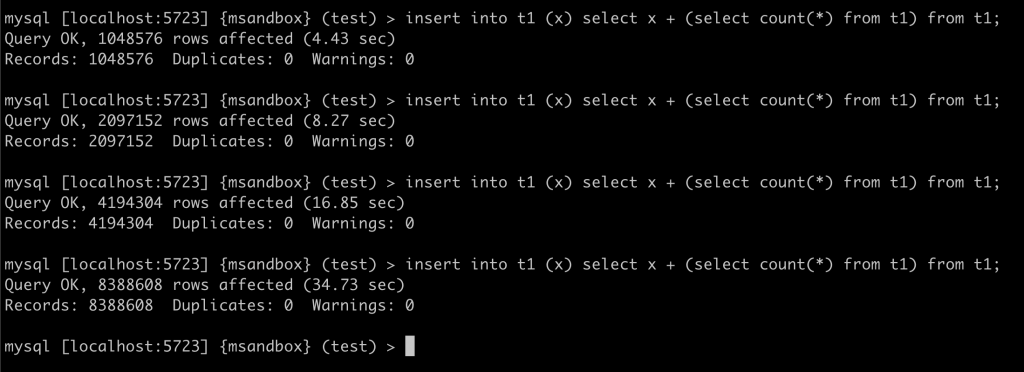
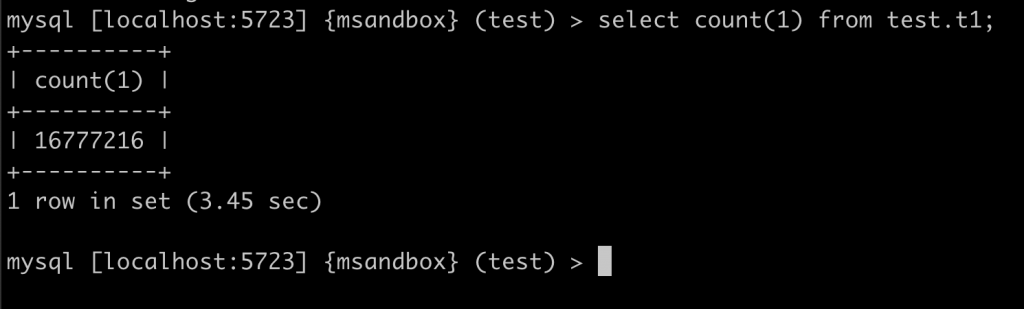

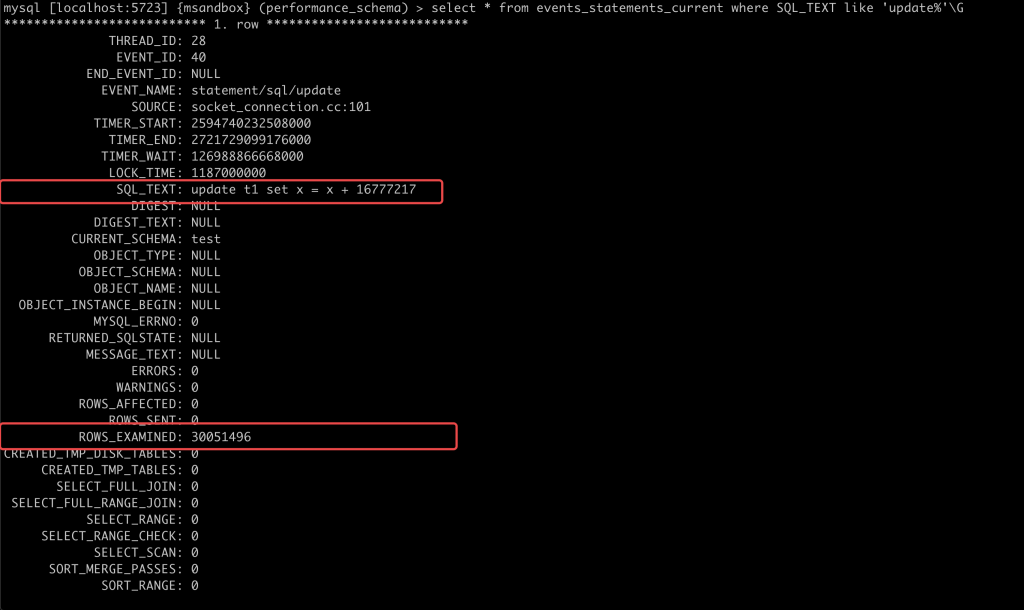


 小贴士
小贴士
information_schema.tables 中,提供了对表行数的估算,比起使用 select count(1) 的成本低很多,几乎可以忽略不计。


小贴士
information_schema.tables 中,提供了对表行数的估算,比起使用 select count(1) 的成本低很多,几乎可以忽略不计。