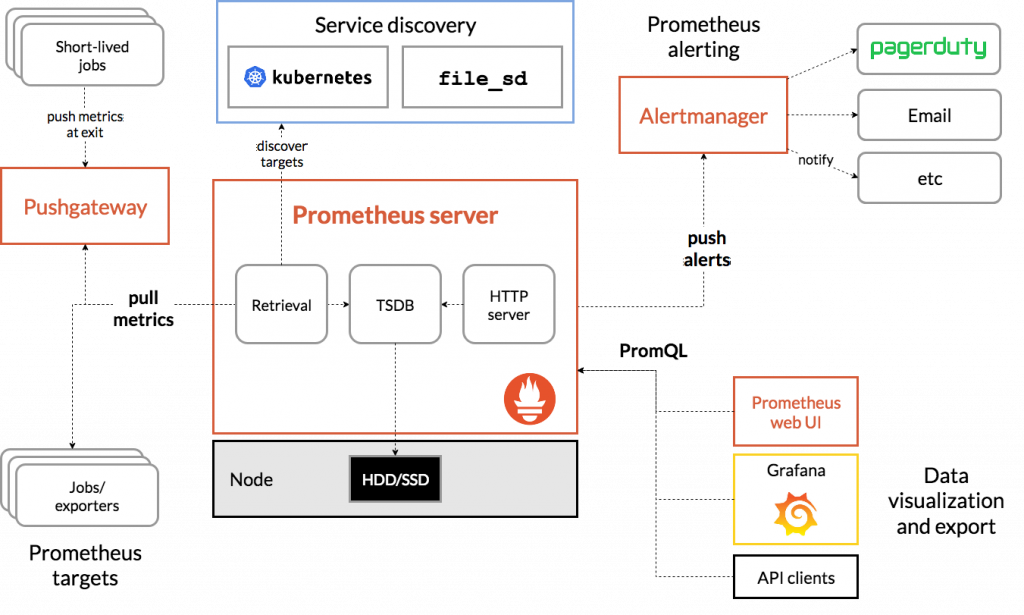
开篇致辞 大家好,从今天开始,我将开启一个全新的专栏叫做《详解 Prometheus》。专栏会详细介绍 Prometheus 这款优秀的开源监控告警系统的使用,欢迎感兴趣的小伙伴关注! 一、产品简介 Prometheus 最开始是由 SoundCloud 开发的开源监控告警系统,是 Google BorgMon 监控系统的开源版本。 在 2016 年,Prometheus 加入 CNCF,成为继 Kubernetes 之后第二个被 CNCF 托管的项目。随着 Kubernetes 在容器编排领头羊地位的确立,Prometheus 也成为 Kubernetes 容器监控的标配。 本文接下来将会对 Prometheus 做一个介绍。 二、设计架构 监控系统的总体架构大多是类似的,都有数据采集、数据处理存储、告警动作触发和告警,以及对监控数据的展示。 下面是 Prometheus 的架构: Prometheus Server 负责定时从 Prometheus 采集端 Pull(拉) 监控数据。Prometheus 采集端可以是实现了 /metrics 接口的服务,可以是从第三方服务导出监控数据的 exporter,也可以是存放短生命周期服务监控数据的 Pushgateway。相比大多数采用 Push(推) 监控数据的方式,Pull 使得 Promethues Server 与被采集端的耦合度更低,Prometheus Server 更容易实现水平拓展。 对于采集的监控数据,Prometheus Server 使用内置时序数据库 TSDB 进行存储。同时也会使用这些监控数据进行告警规则的计算,产生的告警将会通过 Prometheus 另一个独立的组件 Alertmanager 进行发送。Alertmanager 提供了十分灵活的告警方式,并且支持高可用部署。 对于采集到的监控数据,可以通过 Prometheus 自身提供的 Web UI 进行查询,也可以使用 Grafana 进行展示。 三、快速部署 3.1 下载 Prometheus 安装包,并解压wget https://github.com/prometheus/prometheus/releases/download/v2.16.0/prometheus-2.16.0.darwin-amd64.tar.gztar xvzf prometheus-2.16.0.darwin-amd64.tar.gzcd prometheus-2.16.0.darwin-amd64 3.2 配置 PrometheusPrometheus 的配置是 YAML 格式的,下面使用的配置文件主要包括了三部分:global,rule_files,scrape_configs。global定义 Prometheus 拉取监控数据的周期 scrape_interval 和 告警规则的计算周期 evaluation_interval。rule_files指定了告警规则的定义文件。scrape_configs定义 Prometheus 采集端,这里的采集端可以静态指定,也可以配置服务发现功能自动发现采集端。 由于 Prometheus 自身也实现了 /metrics 接口,所有我们在这里配置它自己作为采集端。 配置示例:global: scrape_interval: 15s evaluation_interval: 15srule_files: # - "first.rules" # - "second.rules"scrape_configs: - job_name: prometheus static_configs: - targets: ['localhost:9090'] 3.3 启动 Prometheus./prometheus --config.file=prometheus.yml当 Prometheus 启动之后,可以在浏览器输入 http://localhost:9090 打开 Prometheus Web UI。 3.4 使用 Prometheus Web UIPrometheus Web UI 一般有三个用途:查询某个 metric,查看当前有哪些告警触发,查看当前的状态(使用的配置、告警规则、数据采集端)。 下面是查询 prometheus_http_request_total 的结果,当前触发的告警和当前的状态可以在 Alerts 和 Status 中查看。 四、优点 多维度的数据模型:时序数据由指标(metric)名称和标签对标识提供灵活的数据查询语言 –PromQL同时支持监控数据的本地存储和远程存储同时支持静态文件配置和动态发现监控对象易于和结合 Grafana 等 GUI 组件展示数据与 Kubernetes 相融合 五、缺点 任何工具都没有银弹,Prometheus 也不例外,它有自身的局限性:它只能采集某个 metric 的数值,所以它能监控某个调用的执行时间,但是不能还原整个调用链。Prometheus 本地存储的设计初衷是存储短期的数据(通常是一个月),所以对于需要存储大量的历史数据的场景需要使用如 OpenTSDB 这样的远端存储。Prometheus 的监控数据没有对单位进行定义,通常需要使用约定好的默认单位或者在 metric 的命名中加上单位。 六、总结 市面上还有一些其他的监控系统,比如 Zabbix、Open-Falcon 等。这里为什么要去关注 Prometheus? 不仅仅是因为 Prometheus 本身有着不错的性能和拓展性,社区活跃度高,更重要的是它对云原生支持得最好。一个项目的成功当然要靠自我奋斗,当然也要考虑历史的进程,Prometheus 这样一个就是顺应云原生趋势的项目。 本文介绍了它的架构、使用例子及其优缺点,后面将会从架构图中各个方面进行更为详细的介绍。 分类: 详解 Prometheus 标签:Prometheus