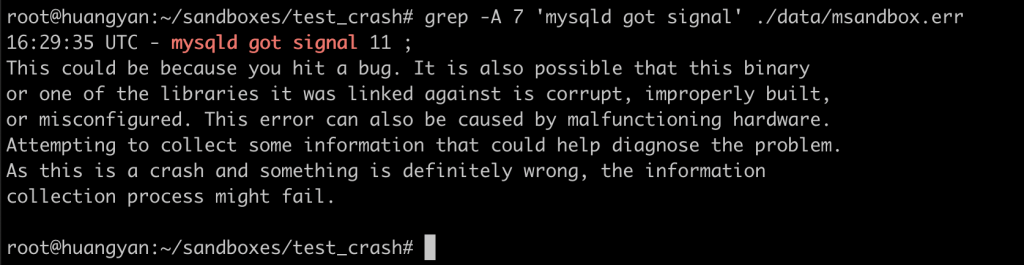
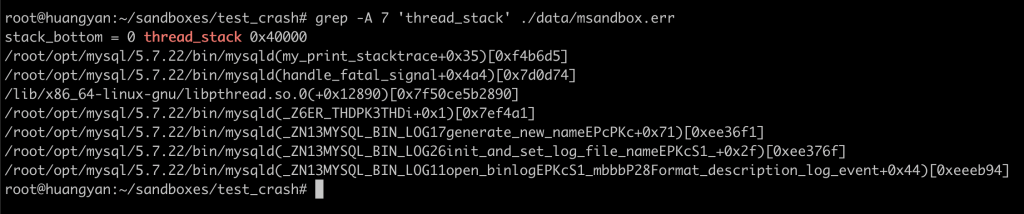
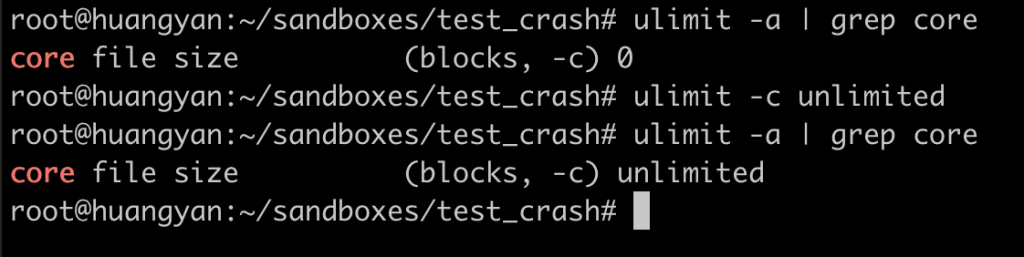
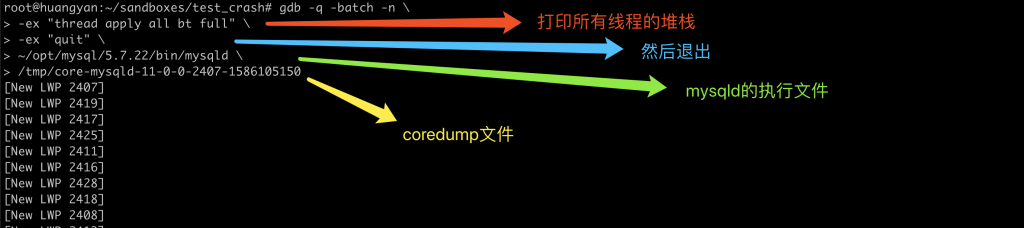
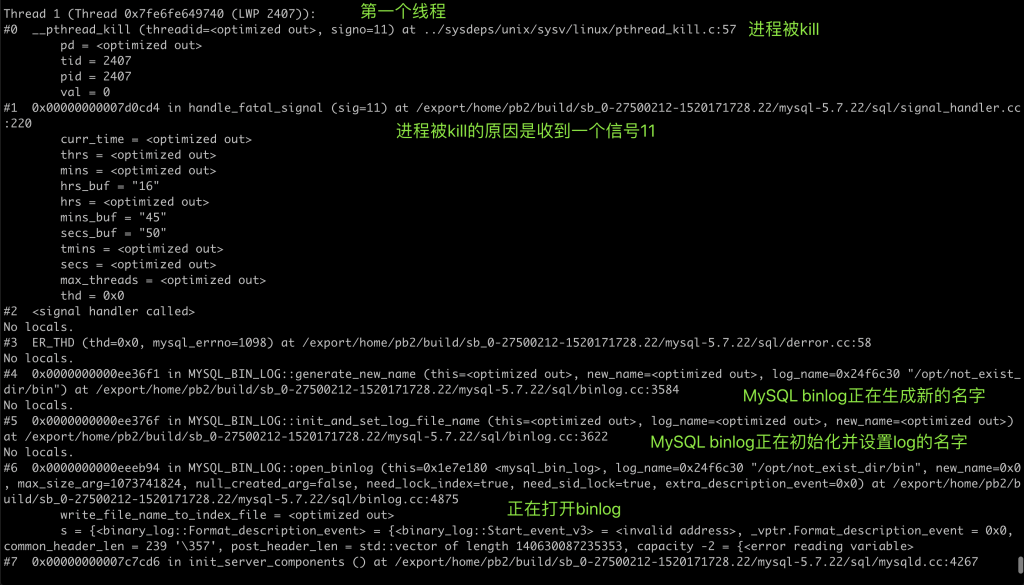
问题 我的 MySQL 偶尔崩溃,如果需要追查原因,应该如何保留现场? 实验 MySQL 随着版本不停迭代,崩溃的现象越来越少,也越来越隐蔽。一旦遇到生产环境上的 MySQL 崩溃,就需要保留现场信息,供分析用。虽然 MySQL 的 error log 中会打印部分信息,但对于比较隐蔽的崩溃,往往显得力不从心。因此我推荐开启 coredump,以备 MySQL 诊断需要。我们来模拟一个崩溃场景,然后配置 coredump 看看效果。 选取一个容易复现崩溃的 bug,我们选择了 bug #95294。 我们先安装一个 5.7 的数据库, 将其停掉,按照 bug #95294 的描述变更配置, 手工启动 mysqld,可以看到 mysqld 无声无息的退出了, 检查 error log,可以看到 MySQL 是因为异常崩溃了, error log 中有一段堆栈信息,可以用来判断这个崩溃的问题, 以上是 MySQL 能提供的所有信息,无法针对一些复杂场景进行分析。 下面我们开启 coredump,让 MySQL 在崩溃时能提供更多信息:以下命令开启了系统级别一些参数,具体的释义大家可自行谷歌。此处需要注意,我们将 core 文件生成到了 /tmp 目录下,需要保证其磁盘空间足够大: 我们还需要调整 MySQL 运行用户的 ulimit,在本文中,MySQL 的运行用户是 root,我们调整其 core file 的限制,使其能生成 core dump: 最后,我们要在 MySQL 配置里,允许 MySQL 生成 coredump: 现在我们可以再次运行 MySQL: 可以看到 MySQL 崩溃时,会告知已生成了 core dump 文件。在 error log 中也会有同样的信息: 我们来看一下这个 coredump 文件: coredump 文件会将崩溃当时的内存情况全部保留下来,所以文件体积会比较大。 在 MySQL 8.0.14 后,MySQL 提供了参数 innodb_buffer_pool_in_core_file,用于将 innodb buffer pool 从 coredump 中排除,用于减小 coredump 的体积。 那我们怎么使用 coredump 文件呢?可以用 gdb 去访问 coredump 文件,获取各种信息,此处举例如何获取所有线程的堆栈信息。 我们会得到一个非常长的堆栈信息,我们截取其中一小段,标注上简单的中文即可看懂。 结论 通过开启操作系统级别、放开用户限制、启用 MySQL 参数三个步骤,我们启用了 MySQL 的 coredump 功能,使得 MySQL 崩溃时留下了足够的线索。对于复杂崩溃的分析,还是需要将 coredump 交给专业的研发工程师手里,或者提交给 MySQL 开发团队。不过不管是什么场景,能提供一份 coredump,所有技术人员都会感谢你的。 分类: 一问一实验(ChatDBA) 标签:MySQL