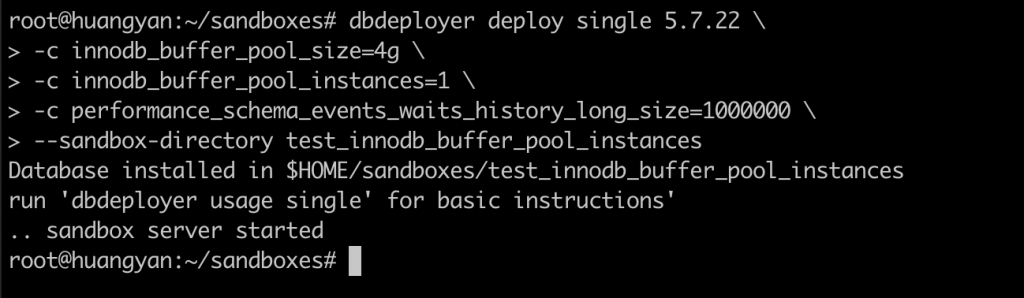
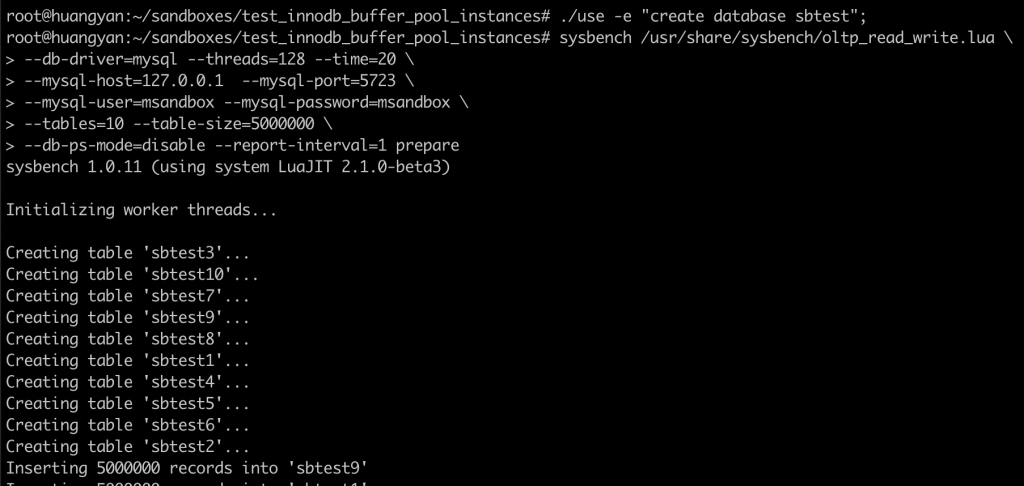
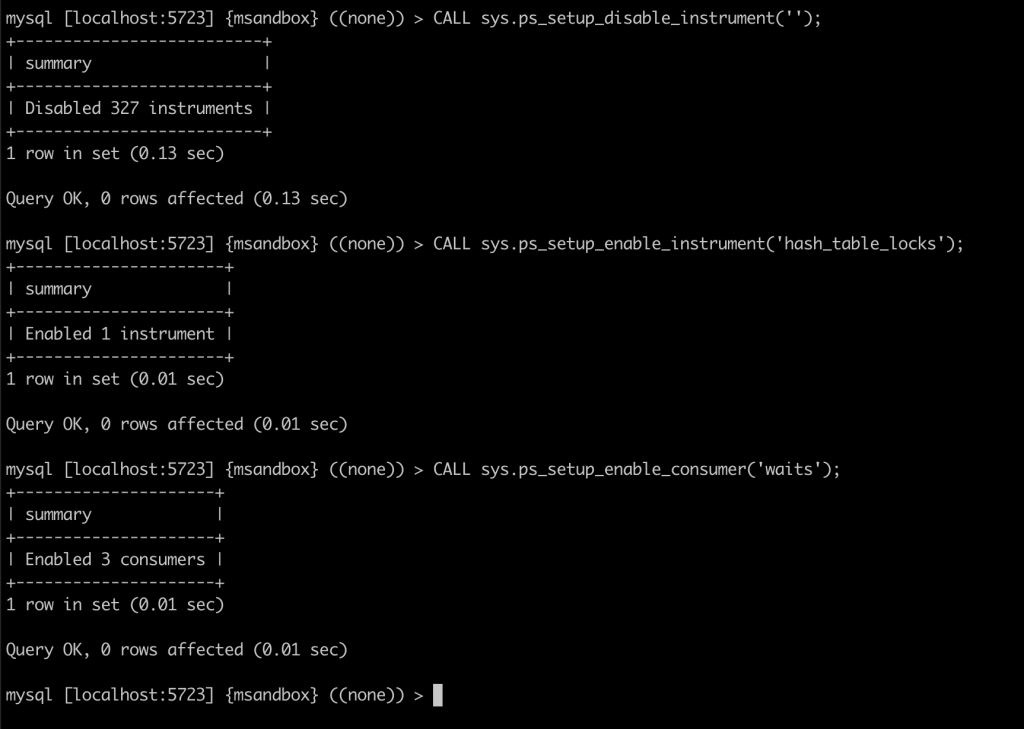
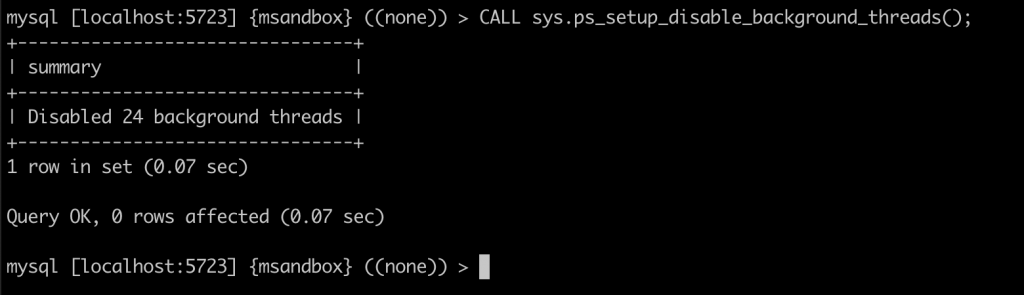
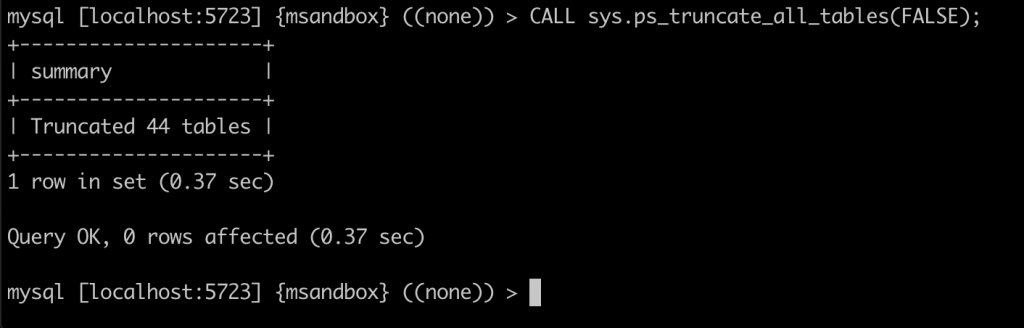
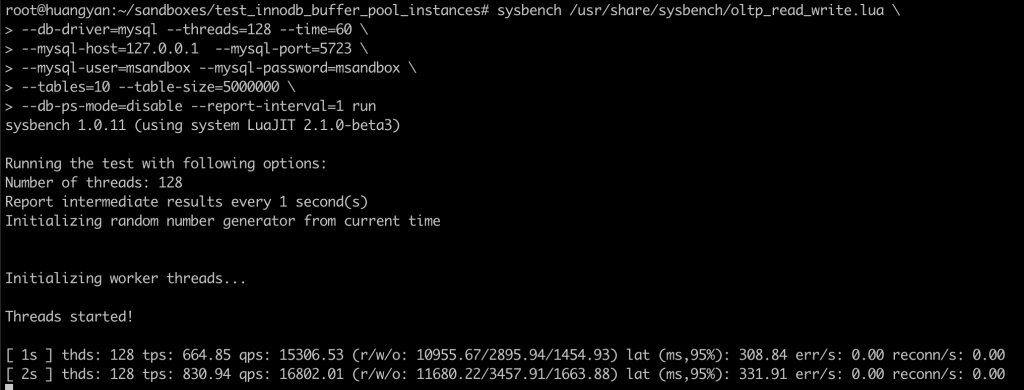
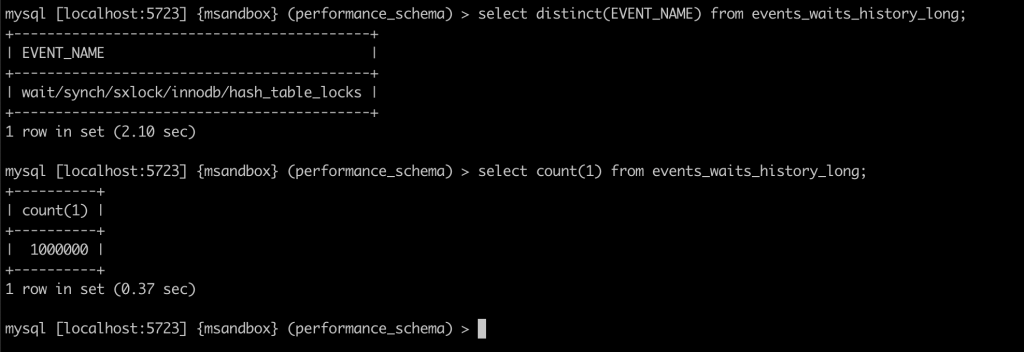
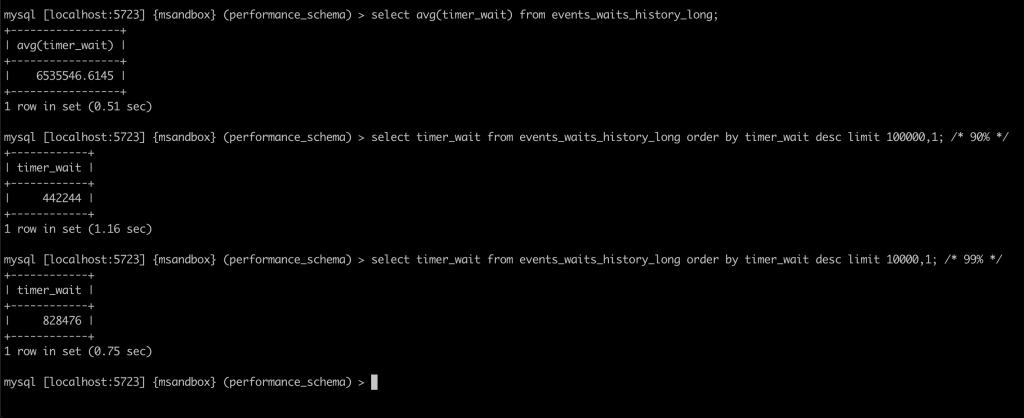
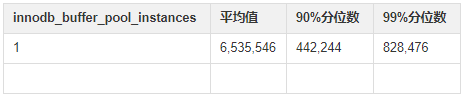
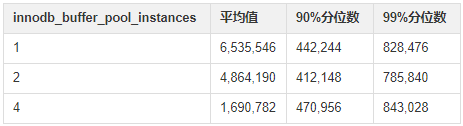
本次实验介绍了对 innodb_buffer_pool_instances 参数对性能影响的观测手法,大家可以在进行压力测试时,使用此方法观察 innodb_buffer_pool_instances 的取值对性能的影响,从而决定应该取值多少。
参数设置一直是个平衡问题,innodb_buffer_pool_instances 设置太小,锁冲突集中;设置太大,维护成本升高。
再次强调,本次实验仅介绍手法,结果不足取信。不同压力,不同 buffer pool 配置,不同环境会呈现效果,唯有手法是可以传承的。
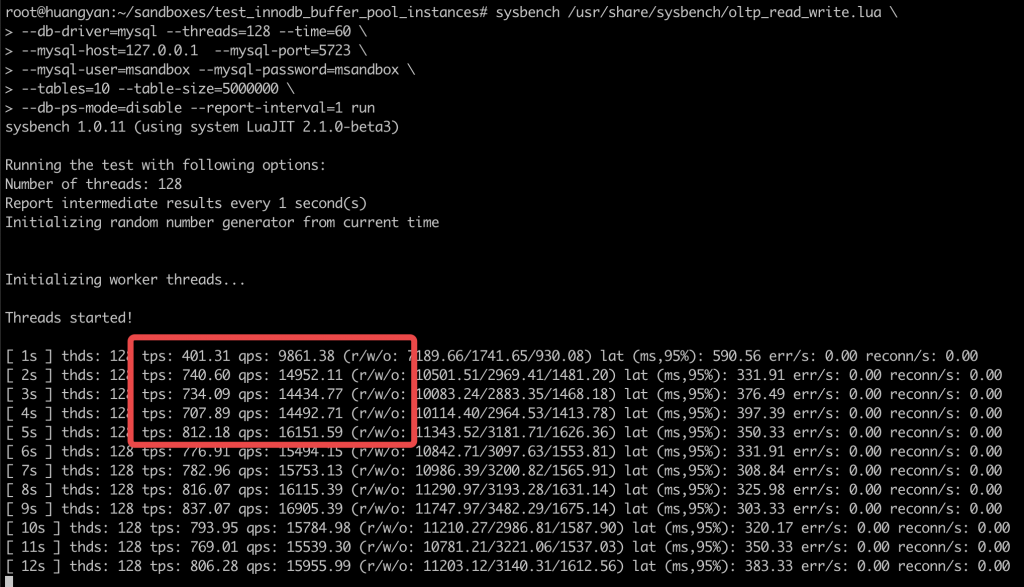
按照正常实验的规则,95% 分位数以上的极值可看作是实验误差,但对于本次实验中的极大值进行进一步分析后,我们认为可以用于说明实验效果。