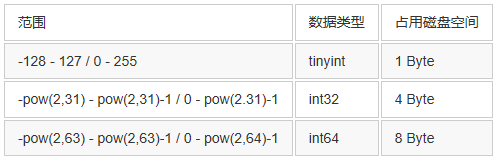
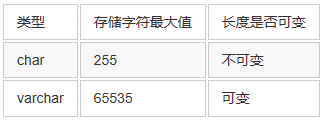
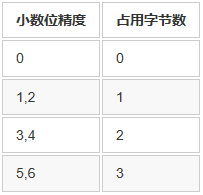
mysql-(ytt/3305)->insert into y1 values (10.2,10.2,10.2);
Query OK, 1 row affected (0.01 sec)
mysql-(ytt/3305)->insert into y1 values (100.12,100.12,100.12);
Query OK, 1 row affected (0.01 sec)
mysql-(ytt/3305)->insert into y1 values (1001.12,1001.12,1001.12);
Query OK, 1 row affected (0.01 sec)
mysql-(ytt/3305)->insert into y1 values (12001.12,12001.12,12001.12);
Query OK, 1 row affected (0.01 sec)
mysql-(ytt/3305)->insert into y1 values (12001222.12,12001222.12,12001222.12);
Query OK, 1 row affected (0.00 sec)