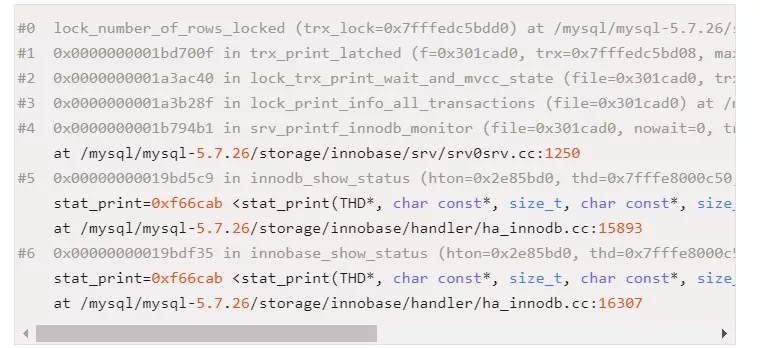
5.6.22
随后我翻了一下 5.6.22 的代码,发现完全不同如下:
for(lock= UT_LIST_GET_FIRST(trx_lock->trx_locks); //使用for循环每个获取的锁结构
lock!= NULL;
lock= UT_LIST_GET_NEXT(trx_locks, lock)) {
if(lock_get_type_low(lock) == LOCK_REC) { //过滤为行锁
ulint n_bit;
ulint n_bits = lock_rec_get_n_bits(lock);
for(n_bit = 0; n_bit < n_bits; n_bit++) {//开始循环每一个锁结构的每一个bit位进行统计
if(lock_rec_get_nth_bit(lock, n_bit)) {
n_records++;
}
}
}
}
return(n_records);
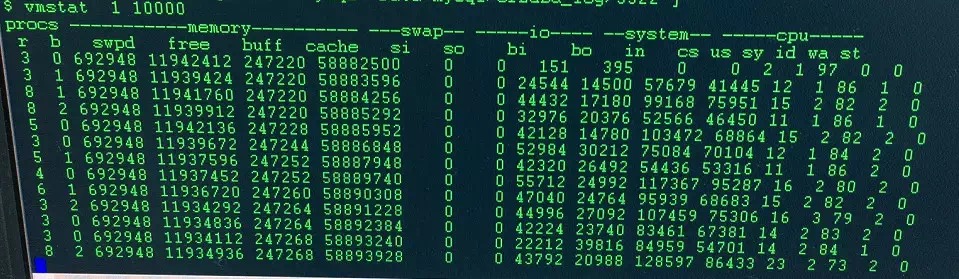
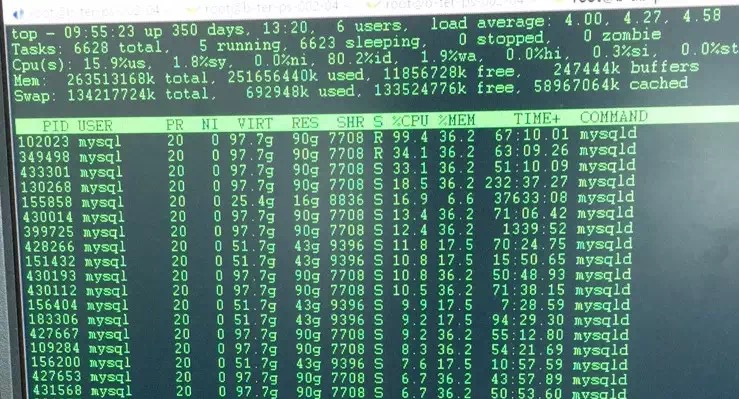
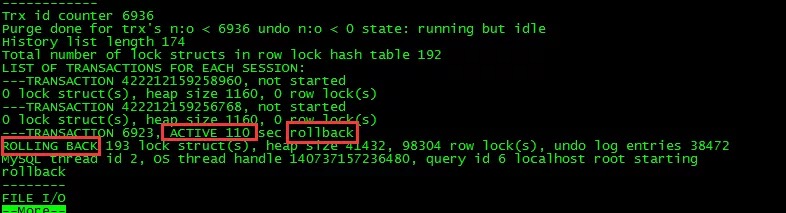
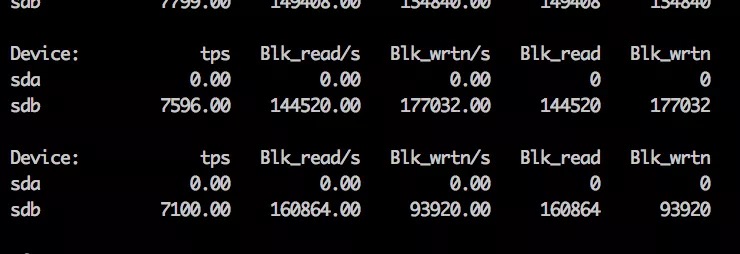
我们知道循环本身是一种 CPU 密集型的操作,这里使用了嵌套循环实现。因此如果在 5.6 中如果出现大事务操作了大量的行,那么获取行锁记录的个数的时候,将会出现高耗 CPU 的情况。