CREATE TABLE `tmp_up` (
`taskname` varchar(500) DEFAULT NULL,
KEY `idx_taskname` (`taskname`));
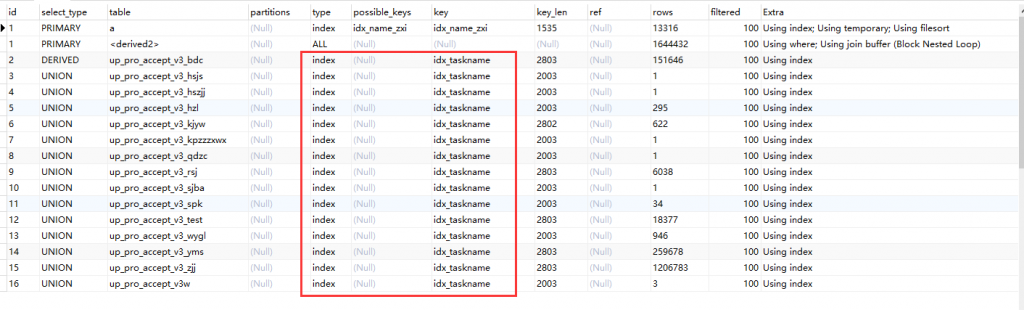
insert into tmp_up
select taskname from up_pro_accept_v3_bdc
union all select taskname up_pro_accept_v3_hsjs
......
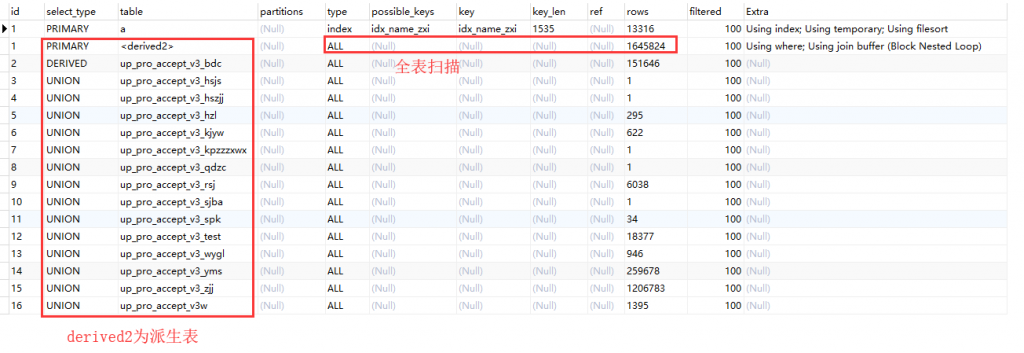
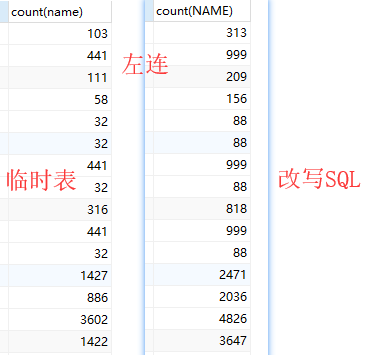
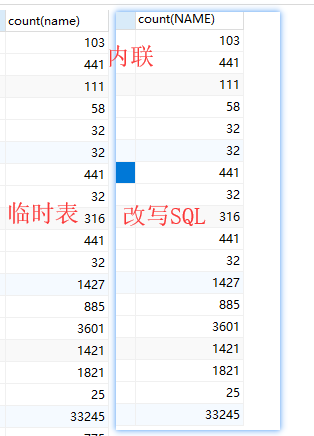
3. 使用临时表代替子查询
select name,count(name) from bm_id a left JOIN
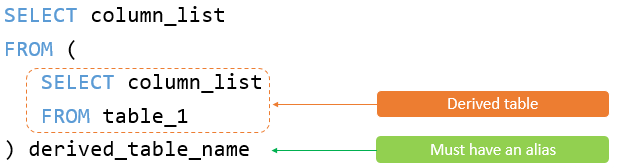
(select TaskName from tmp_up )t
on a.zxi = t.TaskName group by name
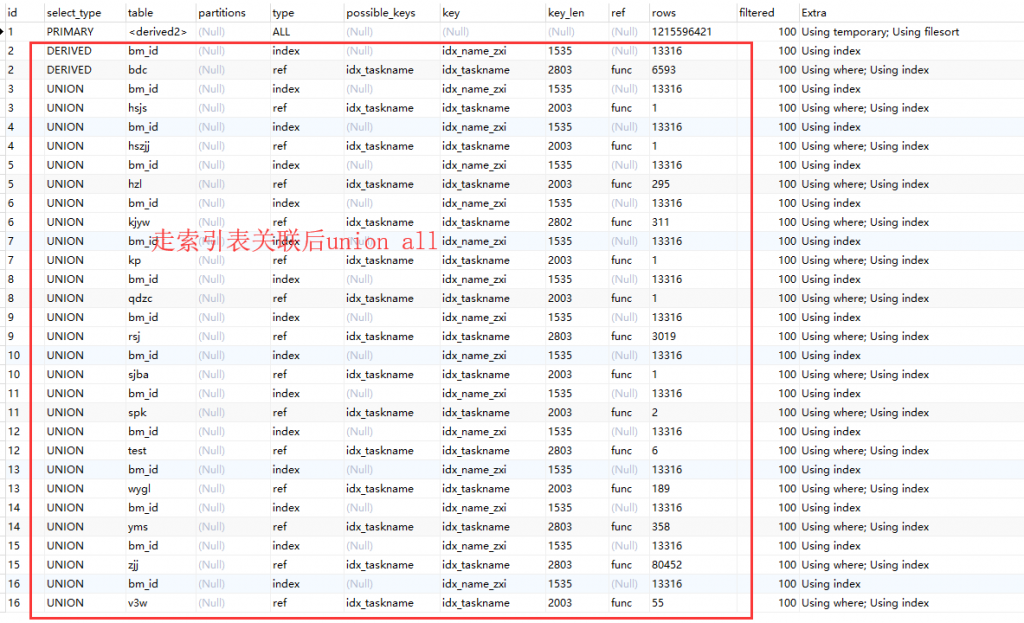
4. 对比下查询结果是否一致
惊讶的发现改写 SQL 的结果集会多出来很多?这里可以确认走临时表的结果集是肯定没问题的,那么问题肯定出在改写 SQL 上!