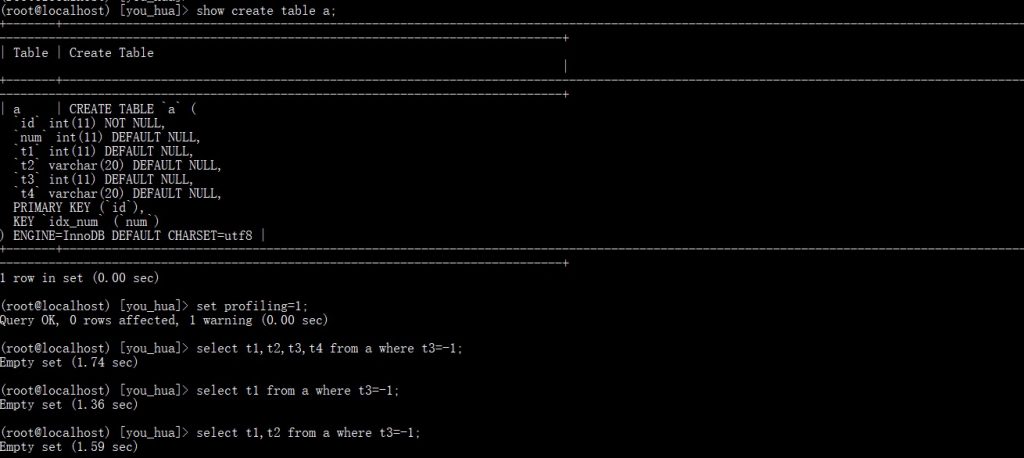
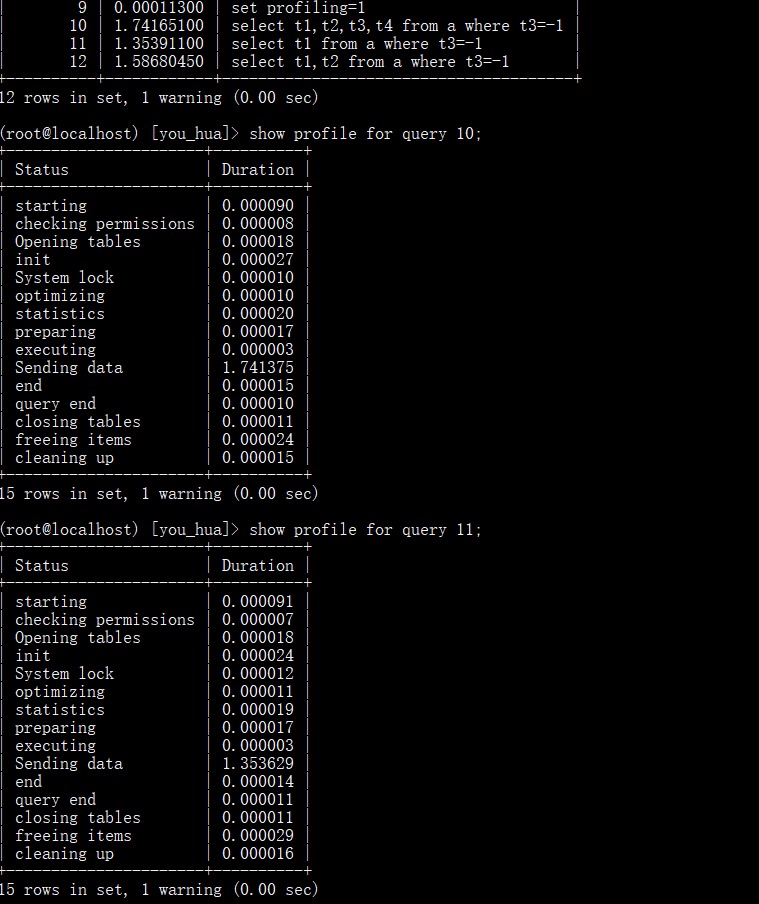
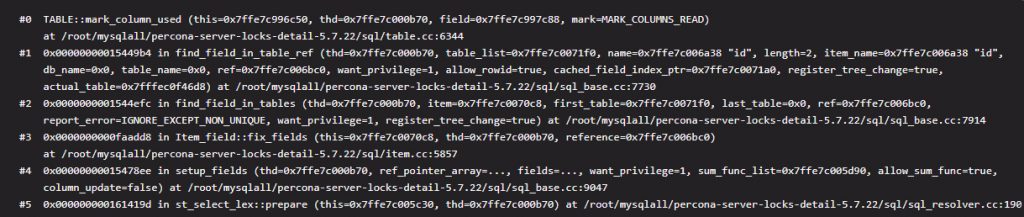
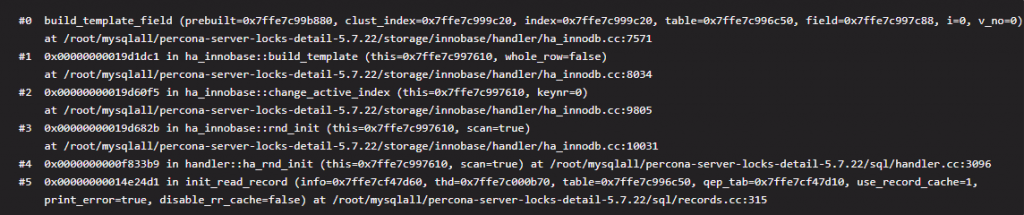
这一步完成后我们可以认为记录已经返回给了 MySQL 层,这里就是实际的数据拷贝了,并不是指针,整个过程放到了函数 row_sel_store_mysql_rec 中。我们前面的模板(mysql_row_templ_t)也会在这里发挥它的作用,这是一个字段过滤的过程,我们先来看一个循环。for (i = 0; i < prebuilt->ntemplate; i++)
其中 prebuilt->n_template 就是字段模板的个数,我们前面已经说过了,通过 read_set 的过滤,对于我们不需要的字段是不会建立模板的。因此这里的模板数量是和我们访问的字段个数一样的。
然后在这个循环下面会调用 row_sel_store_mysql_field_func 然后调用 row_sel_field_store_in_mysql_format_func 将字段一个一个转换为 MySQL 的格式。我们来看一下其中一种类型的转换如下:case DATA_INT:
/* Convert integer data from Innobase to a little-endian
format, sign bit restored to normal */
ptr = dest + len;
for (;;) {
ptr--;
*ptr = *data;//值拷贝 内存拷贝
if (ptr == dest) {
break;
}
data++;
}
我们可以发现这是一种实际的转换,也就是需要花费内存空间的。栈帧见结尾栈帧 4。到这里我们大概知道了,查询的字段越多那么这里转换的过程越长,并且这里都是实际的内存拷贝,而非指针指向。最终这行数据会存储到 row_search_mvcc 的形参 buffer 中返回给 MySQL 层,这个形参的注释如下:@param[out] buf buffer for the fetched row in MySQL format